
来自天津大学《大型语言模型评估》综述,为大型语言模型的评估方法提供广泛的探讨

大型语言模型(LLMs)在广泛的任务范围内展现了显著的能力。它们引起了大量的关注,并已被部署在众多下游应用中。然而,如同一把双刃剑,LLMs也带来了潜在的风险。它们可能面临私人数据泄露的风险,或产生不适当、有害或误导性的内容。此外,LLMs的快速进步也引发了关于在没有充分保障的情况下可能出现的超智能系统的担忧。为了有效地利用LLMs的能力并确保它们的安全和有益的发展,对LLMs进行严格和全面的评估至关重要。这项综述旨在为LLMs的评估提供一个全景式的视角。我们将LLMs的评估分为三大类:知识和能力评估、对齐评估和安全评估。除了对这三个方面的评估方法和基准的全面调研外,我们还汇编了一个关于LLMs在专业领域性能的评估手册,并讨论了建立综合评估平台的构建,该平台涵盖了LLMs在能力、对齐、安全和适用性上的评估。我们希望这个全面的概述能够进一步激发对LLMs评估的研究兴趣,最终目标是使评估成为指导LLMs负责任发展的基石。我们设想,这将引导它们的发展朝着最大化社会利益同时最小化潜在风险的方向。与此相关的论文列表已在GitHub仓库上公开。
当我们深入探讨智能的概念时,人类智能自然成为我们的基准。几千年来,人类一直在不断地探索人类智能,采用多种方法进行测量和评估。对于理解智能的这一追求,包括了从智商测试和认知游戏到教育追求和职业成就的一系列方法。纵观历史,我们持续不断的努力都是为了理解、评估和推动人类智能的各个方面的界限。
