
转载机器之心 机器之心编辑部
刚刚,人工智能顶会 NeurIPS 2025 公布了最佳论文奖、时间检验奖等奖项!
今年共有 4 篇论文获得最佳论文奖,另有 3 篇论文获得最佳论文亚军(Best Paper Runner-up)。
这七篇论文的研究涵盖了多个前沿方向,包括:扩散模型理论、自监督强化学习、大语言模型中的注意力机制、LLM 的推理能力、在线学习理论等。
另外,任少卿、何恺明、Ross Girshick、孙剑 2015 年合著论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》获得了时间检验奖。
NeurIPS 还宣布了Sejnowski-Hinton 奖的获奖者:获奖论文是《Random synaptic feedback weights support error backpropagation for deep learning》。
本届 NeurIPS 会议共收到 21575 份有效投稿并进入评审流程,最终接收 5290 篇,整体录用率为 24.52%。
以下是获奖论文的详细信息:
最佳论文
论文 1:Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond)

作者:Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Yejin Choi * 机构:艾伦人工智能研究所、斯坦福大学 * 论文地址:https://openreview.net/pdf?id=saDOrrnNTz
大语言模型在生成多样化、具有人类风格的创意内容方面常常表现欠佳,生成出的内容往往趋向于同质化。然而,可规模化评估语言模型输出多样性的方法仍然有限。
为填补这一空白,论文作者提出 Infinity-Chat:一个大规模数据集,提供了首个用于系统研究真实世界开放式查询的大规模资源:包含 26K 条多样、真实世界、开放式的用户查询。这类数据允许存在广泛的合理答案,并不存在唯一的标准答案。论文进一步提出了首个用于刻画语言模型所面对开放式提示全谱系的综合分类体系(taxonomy):包含 6 个顶层类别(例如创意内容生成、头脑风暴与构思),并进一步细分为 17 个子类别。
基于 Infinity-Chat,论文研究者进行了对语言模型模式坍缩(mode collapse)的大规模研究,揭示了在开放式生成中显著存在一种人工蜂群思维(Artificial Hivemind)效应,其特征包括:
(1)模型内重复(intra-model repetition):同一个模型会反复生成相似的回答; (2)模型间同质化(inter-model homogeneity):不同模型之间也会产生惊人相似的输出。
Infinity-Chat 还包含 31,250 条人工标注,覆盖绝对评分与两两偏好选择,每个样本均有 25 位独立标注者参与。
评审委员会认为,这篇论文在理解现代语言模型中的多样性、价值多元与社会影响方面做出了重要且及时的贡献。
总体而言,这项工作为数据集与基准树立了新标杆:它推动的是对科学理解与重大社会挑战的进展,而不只是单纯提升技术性能。
论文 2:Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
作者:Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, Dayiheng Liu, Jingren Zhou, Junyang Lin * 机构:阿里通义千问团队、爱丁堡大学等 * 论文链接:https://openreview.net/forum?id=1b7whO4SfY * 代码链接:https://github.com/qiuzh20/gated_attention
这篇论文在业内首次揭秘了注意力门控对大模型性能和训练的影响,目前该研究已应用于 Qwen3-Next 模型,并显著提升模型的性能与鲁棒性。
在大语言模型持续向更大规模、更长上下文演进的过程中,训练稳定性与注意力行为的可控性日益成为关键瓶颈。门控机制的有效性已经被广泛证实,但其在注意力机制中的有效性及扩展(scaling up)的能力并未被充分讨论。
