所有相关资源可在以下链接获取:https://github.com/YuyangSunshine/Awesome-Continual-learning-of-Vision-Language-Models 。
I. 引言
视觉—语言模型(Vision-Language Models, VLMs),如 CLIP [1]、ALIGN [2]、BLIP [3] 和 FlamingoALIGN [4],通过对网络规模的图像—文本对进行学习,构建了强大的跨模态表示,从而推动了多模态理解的革新。这类模型在图文检索 [5], [6]、视觉问答(VQA)[7]、图像描述生成 [8], [9] 等众多下游任务中展现出卓越的零样本泛化能力,而无需针对任务进行微调。这一成功源于预训练—迁移(pre-train and transfer)范式:在多样化的大规模数据上进行预训练,获得可泛化的多模态嵌入 [1]。 然而,这种成功建立在一个关键假设之上:数据分布是静态且封闭的。在具身智能体、科学机器人或个性化助手等实际场景中,数据往往以**非平稳、开放式流(non-stationary and open-ended stream)**的形式到达。这引出了一个核心问题: VLMs 如何在随时间获取新知识的同时,不遗忘其原有能力?
简单地在新任务上微调模型往往会导致灾难性遗忘 [10],表现为多模态推理能力下降和零样本能力受损。虽然灾难性遗忘在单模态持续学习(Continual Learning, CL)领域已有深入研究 [11], [12],但在基础级别多模态系统中仍鲜有探讨。 持续学习研究提出了多种缓解遗忘的技术,例如正则化 [13]、重放(rehearsal)[14] 和动态网络扩展 [15]。近年来,多模态持续学习(Multimodal Continual Learning, MMCL)逐渐兴起,旨在从多感官模态中增量学习 [16], [17]。然而,大多数 MMCL 研究聚焦于小规模模型与数据集(如在 AVE 数据集 [18] 上进行的音视频分类,或在 MS-COCO [19] 上的图文匹配),并假设任务间的架构同质化。这些假设在预训练的 VLMs 中往往不成立,因为它们通常具备冻结的视觉编码器、共享的跨模态注意力层,以及为零样本泛化而校准的大规模嵌入空间。 因此,面向预训练 VLMs 的持续学习(VLM-CL)形成了一个不同于单模态 CL 与既有 MMCL 设置的全新前沿。具体而言,我们识别出 VLM-CL 中独有的三大核心挑战: * 跨模态特征漂移(Cross-Modal Feature Drift)
