摘要:
智能体化强化学习(Agentic RL)的出现标志着与传统应用于大语言模型(LLM RL)的强化学习之间的范式转变,将LLM从被动的序列生成器重新定义为嵌入复杂、动态世界中的自主决策智能体。本综述通过对比LLM-RL的退化单步马尔可夫决策过程(MDP)与智能体化RL所依赖的部分可观测、时间扩展的部分可观测马尔可夫决策过程(POMDP),形式化地阐释了这一概念转变。在此基础上,我们提出了一个全面的双重分类体系:其一围绕核心智能体化能力进行组织,包括规划、工具使用、记忆、推理、自我改进与感知;其二则围绕这些能力在多样化任务领域中的应用展开。我们论点的核心在于,强化学习是将这些能力从静态的启发式模块转化为自适应、鲁棒的智能体化行为的关键机制。为支持并加速未来研究,我们整合了现有的开源环境、基准和框架,形成了一个实用的参考手册。通过综合分析五百余项最新研究,本综述勾勒出这一快速发展的领域轮廓,并强调了塑造可扩展通用人工智能体发展的机遇与挑战。
关键词: 智能体化强化学习,大语言模型,LLM智能体

1. 引言
大语言模型(LLMs)与强化学习(RL)的快速融合,正在根本性地改变人们对语言模型的理解、训练与部署方式。早期的LLM-RL范式通常将模型视为静态的条件生成器,其优化目标是生成与人类偏好或基准测试分数相符的单轮输出。尽管这一方法在对齐(alignment)和指令跟随任务中取得了成功,但它忽视了现实交互场景中更广泛的序列决策问题。这一局限性推动了视角转变:近期发展越来越多地将LLMs视为智能体化实体,即具备感知、推理、规划、调用工具、维护记忆以及在部分可观测动态环境中跨时间跨度自适应调整策略的自主决策者。我们将这一新兴范式定义为智能体化强化学习(Agentic RL)。 为了更清晰地区分本研究所探讨的智能体化RL与传统RL方法,我们提出如下定义: 智能体化强化学习(Agentic RL)指的是一种范式,其中LLMs不再被视为仅针对单轮输出对齐或基准性能而优化的静态条件生成器,而是被建模为嵌入于序列决策循环中的可学习策略。RL赋予其自主的智能体化能力,包括规划、推理、工具使用、记忆维护与自我反思,从而使其能够在部分可观测、动态环境中展现出长时程的认知与交互行为。 在第2节中,我们将通过更形式化的符号抽象,基于马尔可夫决策过程(MDP)和部分可观测马尔可夫决策过程(POMDP),阐明智能体化RL与传统RL的区别。与智能体化RL相关的既有研究大致可以分为两个互补的方向:LLM智能体与LLM的强化学习,具体如下: * LLM智能体:基于LLM的智能体是一种新兴范式,其中LLMs作为自主或半自主的决策实体 [1, 2],具备推理、规划与执行行动以达成复杂目标的能力。