

摘要——数学文字题(Math Word Problem, MWP)自20世纪60年代起便作为人工智能(AI)领域的基础研究主题之一,其研究目标在于通过模拟类人认知智能以推动AI的推理能力发展。该领域的主流技术范式经历了从早期基于规则的方法到深度学习模型的演变,并正快速迈向大语言模型(LLM)时代。 然而,目前领域内仍缺乏一个系统的分类体系与对最新发展趋势的综述性讨论。为此,本文从人类认知视角出发,对MWP求解相关研究进行了全面回顾,旨在揭示当代AI模型如何在模拟人类认知能力方面不断进步。 具体而言,我们总结了MWP求解中涉及的五种关键认知能力:问题理解(Problem Understanding)、逻辑组织(Logical Organization)、联想记忆(Associative Memory)、批判性思维(Critical Thinking)与知识学习(Knowledge Learning)。围绕这些能力,我们回顾了过去十年中两类主流MWP求解模型:神经网络求解器与基于大语言模型的求解器,并探讨它们在复杂问题求解过程中所展现的类人认知特征。 此外,我们重新运行了所有具有代表性的MWP求解模型,并在五个主流基准数据集上补充其性能结果,以实现统一对比。 据我们所知,本综述是首个从人类推理认知视角系统分析过去十年MWP研究的工作,并在现有方法间提供了整体性比较框架。我们希望该研究能为未来AI推理能力的发展提供启发。 我们的开源资源已在 https://github.com/Ljyustc/FoI-MWP 发布。 关键词——数学文字题;认知能力;MWP求解器;大语言模型;数学推理。
1 引言
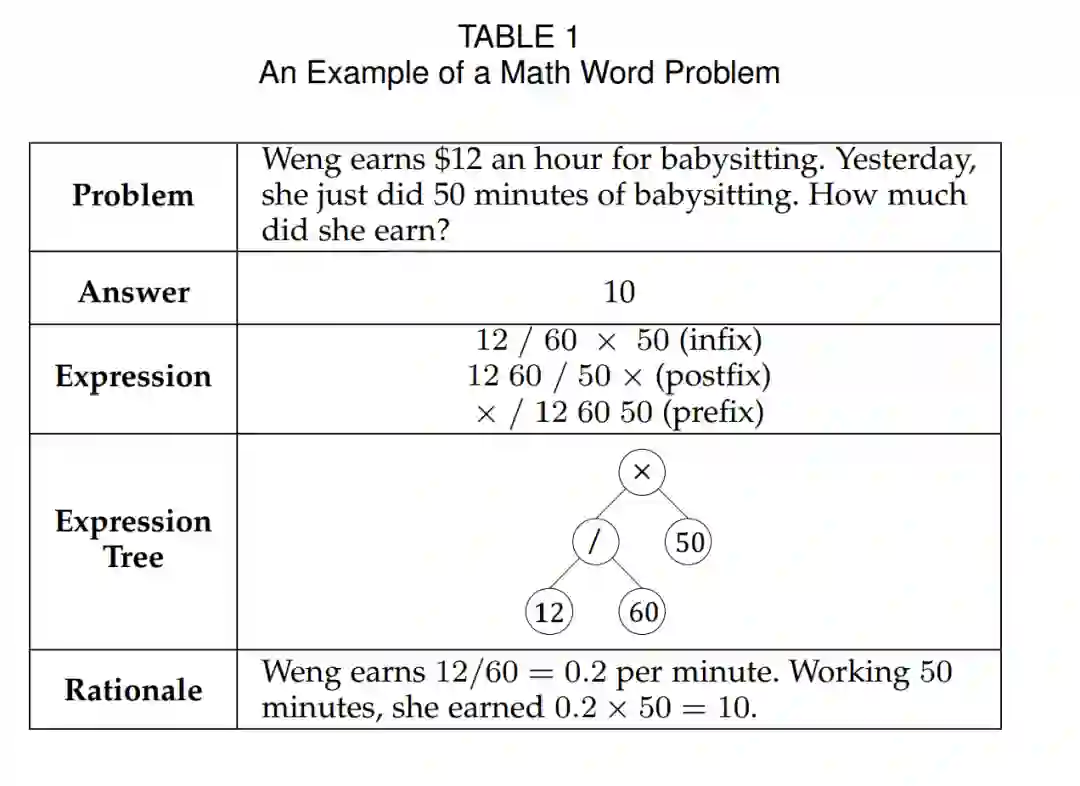
数学推理(Mathematical reasoning)是人类认知的基本组成部分,也是评估人工智能(AI)系统智能水平的重要基准 [1]。在众多数学任务中,数学文字题(Math Word Problems, MWPs) 作为一个基础性分支,自20世纪60年代以来一直是研究者持续关注的焦点 [2]。如表1所示,MWP求解通常要求模型先理解自然语言形式的问题文本,然后推理出相应的数学表达式或推理过程以得出答案。该过程模拟了若干人类基本认知功能,使得MWP成为研究与提升AI认知推理能力的重要试验场。 为解决这一任务,研究者提出了多种具有代表性的研究方法,其技术范式大致可分为三类。早期的MWP求解方法主要依赖人工编写的规则与模板来解析与求解问题 [3]。尽管这类方法在一定程度上有效,但其依赖预定义模式,缺乏处理现实世界中多样化与复杂语义问题的灵活性。近年来,深度学习(Deep Learning)已成为MWP研究的主流方法 [4]–[8],推动了多种创新性方法的出现,这些方法分别聚焦于问题求解流程的不同方面。 第一类研究致力于更好地建模问题文本中的信息 [9]–[11](例如,利用句法结构 [12])、整合外部知识(如常识知识 [13]、数学公式 [14], [15])或采用先进的预训练语言模型(如 BERT [16]、GPT [17]),以增强模型的理解能力。第二类研究则探索启发式推理模式,如树结构推理(Tree-Structured Reasoning) [18]–[20] 或 有向无环图(DAG)推理 [16], [21],以提升推理过程的可解释性与准确性。随着GPT-4等大语言模型(LLMs)在多个机器学习任务中取得卓越表现 [22]–[25],学界对其在MWP任务中的应用兴趣也日益增长 [26], [27]。 