预训练将视觉与文本特征对齐到共享语义空间。在持续更新过程中,尤其是当仅有部分模态可用或训练偏向于单一模态时,这种对齐可能显著退化。实证研究(如 IncCLIP [20] 与 ZSCL [21])发现,即使单模态分类性能稳定,跨模态检索精度也可能大幅下降,揭示了这种漂移的隐蔽性与破坏性。 * 共享模块干扰(Shared Module Interference)
许多 VLMs 依赖共享组件(如跨模态注意力模块或融合层)来整合视觉与语言。若在没有结构隔离的情况下进行顺序更新,会导致任务与模态间的相互干扰,破坏知识保持与模态对齐。这一问题在使用适配器(adapter)或低秩适配(LoRA)[22], [23] 等参数高效设置时更为突出。 * 零样本能力衰退(Zero-Shot Capability Erosion)
零样本泛化(如基于提示的推理、开放词表推理)是 VLM 的核心优势。然而,持续微调常会扭曲预训练嵌入分布,从而降低零样本迁移能力。近期研究 [24] 表明,即使是轻微的领域漂移,也可能导致零样本检索或定位性能下降超过 30%。
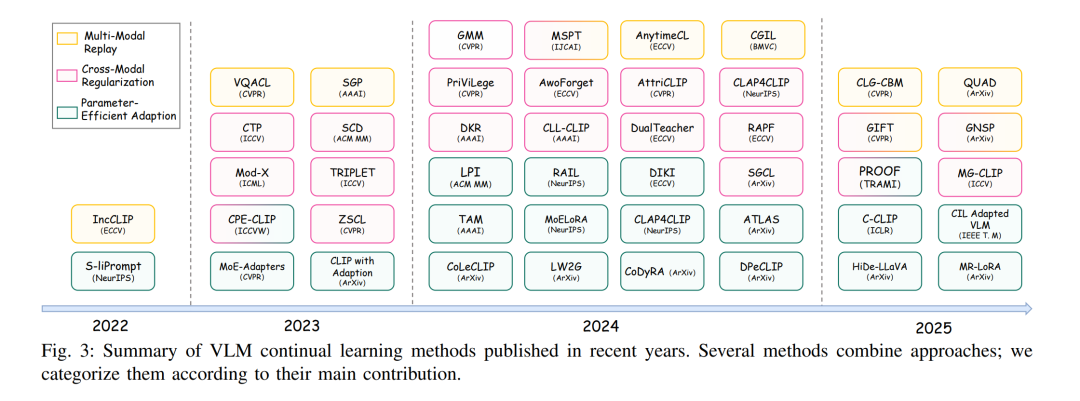
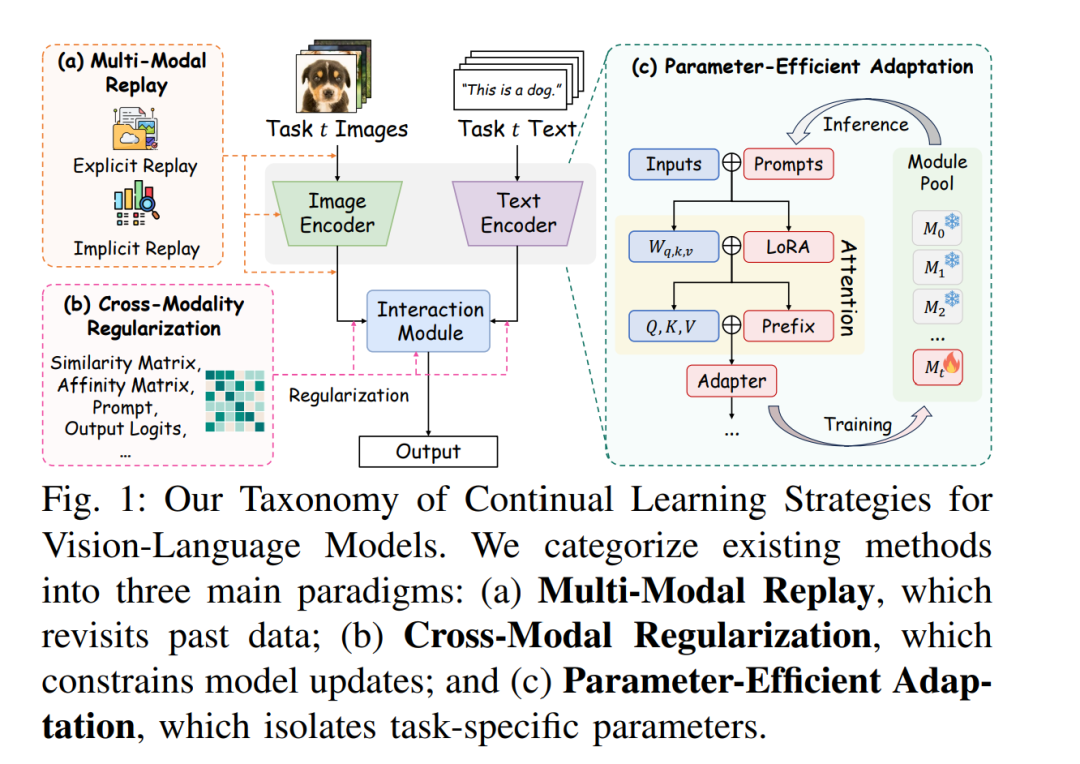
尽管已有工作探索了将 CLIP 类模型应用于持续目标识别 [20]、组合推理 [25] 或长期指令执行 [26],但该领域仍缺乏系统梳理 VLM-CL 挑战、方法与评测实践的专门综述。现有的 MMCL 综述 [16], [27] 也未能捕捉预训练跨模态系统的特有脆弱性。 在本文中,我们首次对 VLM 的持续学习进行全面回顾。为该新兴领域构建结构化框架,我们提出了一个针对挑战的解决方案分类体系,将现有方法按其应对上述挑战的方式划分为三类(见图 1): 1. 多模态重放策略(Multi-Modal Replay Strategies):通过显式或隐式记忆机制缓解跨模态漂移; 1. 跨模态正则化(Cross-Modal Regularization):在更新过程中保持模态对齐; 1. 参数高效适配(Parameter-Efficient Adaptation):通过模块化或低秩更新减少参数干扰。
我们的主要贡献如下:
识别并分析了 VLM-CL 中特有的三大失效模式:跨模态漂移、参数干扰与零样本能力衰退; * 提出一个面向解决方案的分类体系,将现有方法归纳为多模态重放、跨模态正则化与参数高效适配三大范式; * 系统回顾了 VLM-CL 的基准数据集、评测指标与评测协议,并指出当前评测标准的局限; * 讨论了开放挑战与未来方向,包括可扩展的持续预训练与组合泛化,并提供了精心整理的相关资源。
本文余下结构如下:第 II 节回顾相关基础;第 III 节阐述 VLM-CL 的核心挑战,并据此在第 IV 节提出解决方案分类体系;第 V 节系统回顾评测协议与关键基准;第 VI 节探讨开放问题与未来方向。