编译| 周鹏 本文介绍由哈佛大学计算机科学系Rayan Krishnan 等人发表在 Nature biomedical engineering 上的一篇综述《Self-supervised learning in medicine and healthcare》。常规的深度学习模型需要大量标注的数据作为训练集,例如计算机视觉常用的数据集 ImageNet 包含了 21,000 类 1600 万张图片。然而对于医疗数据来说,想要获取这样规模的标注数据是非常困难的。一方面,标注医疗图像需要拥有专业的医疗知识;另一方面,不同于普通物体,我们一眼就可以分辨,医疗图像往往需要医学专家花费数分钟进行确认。因此,如何利用大量的无标签数据对于 AI 医疗的发展至关重要。自监督学习通过构建一系列的自监督任务来进行预训练,使得模型可以提取到更有用的特征,然后在有标签的数据集中进行进一步训练,使得模型在标注数据较少的条件下也能获得较好的泛化能力。文章展望了自监督学习应用于AI医疗的发展趋势,并介绍了两类近年来被广泛研究的用于 AI 医疗的自监督的预训练方法:对比学习和生成学习。

未来的发展
**1、多模态数据可以得到充分利用,从而得到效力更好的模型。**例如:同一病例的 X 光图像和放射透视报告可以形成正样本对;视网膜眼底图像和视网膜厚度值可以形成正样本对。通过自监督学习,来自不同医学测试的多维度数据可以更好地融合进而提高模型效果。
未来的医疗模型可能会有两个发展趋势:第一,更多地使用多模态数据。例如,患者的常规体测数据如年龄、体重、血压等可以与心电图融合在一起训练,这两类数据提供了不同的诊断支撑。第二,未来的模型可能会在预训练阶段引入更加广泛的医疗测试数据,使得模型可以“理解”潜在的疾病。某些非常规的医学测试数据是非常稀缺的,例如视网膜厚度测量数据,使用这类数据进行医疗预测就变得十分困难。在预训练中引入大量的、广泛的医学测试数据,或许可以使模型“理解”各类数据和疾病之间的潜在关系,使得模型在有限测试数据的条件下表现得更好。
**2、自监督学习将会越来越多地应用到医学领域地其它任务上。**例如:利用有限的标注数据按疾病的严重程度对病患进行分组,从而更好地分配医疗资源和进行针对性的治疗;预测病患对特定治疗手段的接受程度,从而优化治疗方案。另外,针对于患者个体的模型目前很少被研究,这类模型或许也将得到发展,从而可以为患者定制个性化的医疗保健方案。
**3、自监督学习可能会用到时序多模态数据上。**例如:病患不同时间段的医疗测试数据可以帮助模型理解疾病的各种变化;各种智能穿戴设备提供了大量有时序的体质检测数据,这些数据可以为医疗保健提供数据支撑。这类多模态数据提供了更加全面完整的医疗信息,使模型可以获得更加可靠的预测。
**4、现在的模型都是基于已经收集好的数据,这些数据往往存在偏置(bias)。**训练在偏置数据(biased data)上的模型往往是具有某种偏好的,这种偏好可能呈现出对某些药物的过度依赖甚至对特定人群的歧视。因此,未来需要有更好的方法和措施来收集大规模的、高质量的非偏置数据。例如,可以优化工作流程,使得医生可以在为患者诊断的过程中标注数据,而不是在诊断完成之后进行标注;可以在工作流程中按照自监督任务对数据进行标注;可以针对不同的人群训练不同的模型从而消除模型对人群的偏好。
两种预训练方法