在通义千问团队的论文中,研究团队系统性地分析了门控机制对大语言模型的有效性,并通过一系列控制实验证明了门控机制的有效性来源于增强了注意力机制中的非线性与提供输入相关的稀疏性。
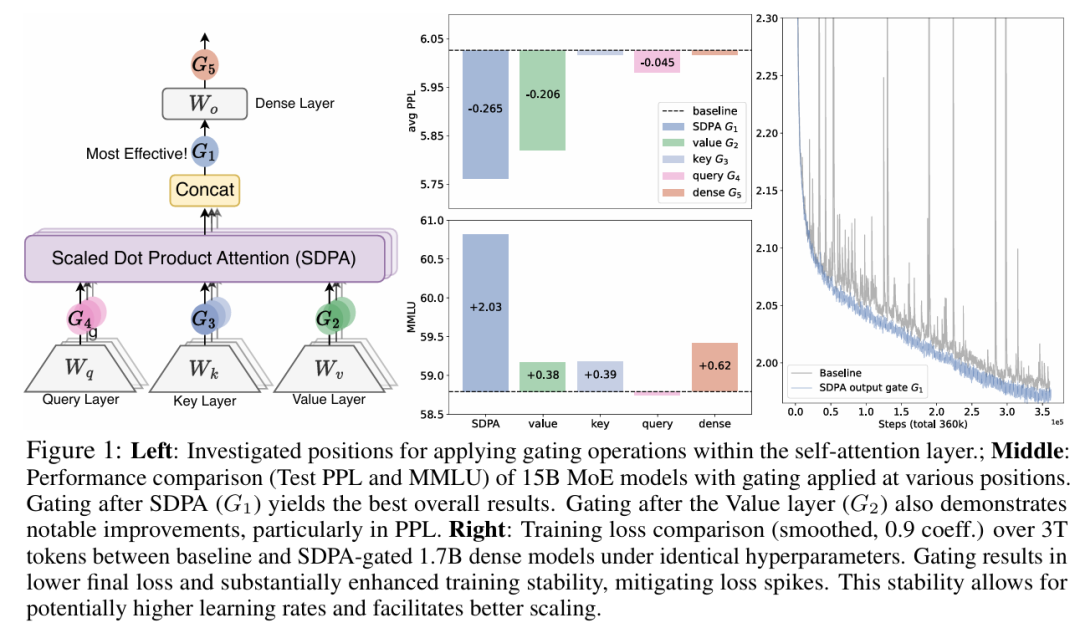
图 1:左图: 研究了在自注意力层内部应用门控操作(Gating operations)的具体位置;中图: 在不同位置应用门控的 15B MoE 模型(混合专家模型)的性能比较(基于测试集 PPL 和 MMLU)。结果显示,在 SDPA 之后进行门控 (G1) 取得了最佳的总体效果。在 Value 层之后进行门控 (G2) 也展现出显著的提升,尤其是在 PPL 指标上;右图: 在相同的超参数下,基线模型与经过 SDPA 门控的 1.7B Dense 模型(稠密模型)在 3T tokens 训练过程中的训练损失(Training Loss)比较(经平滑处理,系数 0.9)。门控机制实现了更低的最终损失,并大幅增强了训练稳定性,有效缓解了损失尖峰(Loss spikes)。这种稳定性允许使用潜在更高的学习率,并有利于模型更好地进行扩展(Scaling)。
此外团队还进一步发现了门控机制能消除注意力池(Attention Sink)和巨量激活(Massive Activation)等现象,提高模型的训练稳定性,极大程度减少了训练过程中的损失波动(loss spike)。得益于门控机制对注意力的精细控制,模型在长度外推上相比基线得到了显著的提升。团队在各个尺寸、架构、训练数据规模上验证了方法的有效性,并最终成功运用到了 Qwen3-Next 模型中。
评审委员会认为:这篇论文的工作量巨大,只有在具备工业级计算资源的条件下才可能完成。作者愿意公开分享这些结果,将推动社区对大语言模型注意力机制的理解,这一点尤其值得称赞 —— 特别是在当下 LLM 领域科学成果公开共享逐渐减少的环境里。
论文 3:1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
作者:Kevin Wang , Ishaan Javali, Michał Bortkiewicz, Tomasz Trzcinski, Benjamin Eysenbach * 机构:普林斯顿大学、华沙理工大学 * 论文链接:https://openreview.net/pdf?id=s0JVsx3bx1
该论文研究了能够解锁自监督强化学习可扩展性的关键积木模块,其中网络深度是一个至关重要的因素。近年来大多数 RL 论文都依赖较浅的网络结构(约 2—5 层),而本文证明:将网络深度增加到 1024 层,可以显著提升性能。
论文的实验在一种无监督的目标条件(goal-conditioned)设定下进行:不提供示范数据或奖励信号,因此智能体必须从零开始探索,并学习如何最大化到达被指令目标的概率。在模拟的运动控制(locomotion)与操作(manipulation)任务上评估时,该方法在自监督的对比式(contrastive)RL 算法上将性能提升了 2× – 50×,并超过了其他目标条件基线方法。增加模型深度不仅提升了成功率,还会在质量上改变学到的行为。
评审委员会认为:这篇论文挑战了一个传统观点:强化学习所提供的信息不足以有效引导深度神经网络中数量庞大的参数,因此大型 AI 系统应主要通过自监督训练,而 RL 只用于微调。该工作提出了一种新颖且易于实现的 RL 范式,使得极深神经网络也能被有效训练,方法基于自监督与对比式强化学习。
论文 4:Why Diffusion Models Don’t Memorize: The Role of Implicit Dynamical Regularization in Training
作者:Tony Bonnaire, Raphaël Urfin, Giulio Biroli, Marc Mezard * 机构:巴黎文理研究大学、博科尼大学 * 论文地址:https://openreview.net/pdf?id=BSZqpqgqM0
