
摘要
科技的新时代让人们可以方便地在各种平台上分享自己的观点。这些平台为用户提供了多种形式的表达方式,包括文本、图像、视频和音频。然而,这使得用户很难获得关于一个主题的所有关键信息,使得自动多模态摘要(MMS)的任务必不可少。在本文中,我们对MMS领域的现有研究进行了全面的综述。
https://www.zhuanzhi.ai/paper/505f92ea3f81f199063a75af8f594fdf
引言
每天,互联网都充斥着来自多个来源的大量新信息。由于技术的进步,人们现在可以以多种格式共享信息,并使用多种通信模式供他们使用。互联网上日益增多的内容使得用户很难从大量的资源中获取有用的信息,因此有必要研究多模态摘要,与纯文本摘要相比,视觉摘要平均能提高12.4%的用户满意度。事实上,几乎每一个内容共享平台提供陪一个观点或事实以多种媒体形式,和每一个手机都有这个功能的设施表明多式的通讯手段的优越性的缓解在传达和理解信息。
多模态输入形式的信息已被用于除摘要之外的许多任务,包括多模态机器翻译[11,21,22,39,108]、多模态移动预测[18,53,120]、电子商务产品分类[128]、多模态交互式人工智能框架[51]、多模态表情预测[5,17],多模态框架识别[10],多模态金融风险预测[59,101],多模态情感分析[79,93,122],多模态命名身份识别[2,77,78,109,126,130],多模态视频描述生成[37,38,91],多模态产品标题压缩[70]和多模态生物特征认证[28,42,106]。多模态信息处理和检索任务的应用可能性是相当可观的。多通道研究还可用于其他密切相关的研究问题,如图像描述[14,15]、图像到图像的翻译[40]、抗震路面试验[94]、美学评价[55,67,129]和视觉问答[49]。
文本摘要是自然语言处理(NLP)和信息检索(IR)领域最古老的问题之一,由于其具有挑战性和广泛的应用前景,引起了众多研究者的关注。文本摘要的研究可以追溯到六十多年前[69]。NLP和IR社区通过开发无数的技术和模型体系结构来解决针对多个应用的文本摘要研究。作为这个问题的延伸,多模态摘要结的问题增加了另一个角度,结合了视觉和听觉方面的混合,使任务更有挑战性和有趣的处理。将多种模态纳入摘要问题的扩展扩展了问题的广度,导致任务的应用范围更广。近年来,多模态摘要经历了许多新的发展(参见图1关于MMS趋势的统计),包括新数据集的发布,处理MMS任务的技术的进步,以及更合适的评估指标的建议。多模态摘要的思想是一个相当灵活的,包含了输入和输出方式的广泛可能性,也使得单模态摘要技术的知识很难理解MMS任务的现有工作。这就需要对多模态摘要进行调研。
