
如何结合物理信息到强化学习是一个重要的问题。来自昆士兰科技大学、美国科罗拉多大学博尔德分校等学者撰写的《物理信息强化学习》综述,详述进展。
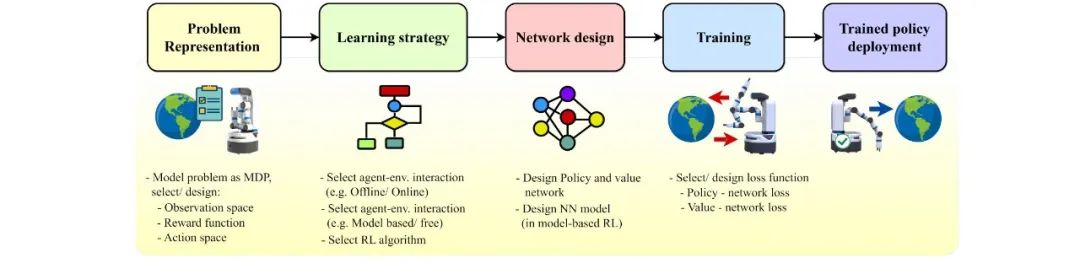
将物理信息纳入机器学习框架已经在许多应用领域引起了革命。这涉及通过整合物理约束并遵守物理定律来增强学习过程。在这项工作中,我们探讨了物理信息在强化学习应用中的实用性。我们对将物理信息纳入强化学习方法的文献进行了彻底的综述,通常称为物理信息强化学习(PIRL)。 我们引入了一种新的分类法,以强化学习流程作为骨干,用于分类现有工作、进行比较和对比,并得出关键见解。我们对现有工作进行了分析,涉及了为整合而建模的主导物理的表示/形式,它们对典型强化学习体系结构的具体贡献,以及它们与底层强化学习流程阶段的关系。我们还确定了现有PIRL方法的核心学习架构和物理整合偏见(即观测、归纳和学习),并将它们进一步分类以获得更好的理解和适应。 通过全面展示物理信息能力的实施,这一分类法提供了PIRL的一种连贯方法。它确定了已应用这种方法的领域,以及存在的差距和机会。此外,该分类法还揭示了未解决的问题和挑战,可以指导未来的研究。这个新兴领域具有巨大潜力,可以通过增加其物理合理性、精度、数据效率和在实际场景中的适用性来增强强化学习算法。
本文的贡献总结如下:
分类法:我们提出了一个统一的分类法,用于研究建模了哪些物理知识/过程,它们如何表示以及将它们纳入强化学习方法的策略。
算法综述:我们使用统一的符号、简化的功能图和对最新文献的讨论,展示了物理信息引导/物理信息强化强化学习方法的最新进展。
训练和评估基准综述:我们分析了已审查文献中使用的评估基准,从而呈现出用于理解流行趋势以及便于参考的流行评估和基准平台/套件。
分析:我们深入研究了各种基于模型和无模型的强化学习应用领域。我们详细分析了物理信息如何集成到特定的强化学习方法中,建模了哪些物理过程并将其纳入,以及使用了什么网络架构或网络增强来融合物理信息。
开放问题:我们总结了对挑战、开放性研究问题以及未来研究方向的看法。
物理信息机器学习(PIML):概述
PIML的目标是将数学物理模型与观测数据无缝融合在学习过程中。这有助于引导过程朝着在部分观测、不确定和高维度的复杂场景中找到物理一致解的方向前进[62, 52, 26]。将物理知识融入机器学习模型具有许多优点,如[62, 89]中所讨论的,这些信息捕捉了被建模过程的重要物理原理,带来以下优势:1) 确保ML模型在物理和科学上都是一致的。 2) 增加了模型训练的数据效率,意味着可以用更少的数据输入来训练模型。 3) 加快了模型训练过程,使模型更快地收敛到最优解。 