已有综述从互补的视角对其进行了梳理:Luo 等 [3] 提出了以方法论为中心的分类体系,涵盖体系结构基础、协作机制与演化路径;而 Plaat 等 [4] 则强调推理、行动与交互作为智能体化LLMs的核心能力。工具使用(包括检索增强生成 RAG 与 API 调用)是其中的重要范式,Li 等 [5] 与 Wang 等 [6] 进行了深入探讨。规划与推理策略是另一支柱,Masterman 等 [7] 总结了常见的“规划—执行—反思”循环模式,Tao 等 [8] 则扩展到自我进化,使智能体能够在较少人工干预的情况下迭代优化知识与策略。其他研究方向包括协作式、跨模态和具身场景,如多智能体系统 [9]、多模态集成 [10],以及结合记忆与感知的类脑架构 [11]。
LLM的强化学习:另一条研究路径探讨了如何通过强化学习算法提升或对齐LLMs。代表性方法包括基于on-policy的算法(如近端策略优化 PPO [12]、群体相对策略优化 GRPO [13])和基于off-policy的算法(如 actor–critic、Q-learning [14]),以增强其在指令跟随、伦理对齐与代码生成等方面的能力 [15, 16, 17]。互补方向为LLM用于RL,即将LLMs部署为规划器、奖励设计器、目标生成器或信息处理器,以提升样本效率、泛化能力和多任务规划能力,Cao 等 [18] 提供了系统化的分类。RL也已被融入LLM生命周期的各个阶段:从数据生成 [19, 20]、预训练 [21] 到后训练与推理 [22],Guo 等 [23] 对此进行了综述。其中最突出的一支是后训练对齐,尤其是基于人类反馈的强化学习(RLHF)[24],以及其扩展方法,如基于AI反馈的强化学习(RLAIF)、直接偏好优化(DPO)[25, 26, 27, 15]。
研究缺口与贡献。 当前关于LLM智能体与RL增强LLMs的研究浪潮反映了两种互补视角:一方面探索LLMs作为自主智能体核心所能完成的任务,另一方面研究如何通过RL优化其行为。然而,尽管相关工作已经相当广泛,但针对智能体化RL这一统一框架(即将LLMs建模为嵌入序列决策过程的策略优化智能体)的系统性探讨仍然缺乏。现有研究往往聚焦于孤立的能力、领域或定制化环境,术语与评估协议不统一,使得系统对比与跨领域泛化存在困难。
为弥补这一缺口,我们提出了一种连贯的综合视角,将理论基础与算法方法及实际系统相衔接。我们基于MDP与POMDP抽象形式化地界定智能体化RL与传统LLM-RL的区别,并提出以能力为中心的分类体系,其中包括规划、工具使用、记忆、推理、自我改进(反思)与交互等可由RL优化的组件。此外,我们还整合了代表性的任务、环境、框架与基准,以支持智能体化LLMs的训练与评估,并在最后讨论开放挑战,展望可扩展的通用智能体化智能的未来研究方向。 综上,本综述的研究范围可进一步明确如下:
