

多智能体强化学习(MARL)算法被广泛应用于处理动态多智能体系统(MAS)中需要智能体之间协作和竞争的复杂任务。然而,从头开始学习这类任务是非常艰巨的,而且可能并不总是可行,特别是对于具有大量交互智能体的 MAS 而言,这是因为样本复杂性很大。因此,重新利用从过去的经验或其他智能体中获得的知识,可以有效地加快学习过程,提升 MARL 算法的水平。在本研究中,我们引入了一个新颖的框架,通过将各种状态空间统一为固定大小的输入,使一个统一的深度学习策略在 MAS 的不同场景中都可行,从而实现 MARL 的迁移学习。我们在 "星际争霸多智能体挑战赛"(SMAC)环境中的一系列场景中评估了我们的方法,结果表明,与从头开始学习的智能体相比,利用从其他场景中学到的操纵技能,多智能体的学习性能有了显著提高。此外,我们还采用了 "课程迁移学习"(CTL),使我们的深度学习策略能够在预先设计好的按难度等级组织的同质学习场景中逐步获取知识和技能。这一过程促进了智能体之间和智能体内部的知识转移,从而在更复杂的异构场景中实现较高的多智能体学习性能。
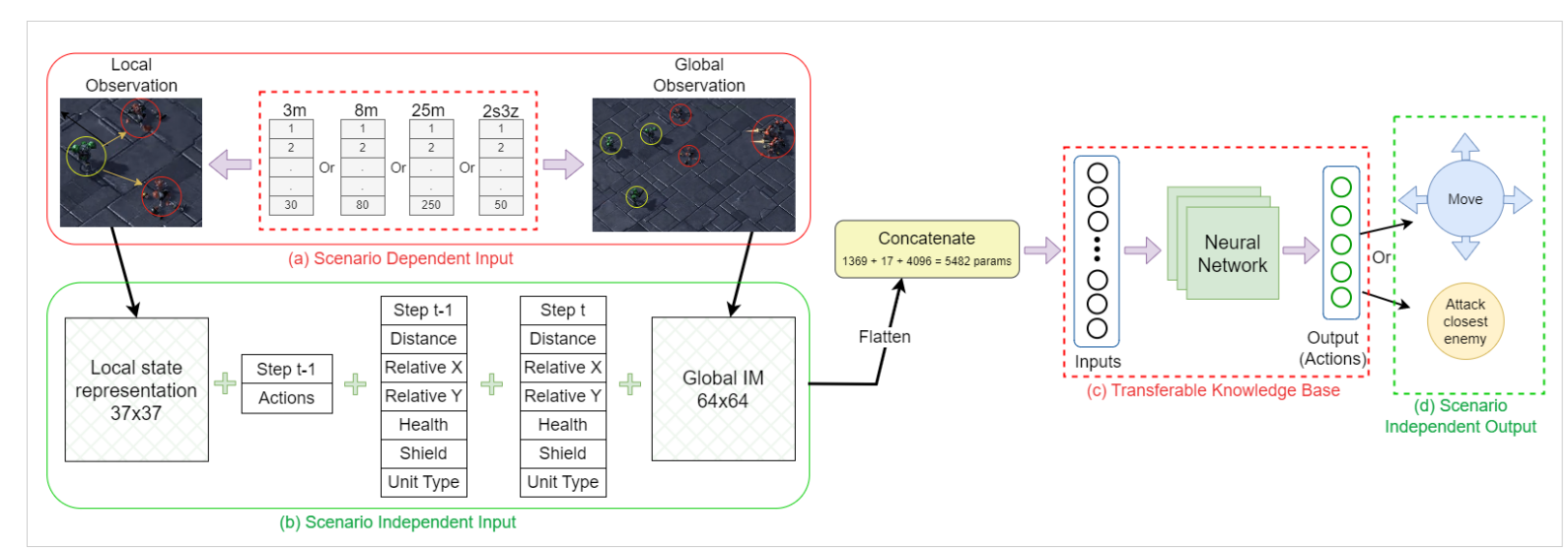
图3:单个单元的迁移学习模型表示
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日