

摘要——强化学习(Reinforcement Learning, RL)是解决序列决策问题的重要机器学习范式。近年来,得益于深度神经网络的快速发展,该领域取得了显著进展。然而,当前RL的成功依赖于大量训练数据和计算资源,且其跨任务泛化能力有限,制约了其在动态现实环境中的应用。随着持续学习(Continual Learning, CL)的兴起,持续强化学习(Continual Reinforcement Learning, CRL)通过使智能体持续学习、适应新任务并保留既有知识,成为解决上述局限性的重要研究方向。本文对CRL进行了系统梳理,围绕其核心概念、挑战和方法展开论述:首先,详细回顾现有研究,对其评估指标、任务设定、基准测试和场景配置进行归纳分析;其次,从知识存储/迁移视角提出新的CRL方法分类体系,将现有方法划分为四种类型;最后,剖析CRL的特有挑战,并为未来研究方向提供实践性见解。 关键词——持续强化学习,深度强化学习,持续学习,迁移学习
一、引言
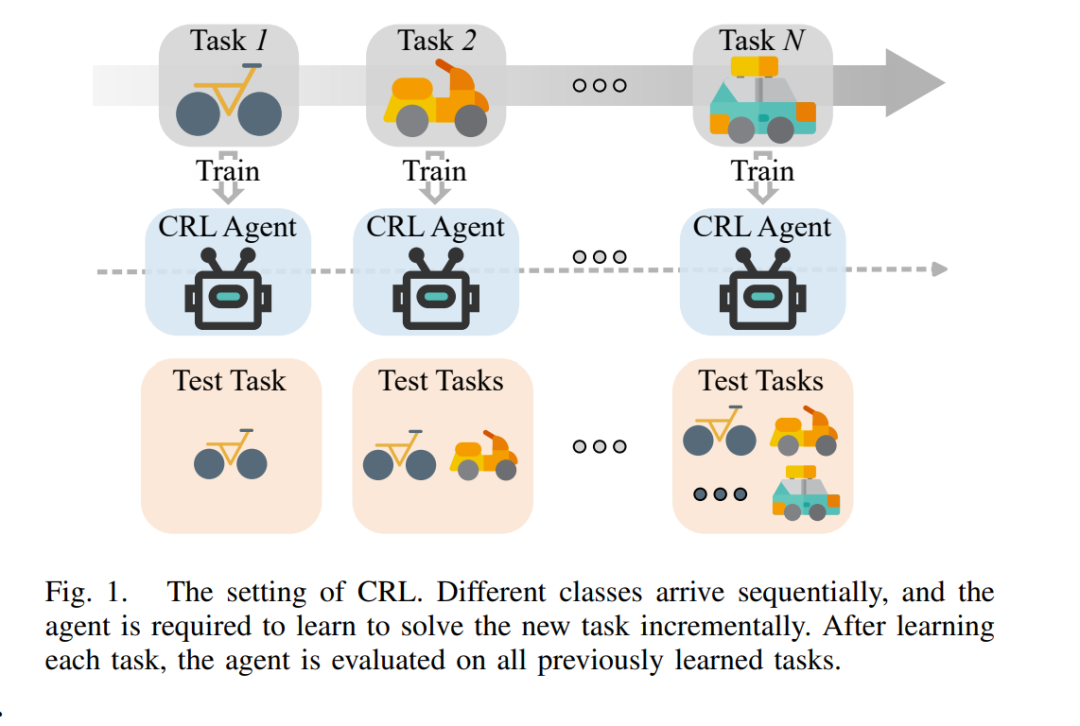
强化学习(Reinforcement Learning, RL)已成为机器学习中的一种强大范式,使智能体能够通过与环境的交互学习最优的决策策略 [1]。当强化学习与深度神经网络的表示学习能力相结合时,便产生了深度强化学习(Deep Reinforcement Learning, DRL),其在多个领域取得了显著的成功 [2]。DRL 展现了在解决高维复杂决策问题方面的巨大潜力,从精通国际象棋、日本将棋和围棋等棋类游戏 [3],到推动科学发现,如蛋白质结构预测 [4]、量子计算误差校正 [5],以及大型语言模型的训练 [6],[7]。此外,DRL 也被广泛应用于现实世界中的控制任务,如热电联产系统优化 [8]、托卡马克核聚变反应堆中等离子体配置控制 [9],以及实现安全的自动驾驶 [10]。 尽管 DRL 已取得诸多成就,但其当前的成功主要归因于在特定任务上学习固定策略的能力,通常需要大量的训练数据和计算资源 [11]。这为 DRL 在现实应用中的部署带来了重大挑战。具体来说,现有的 DRL 算法普遍缺乏跨任务高效迁移知识或适应新环境的能力。面对新任务时,这些算法通常需要从头开始学习,导致样本效率低下以及泛化能力差 [12]–[14]。 为应对上述挑战,研究人员开始探索如何使 RL 智能体避免灾难性遗忘并有效迁移知识,其最终目标是推动该领域向更具类人智能的方向发展。人类在解决新任务时,能够灵活地利用已有知识,同时不会显著遗忘已掌握的技能 [15]。受到这一能力的启发,持续学习(Continual Learning, CL),又称终身学习或增量学习,旨在构建能够适应新任务并保留过往知识的学习系统 [16]–[19]。CL 面临的核心挑战在于稳定性与可塑性的平衡——即在维持已学知识稳定性的同时,又具备足够的灵活性来适应新任务。其总体目标是构建能在整个生命周期内持续学习和适应的智能系统,而不是每次面对新任务时都从零开始。当前 CL 的研究主要聚焦于两个方面:灾难性遗忘的缓解以及知识迁移的实现。灾难性遗忘指的是学习新任务会导致模型覆盖并遗失先前已学任务的知识;而知识迁移则是指利用过往任务中积累的知识来提升新任务(甚至是已见任务)的学习效率与表现。成功解决这两个问题对于构建稳健的持续学习系统至关重要。 持续强化学习(Continual Reinforcement Learning, CRL),又称终身强化学习(Lifelong Reinforcement Learning, LRL),是 RL 与 CL 的交叉领域,旨在突破当前 RL 算法的多种局限,构建能够持续学习并适应一系列复杂任务的智能体 [20],[21]。