预训练语言模型
·

哈工大讯飞联合实验室(HFL)资深级研究员、研究主管崔一鸣受邀在NLPCC 2020会议做题为《Revisiting Pre-trained Models for Natural Language Processing》的讲习班报告(Tutorial),介绍了预训练语言模型的发展历程以及近期的研究热点。本期推送文末提供了报告的下载方式。
NLPCC 2020 Tutorials:
http://tcci.ccf.org.cn/conference/2020/tutorials.php
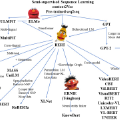
预训练语言模型(PLM)已经成为最近自然语言处理研究的基本元素。在本教程中,我们将回顾文本表示的技术进展,即从一个热点嵌入到最近的PLMs。我们将介绍几种流行的PLMs(如BERT、XLNet、RoBERTa、ALBERT、ELECTRA等)及其技术细节和应用。另一方面,我们也将介绍中国plm的各种努力。在演讲的最后,我们将分析目前PLMs的不足之处,并展望未来的研究方向。

成为VIP会员查看完整内容

相关内容
相关主题
相关VIP内容
相关资讯
相关论文