本研究探索超视距空战仿真模拟,重点聚焦涉及自主智能体的二对二作战场景。超视距空战的交战阶段呈现复杂且不可预测的态势,因其难以预判敌方战机行为与战术决策结果,尤其在多智能体环境中更为凸显。深度强化学习技术作为一种前景广阔的解决方案,能使智能体从动态环境中自主学习。据战斗机飞行员确认,集体态势感知(即理解友军与敌方的空间分布及方位)对执行协同战术机动至关重要。本研究的主要贡献在于开发了AsaGym库——专为超视距场景下基于深度强化学习的战斗机智能体开发与训练而设计的工具库。通过案例研究展示其应用价值:采用基于集体态势感知的奖励函数促进协同作战,并比较不同深度强化学习算法以评估其培育协作行为的能力。研究成果凸显了深度强化学习在应对现代空战复杂性方面的潜力,为多智能体超视距场景下发展更具适应性与实效性的战术提供支持。
空战是复杂动态的作战场景,要求娴熟的飞行员快速决策以获取战术优势[1]。超视距空战特指飞行员无法目视敌机距离范围内发生的交战行动[2][3]。虽然部分空战仍发生在视距内,但多数交战始于超视距阶段。此阶段通常最为关键,因其可为后续战斗阶段创造优势或制造困难。飞行员面临的核心挑战在于机动规划,这体现了其战术思维能力并决定交战结果[4]。
超视距空战的计算机仿真能复现多样态势,助力测试新战术、传感器与武器系统[5]。这些仿真的最大难点在于模拟飞行员在全战斗阶段的复杂行为。这些决策包括适应新态势、与友军协同执行策略以及精准把握导弹发射时机。
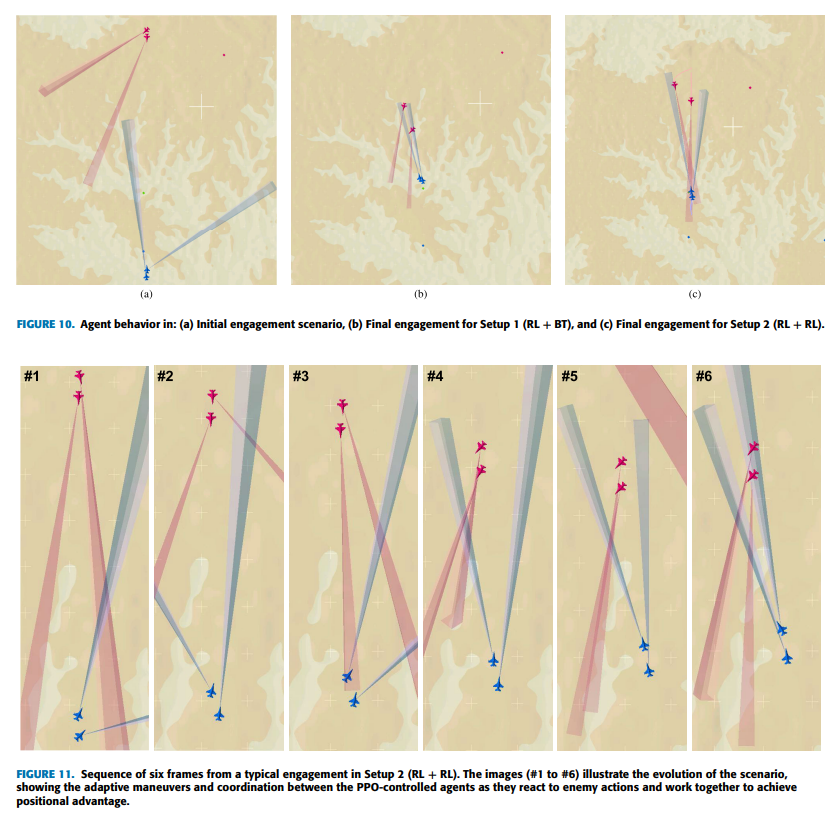
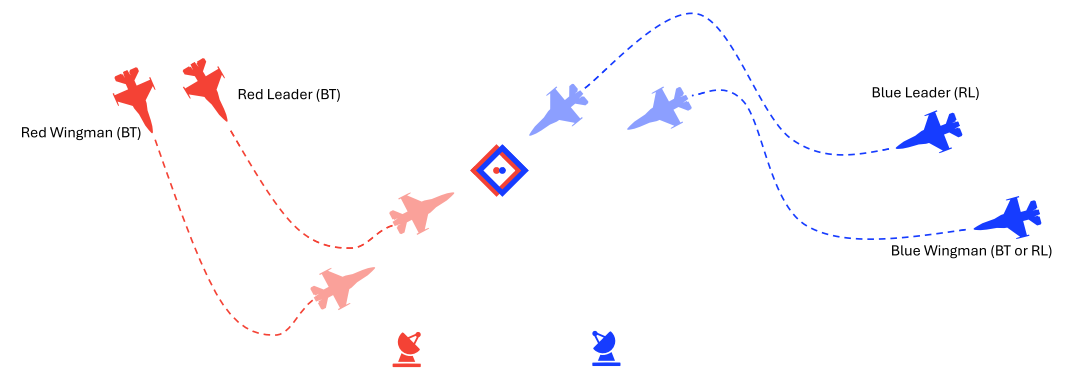
本研究探索自主智能体学习超视距交战机动的能力。交战涉及操纵战机获取对敌优势,即将敌方定位在己方导弹有效射程(称为武器交战区)内,同时确保自身处于敌方武器交战区外[6][7]。当存在多个敌方目标时,交战阶段复杂性显著增加。
强化学习技术是该问题的前瞻性解决方案,它使自主智能体能从挑战性经验中学习。强化学习是一种机器学习方法,自主智能体通过与环境交互学习优化决策。智能体因其行动获得奖励或惩处,并随时间调整策略以最大化累积奖励[8]。深度强化学习是强化学习的进阶形式,利用深度神经网络管理复杂环境,使智能体能在动态不确定条件下(如超视距空战)做出决策[9]。
在此背景下,现有空战仿真环境常缺乏模块化设计、多智能体深度强化学习实验支持或融入作战洞察(如友军与敌机空间协同)的机制。
因此,本研究的主要贡献包括:
• 开发AsaGym库——用于超视距空战中基于深度强化学习的自主战斗机智能体仿真与训练,并通过案例研究展示其在使用促进协同与态势感知的奖励设计中的应用。
此外,提供以下具体贡献:
• 设计面向任务的奖励函数,基于友军与敌方的空间关系激励智能体协作行为;
• 融入巴西空军战斗机飞行员作为领域专家提供的作战知识,其强调空间感知对超视距空战协同机动的重要性;
• 对四种先进深度强化学习算法——近端策略优化、软演员-评论家、双延迟深度确定性策略梯度以及优势演员-评论家——在模拟超视距空战场景交战阶段的应用进行比较评估。
本研究的后续结构如下:第二章概述相关工作,重点评述深度强化学习在超视距空战仿真中的既往研究;第三章详述方法论,包括用于表征超视距空战交战阶段的深度强化学习模型设计,以及用于训练评估的实验配置;第四章讨论实验成果与分析,深入解析智能体在不同场景下的性能表现;最终,第五章总结核心发现并展望未来研究方向。