图 1 展示了 CRL 的基本设置。与传统 DRL 主要聚焦于单一任务性能最优化不同,CRL 更强调在任务序列中保持并增强泛化能力。这种焦点的转变对于将 RL 智能体部署于动态、非平稳环境中尤为关键。 需要指出的是,“lifelong” 与 “continual” 两个术语在 RL 文献中常被交替使用,但不同研究中的定义与使用方式可能存在显著差异,从而引发混淆 [22]。一般而言,大多数 LRL 研究更强调对新任务的快速适应,而 CRL 研究更关注避免灾难性遗忘。本文采用更广义的 CRL 作为统一术语,呼应当前 CL 研究中同时兼顾这两个方面的趋势。 CRL 智能体需实现两个核心目标:(1)最小化对先前任务知识的遗忘;(2)利用已有经验高效学习新任务。达成这两个目标将有助于克服 DRL 当前的局限,推动 RL 技术向更广泛、更复杂的应用场景拓展。最终,CRL 旨在实现类人的终身学习能力,使其成为推动 RL 研究的重要方向。 目前,关于 CRL 的综述工作仍相对较少。部分综述文献 [18],[23] 对 CL 领域进行了全面回顾,包括监督学习与强化学习。值得注意的是,Khetarpal 等人 [21] 从非平稳 RL 的视角对 CRL 进行了综述,首先对通用 CRL 问题进行了定义,并通过数学刻画提出了不同 CRL 形式的分类体系,强调了非平稳性所涉及的两个关键属性。然而,该综述在 CRL 中的一些重要方面——如挑战、基准测试与场景设置等——缺乏详细的对比与讨论,而这些因素对于指导实际研究至关重要。此外,过去五年中 CRL 方法数量快速增长。鉴于此,本文旨在系统回顾近年来关于 CRL 的研究工作,重点提出一种新的 CRL 方法分类体系,并深入探讨知识在 CRL 中的存储与迁移机制。 本综述深入探讨了 CRL 这一不断发展的研究领域,旨在弥合传统 RL 与现实动态环境需求之间的差距。我们全面审视了 CRL 的基本概念、面临的挑战与关键方法,系统性地回顾了当前 CRL 的研究现状,并提出了一套将现有方法划分为不同类别的新分类体系。该结构化方法不仅清晰地描绘了 CRL 研究的整体图景,也突出了当前的研究趋势与未来的潜在方向。我们还从策略、经验、动态与奖励等多个角度审视方法间的联系,为优化 CRL 的学习效率与泛化能力提供了细致的理解。此外,我们也关注推动 CRL 边界的新兴研究领域,并探讨这些创新如何助力构建更复杂的人工智能系统。 本综述的主要贡献体现在以下几个方面: 1. 挑战分析:我们强调了 CRL 所面临的独特挑战,提出其需要在可塑性、稳定性与可扩展性三者之间实现平衡; 1. 场景设定:我们将 CRL 场景划分为终身适应、非平稳学习、任务增量学习与任务无关学习,为不同方法提供了统一的对比框架; 1. 方法分类:我们提出了一种基于知识存储与迁移方式的新 CRL 方法分类体系,涵盖策略导向、经验导向、动态导向与奖励导向方法,帮助读者结构性地理解 CRL 策略; 1. 方法综述:我们对现有 CRL 方法进行了最全面的文献回顾,包括开创性工作、最新发表的研究成果以及有前景的预印本; 1. 开放问题:我们讨论了 CRL 当前的开放问题与未来研究方向,如任务无关的 CRL、评估与基准建设、可解释知识建模以及大模型的集成使用。
表 I 展示了本文的结构安排。接下来的内容如下:第二节介绍 RL 与 CL 的基础背景,有助于理解 CRL 的核心理念;第三节概述 CRL 的研究范畴,包括定义、挑战、评价指标、任务设置、基准与场景分类;第四节详细介绍我们提出的 CRL 方法分类体系,并回顾现有方法,按知识类型划分为策略导向(第四节 B)、经验导向(第四节 C)、动态导向(第四节 D)与奖励导向(第四节 E)四类;第五节探讨 CRL 的开放问题与未来发展方向;第六节为本文的总结与展望。