然而,在信息时代的背景下,一种新的智能维度正在崭露头角,引发了科学家和研究者的广泛关注:机器智能。这个新兴领域的代表之一是自然语言处理(NLP)中的语言模型。这些通常使用强大的深度神经网络构建的语言模型,具有前所未有的语言理解和生成能力。如何衡量和评估这种新型智能的水平已成为一个关键问题。
在NLP的初级阶段,研究者们通常采用一套简单的基准测试来评估他们的语言模型。这些初步的评估主要集中在诸如语法和词汇之类的方面,包括句法解析、词义消歧等任务。在1990年代初,MUC评估(Grishman&Sundheim,1996)的出现在NLP社区中标志着一个重要的里程碑。MUC评估主要集中于信息提取任务,挑战参与者从文本中提取特定信息。这个评估框架在推动信息提取领域的发展中起到了关键的作用。随后,随着2010年代深度学习的出现,NLP社区采用了更广泛的基准测试,如SNLI(Bowman等人,2015)和SQuAD(Rajpurkar等人,2016)。这些基准不仅评估系统性能,还为训练系统提供了大量数据。它们通常根据采用的评估指标为模型分配个别分数,以方便测量任务特定的准确性。
随着BERT(Devlin等人,2019)等大规模预训练语言模型的出现,评估方法已逐渐发展以适应这些新型通用模型的性能评估。为了应对这种范式转变,NLP社区主动组织了许多共享任务和挑战,包括但不限于SemEval(Nakov等人,2019)、CoNLL(Sang&Meulder,2003)、GLUE(Wang等人,2019b)、SuperGLUE(Wang等人,2019a)和XNLI(Conneau等人,2018)。这些努力需要为每个模型聚合分数,为其整体性能提供一个整体的衡量。反过来,它们推动了NLP评估方法的持续完善,为研究者提供了一个动态的舞台来比较和对比不同系统的能力。