MMS任务与任何单模态摘要任务一样,是一个要求很高的任务,且存在多个正确解,因此非常具有挑战性。创建多模态摘要的人必须使用他们之前的理解和外部知识来生成内容。建立计算机系统来模仿这种行为变得困难,因为它们内在缺乏人类的感知和知识,使自动多模态摘要的问题成为一项重要但有趣的任务。尽管有相当多的调研论文是针对单模态摘要任务撰写的,包括文本摘要[31,32,81,112,124]和视频摘要[6,41,52,76,102],以及多模态研究[3,4,43,90,103,107]的调研论文。然而,据我们所知,我们是第一个提出多模摘要的调研。通过这份手稿,我们统一和系统化的信息在相关的工作,包括数据集,方法论,和评价技术。通过这项调研,我们旨在帮助研究人员熟悉各种技术和资源,以进行多模式摘要领域的研究。
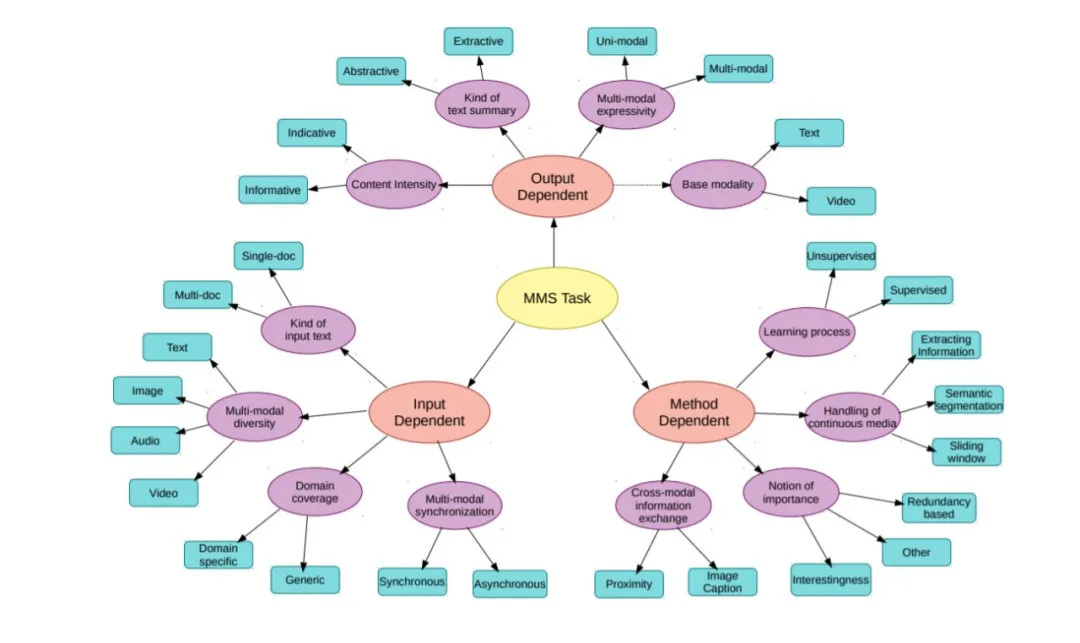
多模态摘要方法
许多研究尝试使用有监督和无监督技术来解决MMS任务。在本节中,我们试图以一种通用的方式描述MMS框架,阐明不同方法的细微差别。由于所使用的各种输入、输出和技术跨越了一个很大的可能性范围,我们将分别描述每一个可能性。我们将这一节分为三个阶段:预处理、主模型和后处理。
-
预处理:在多模态环境中,预处理是至关重要的一步,因为它涉及从不同模态中提取特征。每个输入模态都使用模态特征提取技术进行处理。尽管有些工作倾向于使用自己提出的模型来学习数据的语义表示,但几乎所有的作品都遵循相同的预处理步骤。由于相关的作品有不同的输入模态,我们分别描述了每种模态的预处理技术。
-
主模型:利用提取的特征来执行MMS任务已经采用了很多不同的技术。图3显示了研究人员解决MMS任务所采用的技术分析。我们已经尝试了几乎所有最近的架构,主要集中在以文本为中心的输出摘要。在以文本为中心形式的方法中,相邻形式被视为文本摘要的补充,通常在后处理步骤中被选择(章节4.3)。
-
后处理:后期处理大部分现有工作无法生成多模态摘要。生成的系统综合总结有一个内置的系统能产生多通道输出(主要是通过生成文本使用seq2seq机制和选择相关图片)(61、134)或者他们采取一些后处理步骤,获得视觉和声音补充剂生成的文本摘要[133]。神经网络模型使用多模态注意力机制来确定每个输入情况的模态相关性,用于选择最合适的图像[12,133]。更准确地说,使用视觉覆盖评分(在最后解码步骤之后),即生成文本摘要时的注意力值之和,来确定最相关的图像。根据任务需要,可以提取单幅图像[133],也可以提取多幅图像[13]来补充文本。
由于技术的进步,人们可以方便地以多种方式创建和共享信息,这在十年前是不可能的。由于这种进步,对多模态摘要的需求正在增加。我们提出了一项调研,以帮助熟悉用户的工具和技术目前的MMS任务。在这份手稿中,我们正式定义了多模态摘要的任务,我们还根据各种输入、输出和技术相关的细节,对现有的作品进行了广泛的分类。然后,我们包括用于处理MMS任务的数据集的全面描述。此外,我们还简要描述了用于解决MMS任务的各种技术,以及用于判断产生的摘要质量的评价指标。最后,本文还提出了MMS研究的几个可能方向。我们希望这篇调研论文能够对多模态摘要的研究起到重要的推动作用。