是什么机制阻止扩散模型对训练数据进行死记硬背,并让它们具备泛化能力?该论文研究了训练动力学在从泛化走向记忆的转变过程中所扮演的角色。
通过大量实验与理论分析,论文研究者识别出两种不同的时间尺度:一个较早的时间点 t_g,模型从此开始能够生成高质量样本;以及一个更晚的时间点 t_m,超过它之后模型会出现记忆化(memorization)。
关键发现是:t_m 会随训练集大小 N 线性增长,而 t_g 基本保持不变。这意味着,随着数据集变大,会出现一个越来越宽的训练时间窗口:在这个窗口里,模型能够有效泛化;但如果继续训练超过该窗口,模型又会表现出明显的记忆化。只有当 N 大到超过某个与模型相关的阈值时,过拟合才会在无限训练时间的极限下消失。
这些发现揭示了训练动力学中存在一种隐式的动态正则化形式:即便在高度过参数化的设定下,也能通过训练过程本身来避免记忆化。
评审委员会认为:本文围绕扩散模型的隐式正则化动力学提出了基础性研究,将经验观察与形式化理论统一起来,给出了一个强有力的结果。
通过把扩散模型的实际成功直接联系到一个可证明的动力学性质(即过拟合被隐式地推迟),论文为理解现代生成式 AI 的机制提供了基础且可操作的洞见,并为研究泛化问题的分析深度树立了新标杆。
最佳论文亚军(Best Paper Runner-up)
论文 1:Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
作者:Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, Gao Huang * 机构:清华大学、上海交通大学 * 论文链接:https://openreview.net/pdf?id=4OsgYD7em5
这篇论文给出了一个执行得非常出色、且极其关键的否定性结论,直接挑战了大语言模型(LLM)研究中一个被广泛接受、近乎基础性的假设:带可验证奖励的强化学习(RLVR)能够激发模型真正全新的推理能力。
这一发现非常重要,希望它能促使研究者去探索更根本性的新型强化学习范式:能够在巨大的行动空间中有效导航,并真正拓展 LLM 的推理能力。
论文 2:Optimal Mistake Bounds for Transductive Online Learning
作者:Zachary Chase, Steve Hanneke, Shay Moran, Jonathan Shafer * 机构:肯特州立大学、普渡大学等 * 论文地址:https://openreview.net/pdf?id=EoebmBe9fG
这篇论文在学习理论领域取得了突破性进展:它以优雅、全面且决定性的方式,彻底解决了一个长达 30 年的公开难题,理应获得 NeurIPS Best Paper Runner-Up(最佳论文亚军)奖。
作者不仅精确刻画了传导式在线学习(transductive online learning)的最优错误上界(mistake bound)为 Ω(√d),还给出了与之紧密匹配的 O (√d) 上界,从而实现了紧致(tight)的结果。这一结论确立了传导式在线学习与标准在线学习之间存在二次量级的差距。
他们的证明技巧在新颖性与巧妙性上都令人印象深刻。对于下界证明,对手(adversary)采用了一种高度精细的策略:一方面迫使学习者犯错,另一方面又小心地控制版本空间(version space)的收缩速度,并利用树上的路径(paths in trees)这一概念作为底层的核心结构。而对于上界(证明在 O (√d) 次错误内可学习),作者提出了一个创新的假设类构造:对路径外节点(off-path nodes)嵌入一种稀疏编码(sparse encoding)。
这种由精巧的假设类构造与高度自适应的学习算法所形成的复杂联动,堪称理论分析与算法设计的教科书级示范。
论文 3:Superposition Yields Robust Neural Scaling

作者:Yizhou Liu, Ziming Liu, Jeff Gore * 机构:MIT * 论文地址:https://openreview.net/pdf?id=knPz7gtjPW * Superposition Yields Robust Neural Scaling * Yizhou Liu, Ziming Liu, Jeff Gore