随着语言模型规模的持续扩展,大型语言模型(LLMs)在零样本和少样本环境下都表现出了引人注目的性能,与经过微调的预训练模型相媲美。这一变化引发了评估景观的转变,从传统的任务中心基准转向能力中心评估的关注。不同下游任务之间的划界线已开始变得模糊。与此趋势相伴随的是,旨在评估知识、推理和其他各种能力的评估基准的评估范围也在扩大。许多这些基准都是以放弃训练数据为特点,并设计有提供模型在零样本和少样本设置下的综合评估的总体目标(Hendrycks等人,2021b;Zhong等人,2023;Zhang等人,2023b;Li等人,2023e)。
ChatGPT(OpenAI,2022)鲜明地展示了LLMs被大众迅速采纳,仅在发布后的两个月内,其用户数量就超过了1亿。这一前所未有的增长突显了这些模型的变革能力,包括自然文本生成(Brown等人,2020)、代码生成(Chen等人,2021)和工具使用(Nakano等人,2021)。然而,除了他们的承诺外,人们还对这种能力强大的模型在没有进行彻底和综合评估的情况下大规模部署可能带来的风险提出了担忧。如加剧偏见、传播误信息和妥协隐私等关键问题需要得到严格解决。为了回应这些担忧,研究领域出现了一个专门的研究方向,重点在于实证评估LLMs与人类偏好和价值观的对齐程度。与以往的研究主要关注能力不同,这一研究方向旨在指导LLMs的进步和应用,使其最大限度地发挥其益处,同时积极地减轻风险。