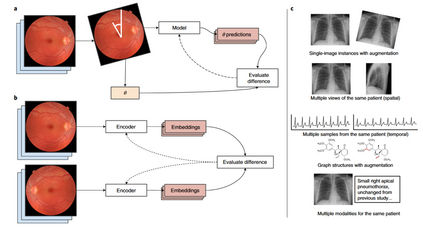
对比学习 对比学习的核心思想是构建正负样本对,正样本代表两个样本属于同一个类别,负样本对表示两个样本属于不同类别。第一,构建正负样本对的方法有很多种。例如:图1-c从上往下依次展示了5种方法构建正样本对,分别是旋转图像、同一部位的不同角度的图像、不同时刻的心电图、拥有类似图结构的分子和多模态数据(X片和其文字描述)。第二,正负样本对有很多种用法。例如:图1-a中,输入 是一张眼底视网膜图像,将原图旋转 度之后得到一个新的图 ,将这图 输入到模型中预测其与原图的角度;图1-b中,将原图 旋转180度得到新的图 ,将这两张图分别输入到两个不同的编码器中得到两张图的 embeddings,拉近这两个 embeddings 之间的距离。
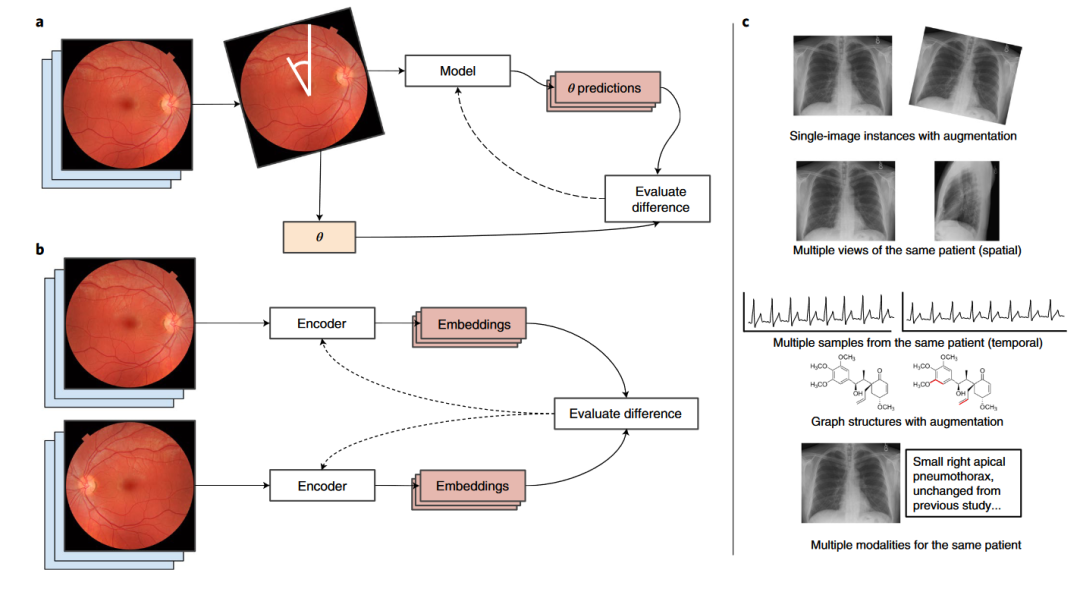
图1
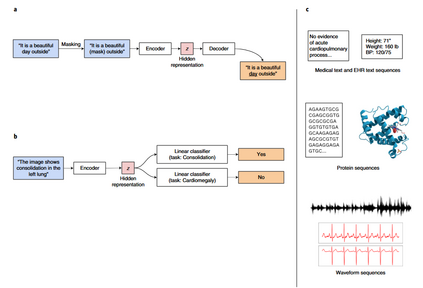
生成学习 生成式预训练方法在自然语言处理方向得到了广泛的应用。这类方法的核心思想是遮盖住样本的一部分数据,然后用这个样本的其余部分对缺失的数据进行预测。例如,图2-a中,句子“It is a beautiful day outside”中的“day”被遮住,然后对这个句子进行编码得到一个隐藏特征,最后把隐藏特征输入到一个解码器希望可以还原出原始的句子。通过这种预训练方式得到的编码器可以处理一些特定的医疗任务,例如在图2-b,利用训练好的编码器,模型可以从文字描述获得诊断信息。图2-c展示了近年来已经用于生成式预训练模型的几种医疗数据,从上往下分别是:医学文字描述和电子病历、蛋白质序列、波形序列。这几类数据都可以非常直观地使用遮罩地思想进行预训练。
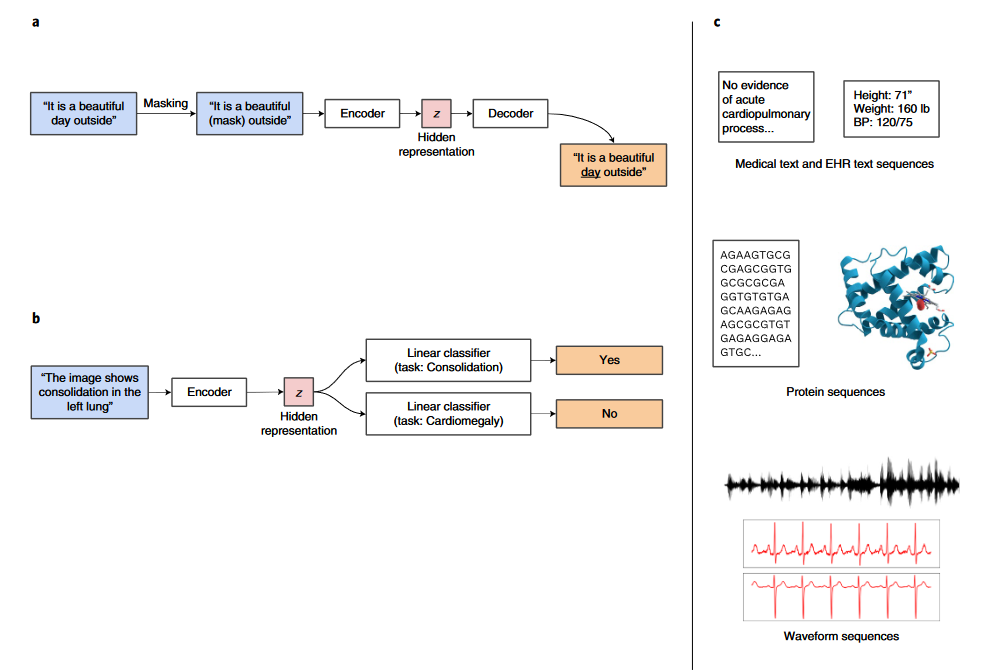
图2
总结
利用大量无标签数据进行预训练可以显著提高机器学习模型的表现能力,尤其对于医学数据来说,获得大量的标注数据十分困难,自监督方法在AI医疗上拥有广阔的应用前景。未来在更多AI医疗的场景上,利用自监督学习融合多模态数据来提高模型质量会是一个重要的研究方向。此外,新的数据收集的流程和方法或许也将会被提出。
参考资料 Krishnan, Rayan, Pranav Rajpurkar, and Eric J. Topol. "Self-supervised learning in medicine and healthcare." Nature Biomedical Engineering (2022): https://www.nature.com/articles/s41551-022-00914-1