4) 增加了训练模型的泛化能力,使其能够更好地对未在训练阶段看到的情景进行预测。 5) 提高了模型的透明度和可解释性,使其更值得信赖和可解释。根据文献,将物理知识或先验融入机器学习模型有三种策略:观测偏差、学习偏差和归纳偏差。观测偏差:这种方法使用反映其生成过程的物理原则的多模态数据[82, 61, 77, 132]。深度神经网络(DNN)直接在观测数据上进行训练,旨在捕捉潜在的物理过程。训练数据可以来自各种来源,如直接观测、模拟或物理方程生成的数据、地图或提取的物理数据。 学习偏差:通过软惩罚约束来强化物理先验知识是巩固物理先验知识的一种方式。这种方法涉及将基于过程物理的额外项添加到损失函数中,如动量或质量守恒。其中一个例子是物理信息神经网络(PINN),它通过将PDE嵌入到神经网络的损失函数中,使用自动微分来结合测量和偏微分方程(PDE)的信息[60]。一些突出的基于软惩罚的方法包括统计约束的GAN [127]、物理信息自动编码器[37]以及在损失函数中通过软约束编码不变性的InvNet [110]。
归纳偏差:自定义的神经网络引入的'硬'约束可以将先验知识纳入模型中。例如,Hamiltonian NN [47]受到哈密顿力学的启发,训练模型遵循精确的守恒定律,从而得到更好的归纳偏差。由Cranmer等人引入的Lagrangian神经网络(LNNs)[25]可以使用神经网络参数化任意Lagrangian,即使规范动量未知或难以计算。 Meng等人[90]使用贝叶斯框架从数据和物理中学习功能先验,使用Hamiltonian Monte Carlo(HMC)方法估算后验PI-GAN的潜在空间。此外,DeepONets [82]网络用于PDE不可知的物理问题。
物理信息强化学习:基础、分类和示例
物理信息强化学习的概念涉及将物理结构、先验和现实世界的物理变量纳入策略学习或优化过程中。物理归纳有助于提高强化学习算法/方法的效力、样本效率和加速训练,用于复杂问题求解和实际部署。根据具体问题或情景,可以在强化学习框架的不同阶段使用不同的强化学习方法来集成不同的物理先验,参见图4。
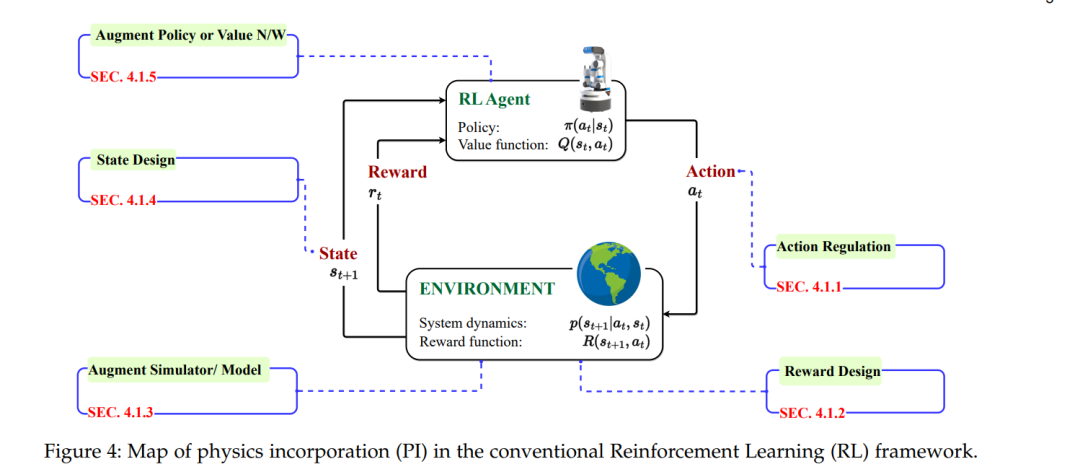
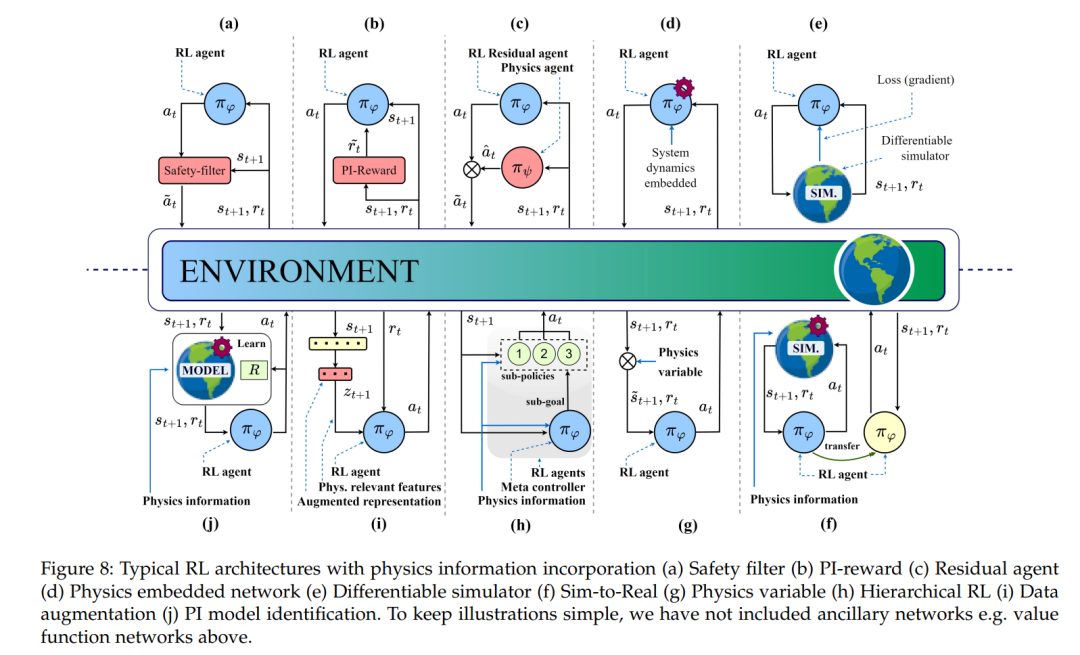
安全过滤器:该类别包括具有基于PI的模块的方法,该模块调节代理的探索以确保安全约束,详情请参见图8(a)。在此典型架构中,安全过滤器模块接受来自RL代理πφ的动作和状态信息(st),并优化动作,得到a˜t。
PI奖励:此类别包括使用物理信息修改奖励函数的方法,详情请参见图8(b)。在这里,PI奖励模块将代理的外部奖励(rt)与基于物理信息的内在成分相结合,得到r˜t。