此外,LLMs的日益增多的使用以及它们在现实世界环境中不断增长的整合强调了基于LLMs的先进AI系统和代理对人类社会产生的深远影响。在部署这些先进的AI系统之前,必须优先考虑LLMs的安全性和可靠性。我们为与LLMs相关的一系列安全问题(如鲁棒性和灾难性风险)提供了一个全面的探讨。尽管这些风险可能尚未完全实现并在目前显现,但先进的LLMs已经通过揭示指示灾难性风险的行为和在当前评估中展示执行高阶任务的能力表现出了某些倾向。因此,我们认为,讨论评估这些风险对于指导LLMs安全研究的未来方向至关重要。
尽管已经开发了许多基准来评估LLMs的能力和与人类价值观的一致性,但这些基准通常只集中于单一任务或领域内的表现。为了使LLM的评估更为全面,这份调查提供了一个系统的文献综述,综合了评估这些模型在各种维度上的努力。我们总结了关于一般LLM基准和评估方法的关键点,涵盖知识、推理、工具学习、毒性、真实性、鲁棒性和隐私等方面。
我们的工作显著地扩展了Chang等人(2023)和Liu等人(2023i)最近对LLM评估的两项调查。虽然是同时进行的,但我们的调查与这些现有的评论采取了一个不同的方法。Chang等人(2023)围绕评估任务、数据集和方法结构化他们的分析。与此相反,我们的调查在这些类别之间整合见解,以提供LLM评估中关键进展和局限性的更全面的描述。此外,Liu等人(2023i)主要将他们的评论重点放在LLMs的对齐评估上。我们的调查扩大了范围,综合了LLMs的能力和对齐评估的研究结果。通过从一个整合的视角和扩展的范围来补充这些先前的调查,我们的工作为LLM评估研究的当前状态提供了一个全面的概述。我们的调查与这两项相关工作之间的区别进一步突显了我们的研究对文献的新颖贡献。
分类法与路线图
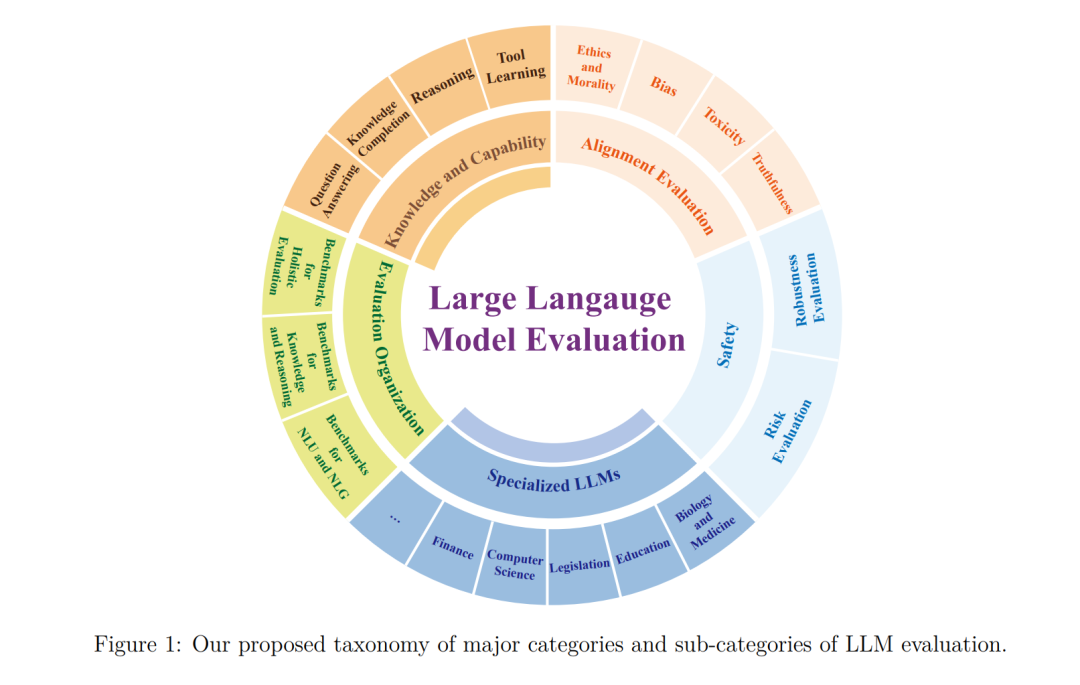
