因果表示学习
·

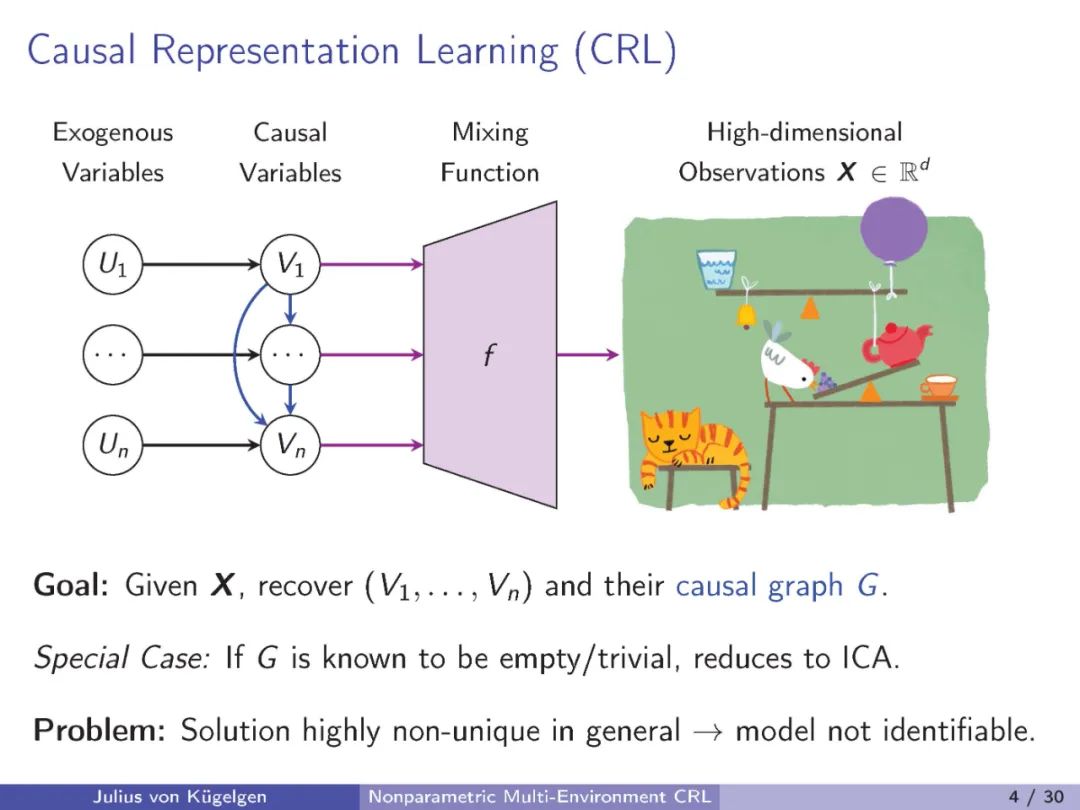
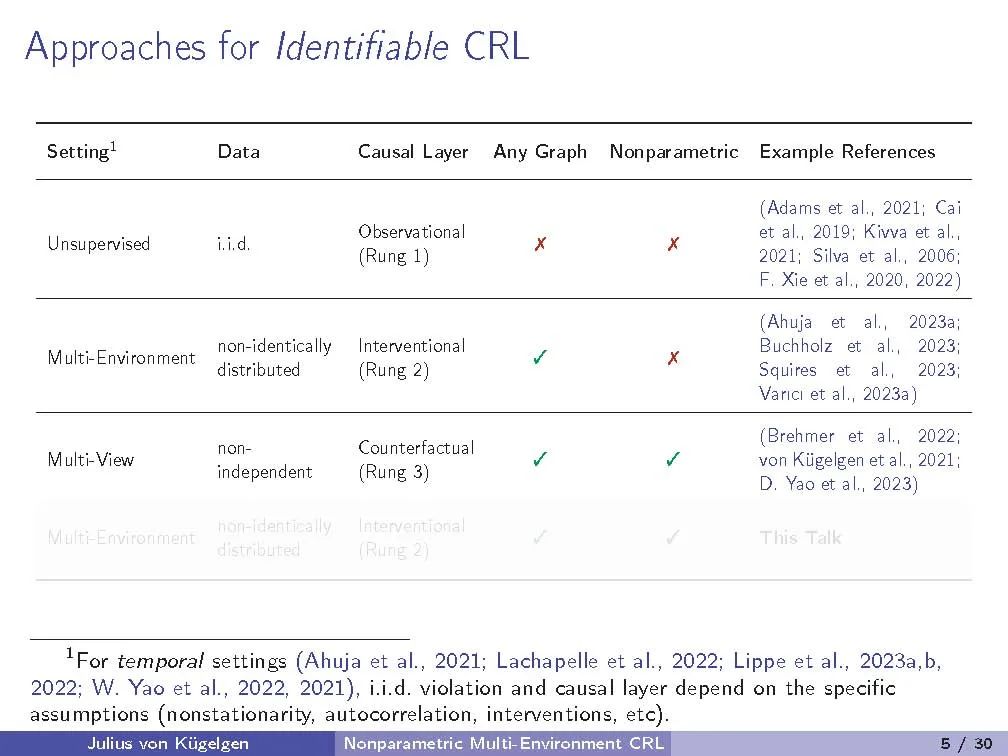
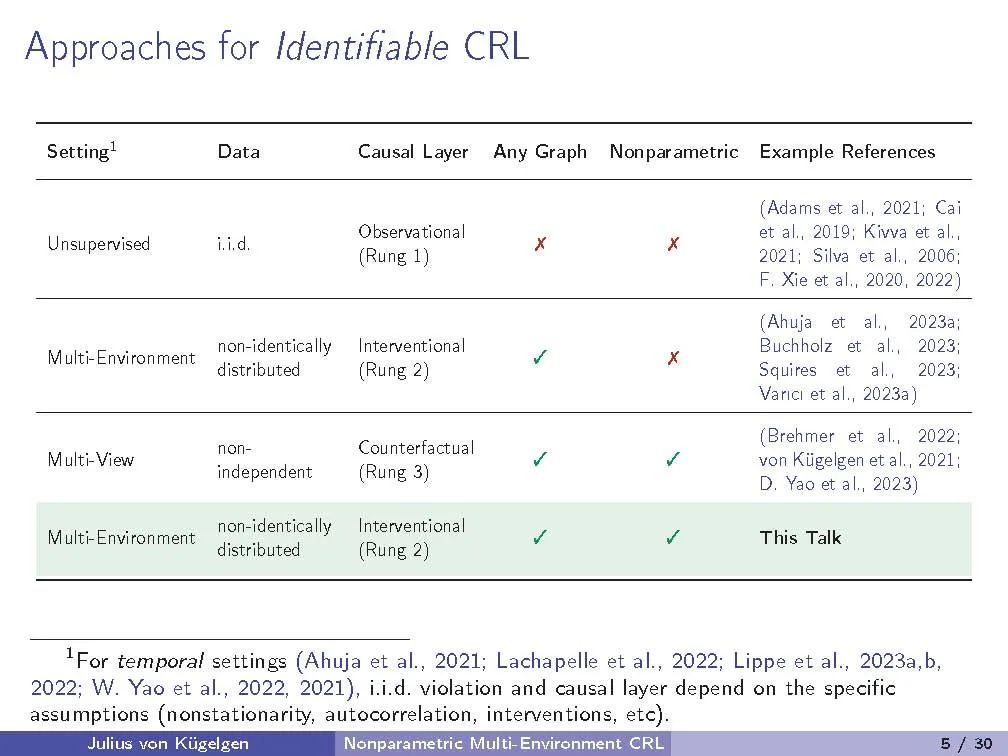
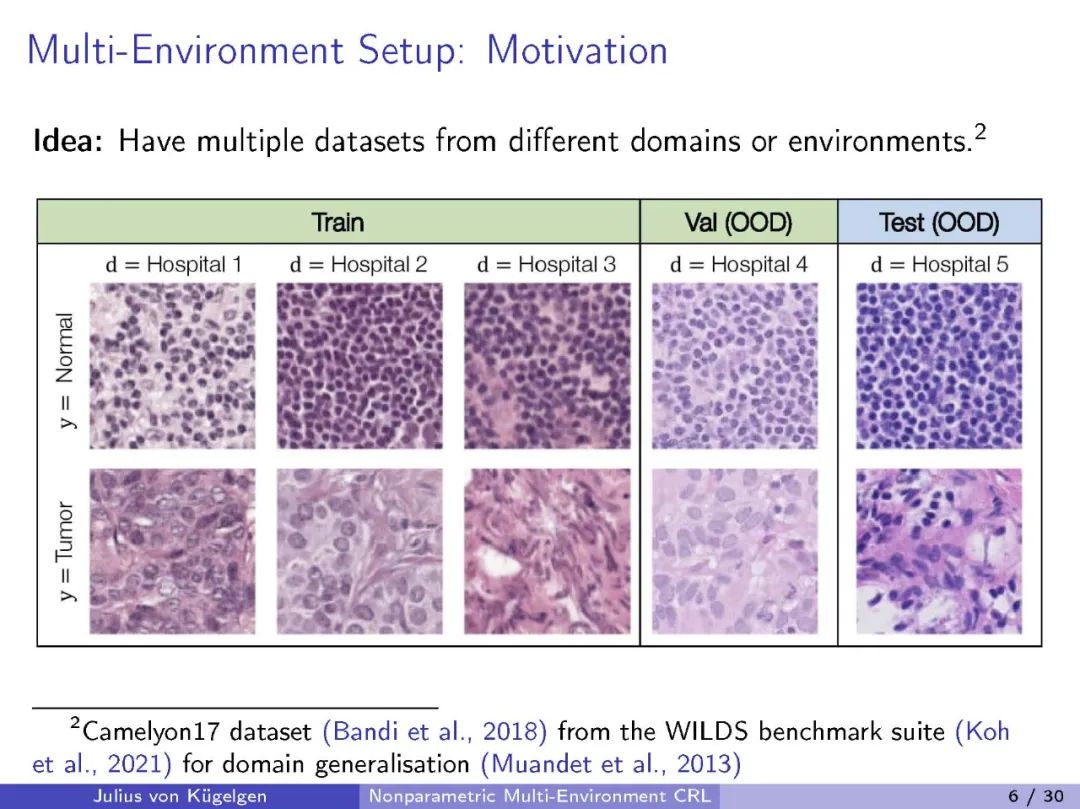
我们研究因果表示学习,即从高维变量混合中推断潜在因果变量及其因果关系的任务。先前的工作依赖于弱监督,以反事实干预前后视图或时间结构的形式;对混合函数或潜在因果模型提出限制性假设,如线性;或需要对生成过程有部分知识,如因果图或干预目标。相反,我们考虑一个一般性设置,在该设置中,因果模型和混合函数都是非参数的。学习信号采取多个数据集或环境的形式,这些数据集或环境源于潜在因果模型中未知干预的结果。我们的目标是识别出基本真实的潜在因素及其因果图,直到一组我们证明无法从干预数据解决的模糊性。我们研究了两个因果变量的基本设置,并证明观测分布和每个节点一个完美干预就足以确定性识别,前提是一个通用性条件。该条件排除了涉及干预和观测分布的微调的伪解,反映了类似于非线性因果-效应推断的相似条件。对于任意数量的变量,我们显示每个节点至少一对不同的完美干预领域保证了确定性识别。此外,我们展示了所有等效解决方案保留了潜在变量间因果影响的强度,使得推断出的表示适合从新数据中得出因果结论。我们的研究为带有未知干预的一般非参数设置提供了首个确定性识别结果,并阐明了在没有更直接监督的情况下,因果表示学习可能与不可能的事项。




成为VIP会员查看完整内容
相关内容
Arxiv
135+阅读 · 2023年4月7日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
135+阅读 · 2023年4月7日