主要关注点:✔ 探讨RL如何赋能于LLM智能体(或具备智能体化特征的LLMs),使其能在动态环境中发挥作用。 * 不在范围之内(但偶有提及):✗ 基于RL的人类价值对齐(如有害查询拒绝);✗ 非LLM的传统RL算法(如多智能体强化学习 MARL [28]);✗ 提升纯LLM在静态基准上的性能的RL方法。
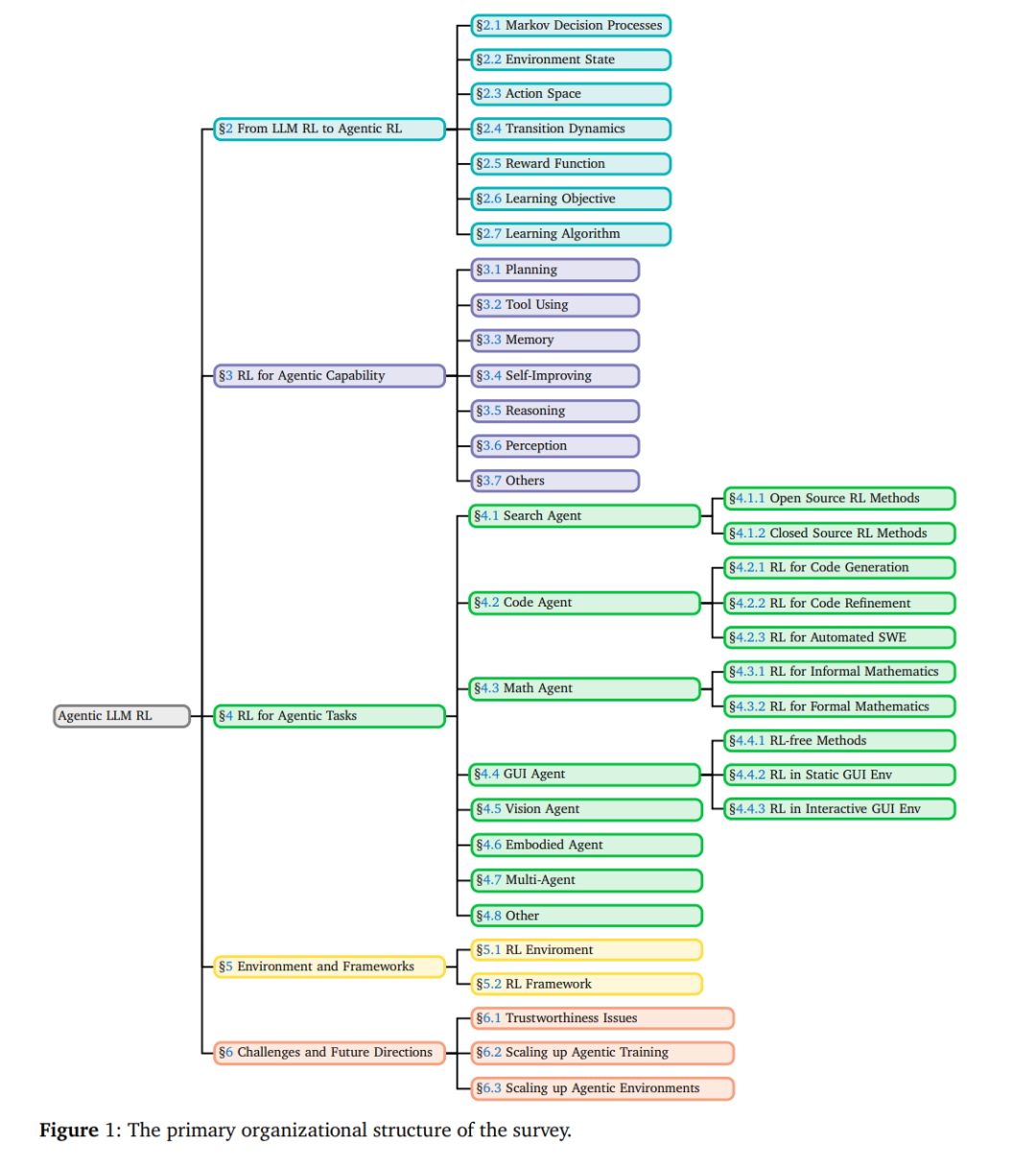
综述结构。 本文的组织方式旨在从概念基础逐步推进到实际实现,构建统一的智能体化RL理解框架:第2节通过MDP/POMDP视角形式化这一范式转变;第3节从能力角度审视智能体化RL,对规划、推理、工具使用、记忆、自我改进、感知等关键模块进行分类;第4节探讨其跨领域应用,包括搜索、GUI导航、代码生成、数学推理与多智能体系统;第5节整合支撑实验与评测的开源环境与RL框架;第6节讨论开放挑战与未来方向,聚焦可扩展、自适应且可靠的智能体化智能;第7节总结全文。整体结构如图1所示。
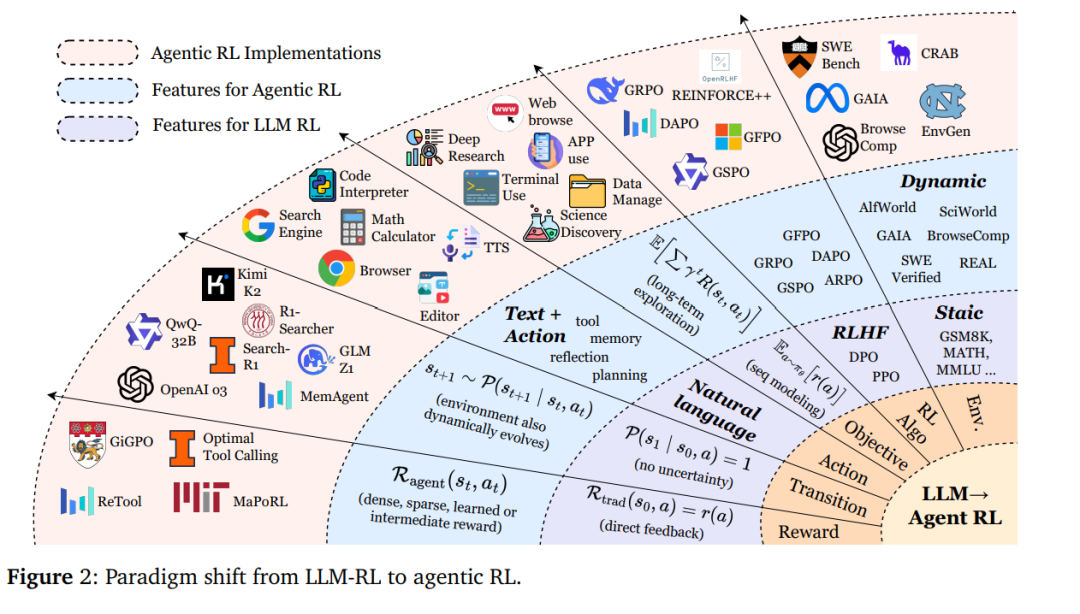
大语言模型(LLMs)最初通过行为克隆(behavior cloning)进行预训练,即在静态数据集(如网页抓取的文本语料)上采用最大似然估计(MLE)。随后的一系列后训练方法(post-training)增强了模型能力,并使其输出与人类偏好保持一致,从而使模型超越了单纯的网络数据复制器。常见的方法是监督微调(SFT),即在人工生成的(提示,响应)示例上对模型进行再训练。然而,获取足够高质量的SFT数据仍然面临挑战。强化微调(RFT)提供了一种替代方案,它通过奖励函数优化模型,避免了对行为示范数据的依赖。 在早期的RFT研究中,核心目标是通过人类反馈 [24] 或 数据偏好 [29] 来优化LLMs,使其对齐于人类偏好,或直接对齐于数据偏好(如DPO)。这种基于偏好的强化微调(PBRFT)主要包括:在固定的偏好数据集上训练奖励模型并优化LLMs,或直接利用数据偏好进行优化。随着具备推理能力的LLMs(如 OpenAI o1 [30] 和 DeepSeek-R1 [31])的发布,其性能提升与跨领域泛化能力引发了广泛关注。而随着 OpenAI o3 [32] 等模型的出现——这些模型不仅具备自进化的推理能力,还支持工具使用——研究者开始思考如何通过强化学习方法将LLMs与下游任务进行深度融合。 因此,研究焦点逐渐从旨在优化固定偏好数据集的PBRFT,转向针对特定任务与动态环境的智能体化强化学习(Agentic RL)。 在本节中,我们将形式化阐释从PBRFT到新兴的智能体化强化学习(Agentic RL)框架的范式转变。尽管这两种方法都利用了RL技术来提升LLMs的性能,但它们在基本假设、任务结构与决策粒度上存在根本差异。图[33]展示了从LLM-RL到智能体化RL的范式转变。