本综述的主要目标是精心分类LLMs的评估,为读者提供一个结构良好的分类框架。通过这个框架,读者可以深入了解LLMs在多个关键领域的表现及其相应的挑战。 众多研究认为,LLMs的能力基石在于知识和推理,这是它们在众多任务中表现出色的基础。尽管如此,有效地应用这些能力需要仔细检查对齐问题,以确保模型的输出与用户的期望保持一致。此外,LLMs容易受到恶意利用或无意的误用,这强调了安全考虑的紧迫性。一旦解决了对齐和安全问题,LLMs就可以在专业领域中审慎部署,催化任务自动化并促进智能决策。因此,我们的总体目标是深入研究这五个基本领域及其各自的子领域的评估,如图1所示。
Section 3: “Knowledge and Capability Evaluation”
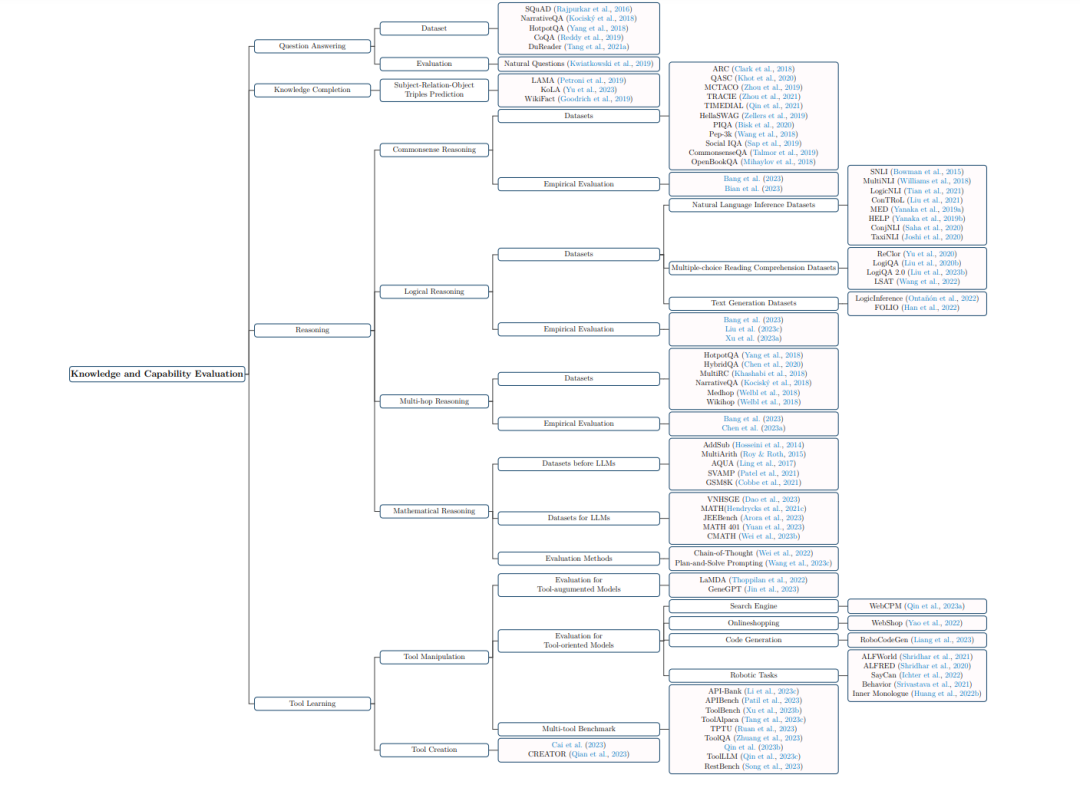
这一部分主要关注于全面评估LLMs所展现出的基本知识和推理能力。这部分详细地分为四个子部分:问答、知识补全、推理和工具学习。问答和知识补全任务是衡量知识实际应用的基本评估,而各种推理任务则是探测LLMs的元推理和复杂推理能力的试金石。此外,还强调了工具学习的特殊能力,并展示了它在使模型熟练处理和生成特定领域内容方面的重要性。
Section 4: “Alignment Evaluation”
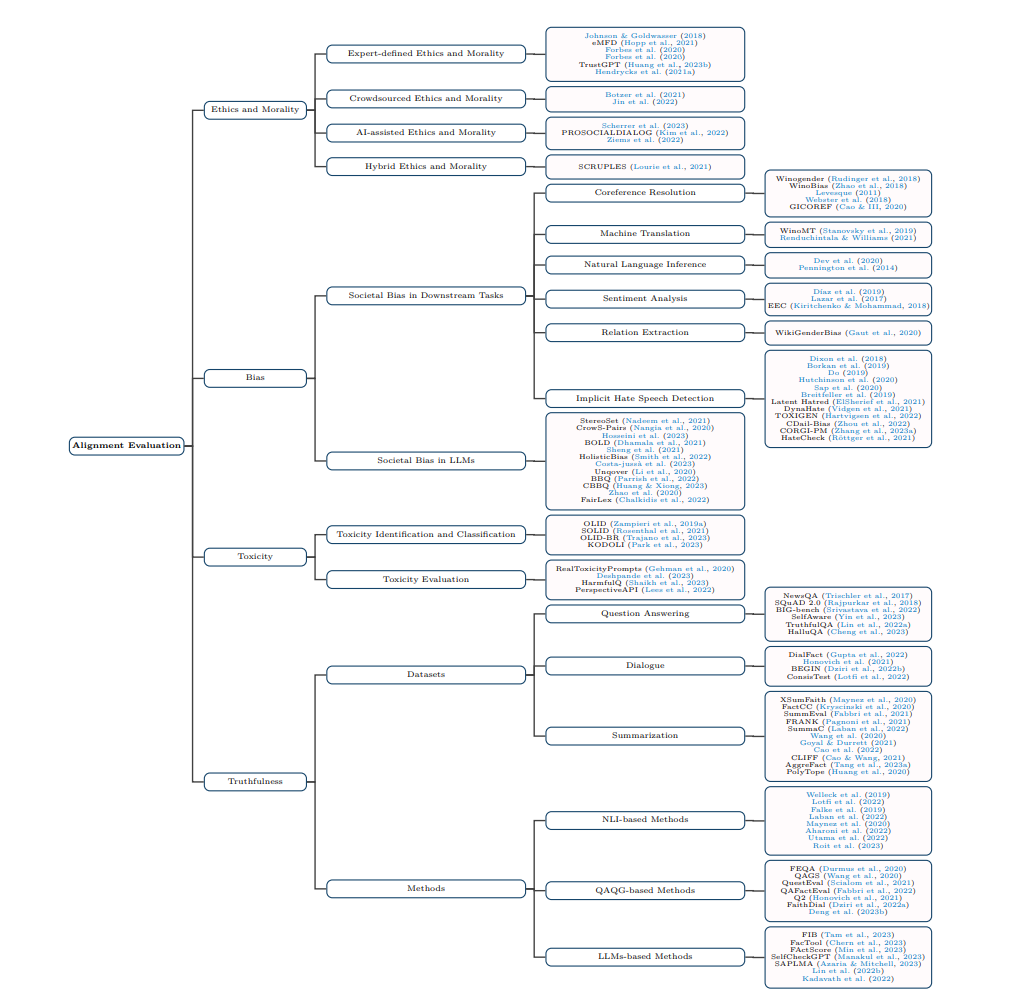
这一部分专注于LLMs在关键维度上的表现,包括伦理考虑、道德含义、偏见检测、毒性评估和真实性评估。这里的主要目的是审查并减少可能出现在伦理、偏见和毒性领域的潜在风险,因为LLMs可能无意中生成歧视、偏见或冒犯的内容。此外,这一部分还提及LLMs中的幻觉现象,这可能导致误传假消息。因此,这个评估的一个不可或缺的方面涉及对真实性的严格评估,强调其作为评估和纠正的基本方面的重要性。