残差学习:残差RL是一种架构,通常由两个控制器组成:一个由人设计的控制器和一个学习的策略[58]。在PIRL设置中,该架构由具有物理信息的控制器πψ和基于数据驱动的DNN策略πφ组成,称为残差RL代理,详情请参见图8(c)。
物理嵌入网络:在这个类别中,物理信息,例如系统动力学,直接嵌入到策略或值函数网络中,详情请参见图8(d)。
可微分模拟器:这里的方法使用可微分物理模拟器,这些模拟器是非传统的/或适应的模拟器,并明确提供了模拟结果相对于控制动作的损失梯度,详情请参见图8(e)。
从模拟到实际:在模拟到实际的架构中,代理首先在模拟器或源领域上进行训练,然后在目标领域上进行部署。在某些情况下,转移后会在目标领域进行微调,详情请参见图8(f)。
物理变量:此架构包括所有那些引入物理参数、变量或基元以增强RL框架的组件(例如状态和奖励)的方法。详情请参见图8(g)。
分层RL:此类别包括基于分层和课程学习的方法,详情请参见图8(h)。在分层RL(HRL)设置中,长期决策任务被自动分解为更简单的子任务。在课程学习中,通过学习解决一系列逐渐困难的任务来解决复杂任务。在HRL和CRL中,物理通常被纳入所有策略(包括元策略和子策略)和值网络中。这些方法大多是物理嵌入网络(图8(d))的扩展,如非HRL/CRL设置中使用的方式。
数据增强:此类别包括将输入状态替换为不同或增强形式的方法,例如低维表示,以从中提取特殊和与物理相关的特征。详情请参见图8(i)。在这种典型架构中,状态向量st+1被转换为增强表示zt+1。然后从中提取与物理相关的特征,并由RL代理(πφ)使用。
PI模型识别:此架构代表那些PIRL方法,特别是在数据驱动的MBRL设置中,其中物理信息直接纳入模型识别过程中。详情请参见图8(j)。
结论
本论文介绍了一种先进的强化学习范式,称为物理信息强化学习(PIRL)。通过充分利用数据驱动技术和对基础物理原理的知识,PIRL能够改善RL算法/方法的效能、样本效率和训练加速,用于复杂问题求解和实际部署。我们创建了两个分类法,根据物理先验/信息类型和物理先验归纳(RL方法)对传统PIRL方法进行分类,为理解这一方法提供了一个框架。为了帮助读者理解解决RL任务涉及的物理知识,我们在文中包含了来自近期论文的各种解释性图像,并在表2和表3中总结了它们的特点。此外,我们还提供了一个详细列出PIRL评估所使用的训练和评估基准的基准总结表4。我们的目标是简化现有PIRL方法的复杂概念,使其更容易在各个领域中使用。最后,我们讨论了当前PIRL工作的局限性和未解决的问题,鼓励在这一领域进行进一步研究。


