

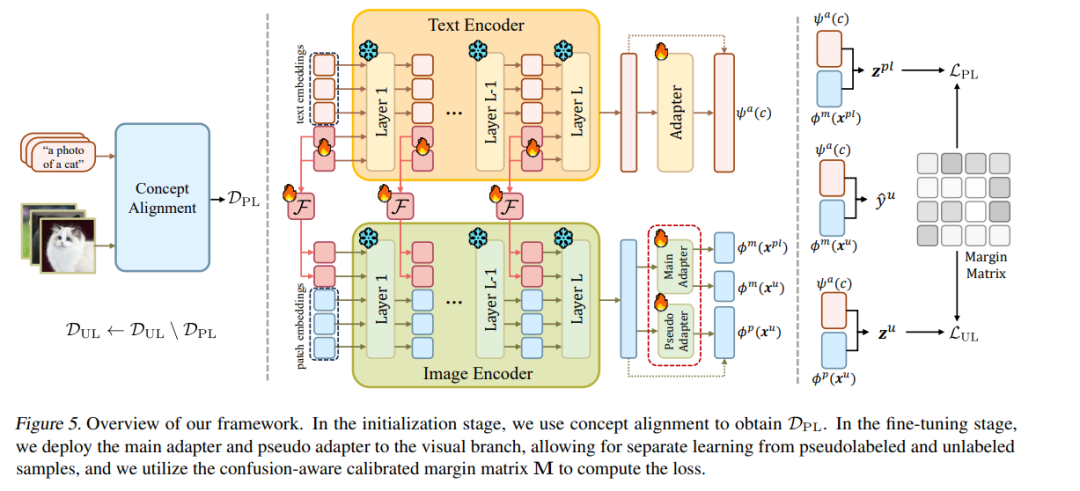
近年来,利用伪标签将视觉-语言模型(VLMs)适配至下游任务,逐渐引起了广泛关注。然而,VLMs 所生成的伪标签通常存在类别不平衡问题,进而导致模型性能下降。尽管现有方法已尝试采用多种策略缓解这一问题,但对其根本原因的研究仍显不足。为填补这一空白,本文深入探讨伪标签不平衡现象,并识别出两大关键诱因:概念不匹配与 概念混淆。 为缓解这两个问题,我们提出了一个新颖的框架,结合了概念对齐机制与混淆感知校准边界机制。该方法的核心在于增强表现较差的类别,并推动模型在各类别间实现更加平衡的预测,从而有效缓解伪标签的不平衡问题。 我们在六个基准数据集、三种学习范式上进行了大量实证实验,结果表明,所提方法在伪标签的准确性与平衡性方面均实现了显著提升,相较当前最先进方法取得了 6.29% 的相对性能提升。 我们的代码已开源,详见: https://anonymous.4open.science/r/CAP-C642/
成为VIP会员查看完整内容
相关内容
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
141+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
38+阅读 · 2023年4月19日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
141+阅读 · 2023年3月29日