Section 5: “Safety Evaluation”
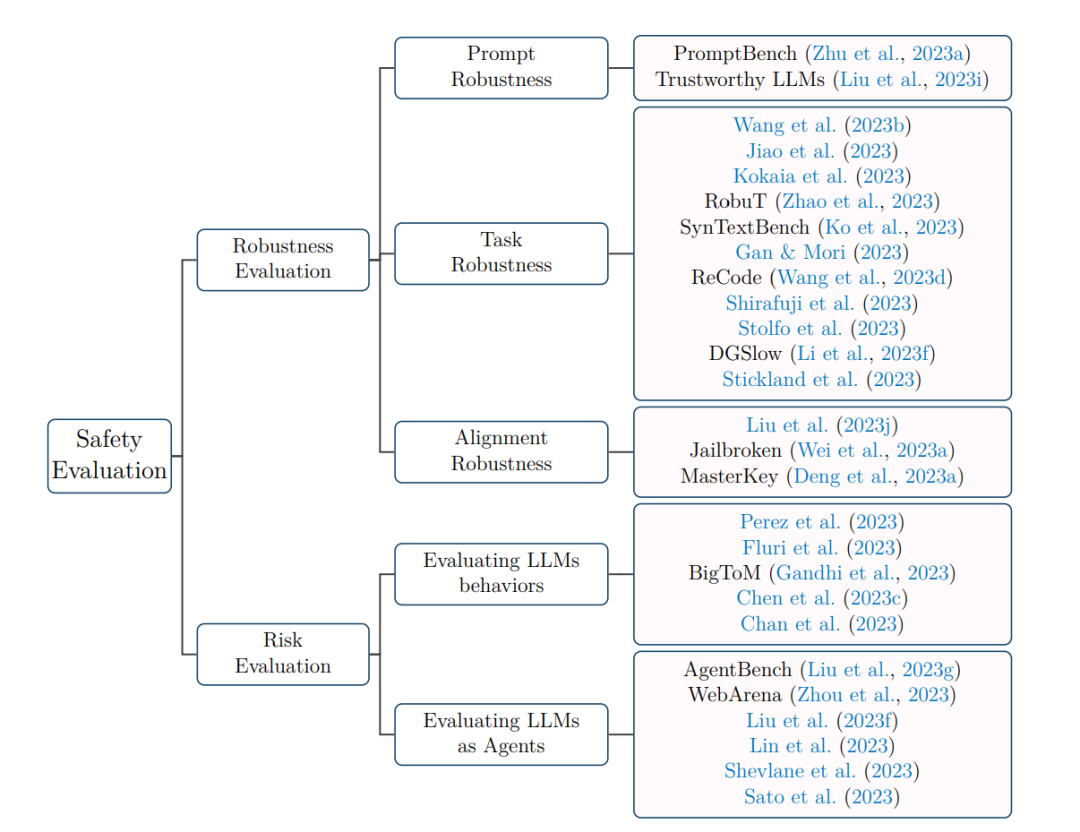
这部分对LLMs的鲁棒性和在人工通用智能(AGI)背景下的评估进行了全面探索。LLMs经常被部署在真实世界的场景中,其中它们的鲁棒性变得至关重要。鲁棒性使它们能够应对来自用户和环境的干扰,同时还可以防范恶意攻击和欺骗,从而确保始终保持高水平的性能。此外,随着LLMs不可避免地向人类水平的能力发展,评估扩大了其视野,包括更深入的安全问题。这些问题包括但不限于寻求权力的行为和发展情境意识,这些因素需要进行详细的评估,以防范未知的挑战。
Section 6: “Specialized LLMs Evaluation”
这部分作为LLMs评估范例在多个专业领域的扩展。在这部分中,我们将关注特别为特定领域应用而定制的LLMs的评估。我们的选择包括目前突出的专业LLMs,涵盖生物学、教育、法律、计算机科学和金融等领域。这里的目标是系统地评估它们在面对领域特定挑战和复杂性时的能力和局限性。
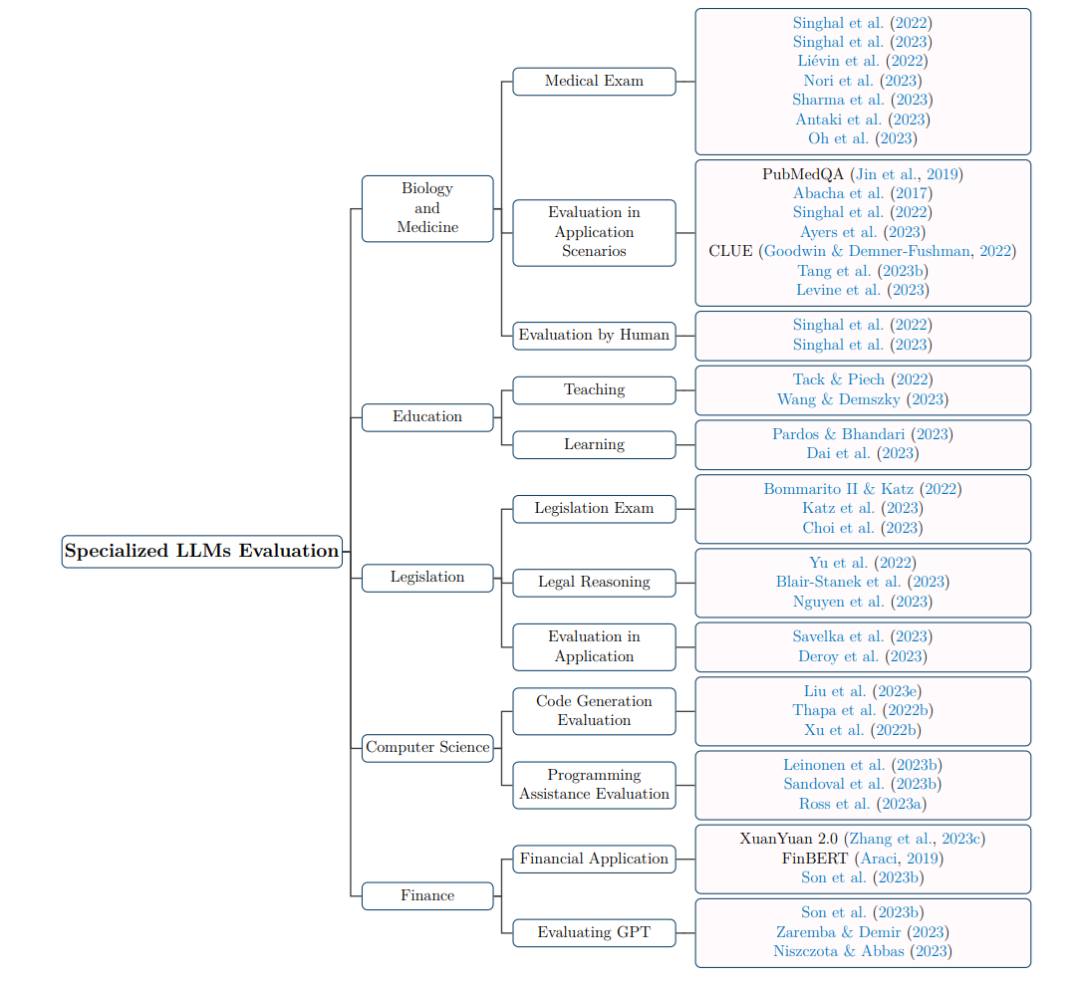
Section 7: “Evaluation Organization”
这部分作为对评估LLMs的常用基准和方法的全面介绍。鉴于LLMs的快速增长,用户面临着识别最合适的模型以满足其特定要求的挑战,同时最大限度地减少评估的范围。在这种背景下,我们提供了一个关于公认和广泛认可的基准评估的概述。这有助于用户在选择适合其特定需求的LLM时做出明智和知情的决策。