尽管该领域已有显著进展,一些学者也尝试通过综述推动MWP研究 [2], [28],但现有文献在技术与概念层面仍存在若干不足。技术层面,已有综述要么过时 [2](据我们所知,最新的MWP综述发表于2020年 [2]),主要聚焦于形式化语言推理并仅涵盖早期研究;要么范围过广 [28],讨论所有数学推理任务而未深入剖析MWP的具体发展脉络。概念层面,现有综述多从模型结构(如Seq2Seq模型、图结构模型)的技术视角总结研究进展,而未从MWP求解所需的类人智能能力(human-like intelligence capabilities)角度加以探讨。 作为一个历史悠久且基础性的研究主题,探索AI模型在MWP任务中所能达到的认知推理水平具有更深远的意义。尤其是对于LLMs,有研究指出其认知能力已接近8岁儿童的水平 [29]。然而,这些模型如何模拟人类智能仍是一个具有高度价值但尚未解决的开放性问题。特别是在求解复杂MWP时,如何真正复现人类的思维方式仍是一项有待深入探索的挑战。总体而言,目前尚缺乏一个系统的MWP综述分类框架,能够聚焦于技术推理能力的发展趋势。 本研究旨在填补这一空白——我们从人类认知视角系统审视MWP相关研究,全面梳理当前AI模型在模拟人类认知能力方面的进展,并揭示这些方法与人类智能之间的关联。这一视角不仅丰富了MWP领域的理解,也为构建具备更强数学推理能力的AI系统提供了启示。 具体而言,如图1所示,我们基于认知科学理论,总结了当前方法主要关注的五种关键认知能力:问题理解(Problem Understanding)、逻辑组织(Logical Organization)、联想记忆(Associative Memory)、批判性思维(Critical Thinking)与知识学习(Knowledge Learning)。我们的分析表明,现有研究主要集中于前两种基础能力——问题理解与逻辑组织,而较少涉及高阶认知能力,如知识学习与批判性思维。此外,由于LLMs在一定程度上整合了多种类人能力,我们对当前基于LLM的研究进行了深入回顾。我们发现,现有LLM工作在增强上述五种认知能力方面分布不均,这为未来通过引入更多认知能力进行优化提供了可行方向。 最后,鉴于当前MWP研究(无论小模型还是大模型)在基准数据集上尚未得到系统性评测,我们在本研究中对代表性的小规模模型、LLMs(如GPT-3.5与LLaMA3.1-8B)以及基于LLM的方法(如CoT [22]、ToT [30]、GoT [31]、PoT [32]、PAL [33])进行了全面实验评估,覆盖五个常用MWP数据集。 综上所述,本综述的贡献主要体现在以下三个方面: * 从认知能力的新视角系统回顾MWP研究,为评估现有AI模型的认知水平提供了重要参考; * 分析当前LLMs在MWP任务中的认知能力表现,为未来大模型的能力提升提供启示; * 在实验部分补充多种主流模型在五个基准数据集上的性能结果,涵盖14个小规模模型、4个代表性LLMs与10个最新LLM方法,清晰展示不同认知能力对推理准确性的影响。
本文其余部分组织如下:第二节介绍MWP任务定义并讨论涉及的五类人类认知能力;第三节基于认知能力对小规模模型进行分类;第四节总结LLMs在MWP任务上的研究;第五节介绍代表性MWP数据集并比较现有模型性能;第六节扩展讨论涉及其他认知能力的代表性数学推理任务;最后一节总结全文并提出MWP未来值得进一步研究的方向。

