深度学习的下一步:Transformer和注意力机制
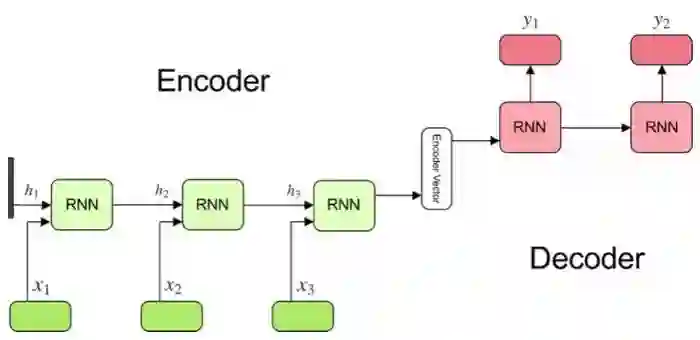
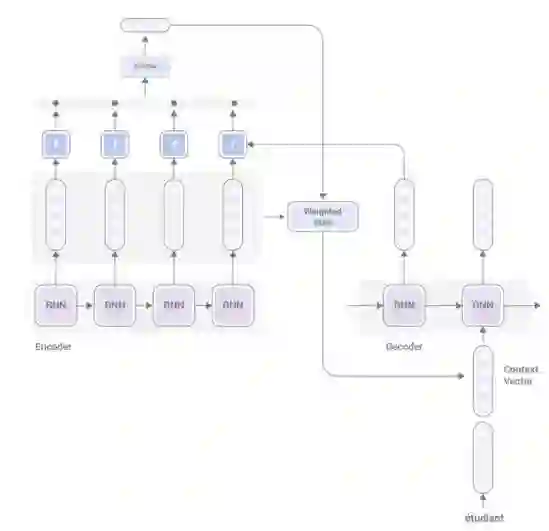 RNN中的注意力机制
RNN中的注意力机制
全局注意力:使用编码器中的所有隐状态来计算上下文向量。这从计算资源上来说开销很大,因为要针对每个目标单词考虑来自源句子的所有单词。
局部注意力:选择源句子中的位置来确定要考虑的单词窗口。
双向注意力:同一个模型处理假设和前提,两个表示都是级联的。然而,该模型无法区别停用单词之间的对齐不如内容单词之间的对齐来得重要。
自注意力:这种机制关联单单一个序列的不同位置,以计算其内部表示。
键值注意力:输出向量被分成键以计算注意力和值,从而编码下一个单词分布和上下文表示。
分层嵌套注意力:两个注意力级别:第一个是单词级别,第二个是句子级别。这突出了文档中信息量大的部分。


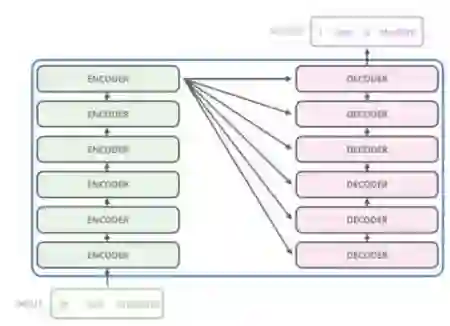
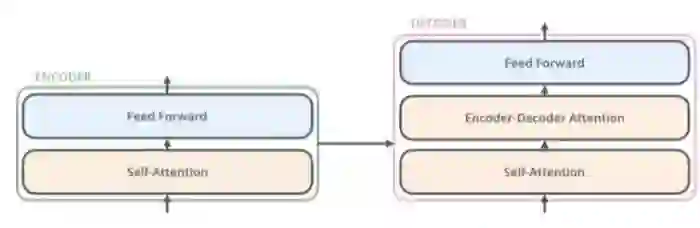

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文