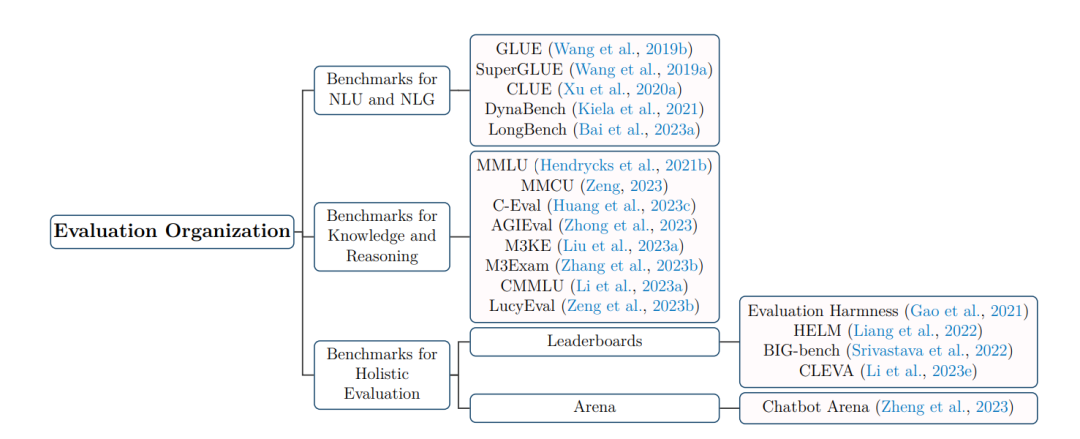
请注意,我们的分类框架并不声称全面涵盖评估领域的所有内容。本质上,我们的目标是回答以下基本问题: • LLMs有哪些能力? • 部署LLMs时必须考虑哪些因素? • LLMs在哪些领域可以找到实际应用? • LLMs在这些不同的领域中的表现如何? 我们现在将开始对LLM评估分类法中的每一类进行深入探讨,依次讨论能力、关注点、应用和性能。
**结论 **
LLMs的发展速度令人震惊,它在许多任务中都展现出了显著的进步。然而,尽管开启了人工智能的新时代,我们对这种新型的智能理解仍然相对有限。界定这些LLMs的能力边界、理解它们在各个领域的性能,并探索如何更有效地发挥它们的潜力是至关重要的。这需要一个全面的基准框架来指导LLMs的发展方向。本次调查系统地阐述了LLMs的核心能力,涵盖了如知识和推理等关键方面。此外,我们深入探讨了对齐评估和安全评估,包括伦理关切、偏见、毒性和真实性,以确保LLMs的安全、可信和伦理应用。同时,我们探讨了LLMs在不同领域的潜在应用,包括生物学、教育、法律、计算机科学和金融。最重要的是,我们提供了一系列受欢迎的基准评估,以帮助研究人员、开发人员和从业者理解和评估LLMs的性能。 我们期望这次调查会推动LLMs评估的发展,为这些模型的受控进步提供明确的指导。这将使LLMs更好地为社区和全球服务,确保它们在各个领域的应用是安全、可靠和有益的。我们怀着热切的期望,拥抱LLMs的发展和评估的未来挑战。