这篇论文不再停留在对神经网络缩放定律(neural scaling laws)的现象性描述,即随着模型规模、数据集规模或计算资源的增加,模型损失会以幂律形式下降这一已被大量实证确立的规律,而是进一步论证:表征叠加才是支配这些缩放定律的主要机制。
论文的核心结论得到了多组精心设计实验的支持,并为这一重要研究方向提供了新的洞见。
时间检验奖
任少卿、何恺明、Ross Girshick、孙剑合著论文《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》获得了时间检验奖。
《Faster R-CNN》无疑是计算机视觉领域最具里程碑意义的工作之一。自 2015 年发表以来,它不仅奠定了现代目标检测框架的核心范式,更深刻影响了后续十年视觉模型的发展方向。
这篇论文获得时间检验奖,可以说是实至名归。

论文地址:https://arxiv.org/pdf/1506.01497
截至现在,Faster R-CNN 已被引用超过 56,700 次。它深刻影响了整个计算机视觉领域,成为大量后续工作的基础。该论文实现了极高精度与接近实时(5 FPS)检测的统一,使神经网络目标检测模型得以真正部署到真实世界应用中。
Faster R-CNN 是第一个用完全可学习的两阶段 pipeline(包括 RPN 和检测网络)取代 selective search 和手工设计候选框的方法。
Sejnowski-Hinton 奖
今年 NeurIPS 还宣布了 Sejnowski-Hinton 奖的获奖者:Timothy Lillicrap、Daniel Cownden、Douglas Tweed 和 Colin Akerman,以表彰他们发表于 2016 年的开创性研究:《Random synaptic feedback weights support error backpropagation for deep learning》。
论文地址:https://www.nature.com/articles/ncomms13276
多年来,大脑理论一直试图解释:神经回路如何仅依赖局部信息实现高效学习,也就是说,突触如何根据每个连接处可获得的信号进行调节,而非依赖显式的、全局的误差信号反向传播。受到这一挑战的启发,研究者们开始探索如何使用局部学习规则训练人工神经网络,使其能够执行类似梯度下降的学习过程。
本论文因在这一方向上的重要贡献而获奖,它发现并提出了著名的反馈对齐(Feedback Alignment)机制。作者证明,多层网络可以在无需与前向权重完全对称的反馈权重下有效学习(不同于传统反向传播)。更为引人注目的是,随着学习过程进行,网络的前向权重会自然地与这些随机反馈信号对齐,从而产生一个虽有偏差但足够有用的梯度估计。
这项工作影响深远,帮助建立了 NeurIPS 社区乃至更广泛学界关于生物可行(biologically plausible)学习规则的全新研究方向。
Sejnowski-Hinton Prize 于 2025 年首次设立,其背后蕴含着一段合作与友谊的故事。
1983 年,Geoffrey Hinton 与 Terry Sejnowski 达成一个约定:如果我们其中一人因在玻尔兹曼机方面的工作获得诺贝尔奖,而另一个没有,我们将共享奖金。
在 2024 年,当 John Hopfield 和 Geoffrey Hinton 获得诺贝尔物理学奖(其中引用了他们在玻尔兹曼机方面的贡献)时,Terry Sejnowski 拒绝接受自己那一半奖励。
随后,Geoffrey Hinton 将那笔奖金捐赠给 NeurIPS,用于设立 Sejnowski-Hinton 奖,以纪念他们长期的合作关系,以及他们对推动大脑计算理论与学术社区协作精神的承诺。
参考链接: https://blog.neurips.cc/author/mengyeren/ https://blog.neurips.cc/2025/11/26/announcing-the-2025-sejnowski-hinton-prize/

