

本论文探讨了视频理解中学习视频表示的问题。先前的工作已经探索了使用数据驱动的深度学习方法,这些方法已被证明在学习有用的视频表示方面是有效的。然而,获取大量标注数据可能既昂贵又耗时。我们研究自监督学习方法,用于多模态视频数据以克服这一挑战。视频数据通常包含多种模态,如视觉、音频、转录的语音和文本字幕,这些可以作为伪标签用于表示学习,而无需手动标注。通过利用这些模态,我们可以在由互联网收集的数以百万计的视频剪辑组成的大规模视频数据上训练深层表示。我们展示了多模态自监督的可扩展性优势,通过在各个领域实现新的最先进性能,包括视频动作识别、文本到视频检索和文本到视频定位。
我们还检查了这些方法的限制,这些方法通常依赖于在自监督中使用的数据的多个模态之间的关联假设。例如,通常假设文本转录是关于视频内容的,同一视频的两个片段共享相似的语义。为了克服这个问题,我们提出了新的方法来学习视频表示,这些方法采用更智能的采样策略来捕获共享高层语义或一致概念的样本。提出的方法包括一个聚类组件,以解决多模态配对对比学习中的假负对问题,一种寻找可视化定位的视频-文本对的新采样策略,对于时序关联的物体跟踪监督的调查,以及展示所提模型有效性的新多模态任务。我们的目标是为真实世界应用开发更健壮和可泛化的视频表示,如人与机器人的交互和从大规模新闻源中提取事件。
视频理解是计算机视觉中一个具有挑战性的研究领域,旨在分析和推理视频内容。虽然图像包含静态帧,但视频提供了包括运动、动态场景和各种视角在内的丰富信息。然而,处理视频由于其大容量高维数据而需要显著的计算和存储资源。对于这些理解任务而言,视频的表示至关重要,因为它们允许我们识别视频中的高层概念,如各种对象执行的不同动作和事件之间的时间关系。
深度学习的最近进展,特别是卷积神经网络,在学习视频编码方面取得了巨大成功,这种编码正式称为深度表示。这些模型提取输入数据的有用属性,代表了视频的一般性质。然而,大多数用于视频表示的最先进模型依赖于大型、精心标注的数据集进行训练。此外,视频注解既昂贵又耗时,因为很难标注时间边界和定义事件的标签类别。
为了克服这些限制,自监督学习已经成为视频理解的一个有前途的方向【1, 2, 3】。与其依赖人工注释的标签进行特定任务,自监督学习旨在通过前置任务学习表示,例如预测已被隐藏的数据部分或区分与彼此相关联的数据对与随机配对的数据。假设是通过完成这些任务,模型发展出一定的视觉理解能力,结果产生有意义的表示,这反过来可以用于各种下游任务。这种方法允许更大规模的训练,不同领域的可访问性,并避免了标签的模糊性【4】。
1.2 多模态视频自监督学习的动机
近年来,图像领域的自监督学习取得了巨大成功,并已显示出在各种下游任务(如图像分类和对象检测【5, 6】)上超越了有监督预训练的表现。然而,出于几个原因,仅从图像学习存在其局限性。首先,图像是静态的,这意味着它们无法捕捉因果和时间信息。此外,图像作为单一模态的表示,在现实世界中数据本身可能是损坏的或噪声很大。更进一步,图像自监督学习经常依赖于某些形式的人为定义的数据增强,如裁剪、旋转和模糊,这意味着其监督并非自然存在。
相比之下,视频捕捉了时间动态和自然存在的多模态监督,如光流、音频和ASR文本。互联网上的视频,如YouTube,提供了音频和ASR字幕,可用于定义涉及多模态内容的自监督任务。从这样的多模态监督学习已成为一个有前景的学习流程,以从零开始训练神经网络,无需人工注释。此外,从多模态数据学习的好处是创建跨模态的共同空间,其中如语音和文本这样的模态提供了捕获更高级别语义概念的机会。随着多模态表示的最近成功,如CLIP【7】,通过匹配视觉内容和共享的共同空间中的可能标签,可以免费执行识别任务。 在本论文中,我们专注于开发学习这种多模态共同空间的模型,其中模型不需要对人为定义的标签进行微调。我们的目标是利用视频中可用的多模态自监督,提高模型在真实世界场景中的鲁棒性和泛化能力。
1.3 从多模态自监督学习概述
本论文主要关注通过多模态自监督学习表示的任务。在本节中,我们将讨论这一领域的最新进展以及我们的工作与之如何相关。自监督学习是一种从数据学习表示的强大方法。然而,如图3.1所示,需要考虑几个关键组成部分,包括数据、模型、学习目标和下游评估。 数据。我们需要考虑数据的两个重要方面:数据转换(增强)和从不同领域学习。数据转换是图像基础自监督学习【6】的关键,应用于图像的不同数据增强,如随机裁剪、高斯模糊、旋转和颜色抖动。模型将同一数据点的不同转换视为相同的实例。自监督任务的目标是将转换后的数据映射到学习到的表示空间中的原始数据。在视频中,不同的速度【8】和数据顺序的洗牌【9】可能作为数据的额外转换。这些数据转换作为编码在学习表示中的不变性和独特性的先验。本论文探索了视频数据可能的丰富数据转换空间,并将其用于多模态自监督表示学习。我们探索的一个关键数据转换是从视频输入捕获的对象的视点变化和遮挡(第4章)。我们还探索了如自动语音识别输出(第2、3、5章)、音频(第2、3章)和相应文章(第5章)等其他模态,可以作为表示学习的强大数据增强。
我们还探索了用于表示学习的不同数据领域。先前的工作主要集中在从具有固定预定义标签类集的视频数据集(如Kinetics-400【10】和Audioset【11】)学习视频表示。此外,我们调查了如HowTo100M【12】和WebVid-2M【13】这样的大规模多模态数据集用于表示学习的潜力。特别是,HowTo100M数据集【12】收集了带有相应音频的视频,并在2019年自动通过YouTube ASR API生成文本转录,当时ASR工具的字错误率(WER)为28%【14】。在本论文中,(第2和3章)实验中使用的文本转录来自HowTo100M数据集【12】中提供的ASR。此外,我们采样了带有ASR输出的视频片段,起止时间由ASR界定,结果是遵循【2, 12】的3-10秒视频。通过使用多模态自监督,我们能够绕过收集这些数据集的语义标签的需要,而是利用音频和文本模态中存在的免费监督。特别是,我们探索了文本不太可能与视频相关的新闻领域,并显示了在足够大的数据规模下,我们可以在开放域数据集上进行表示学习,以训练视频表示,实现强大的事件和论元角色标注性能(第5章)。在这个数据集中,我们在2021年应用了YouTube ASR,其WER为20.6%【15】。
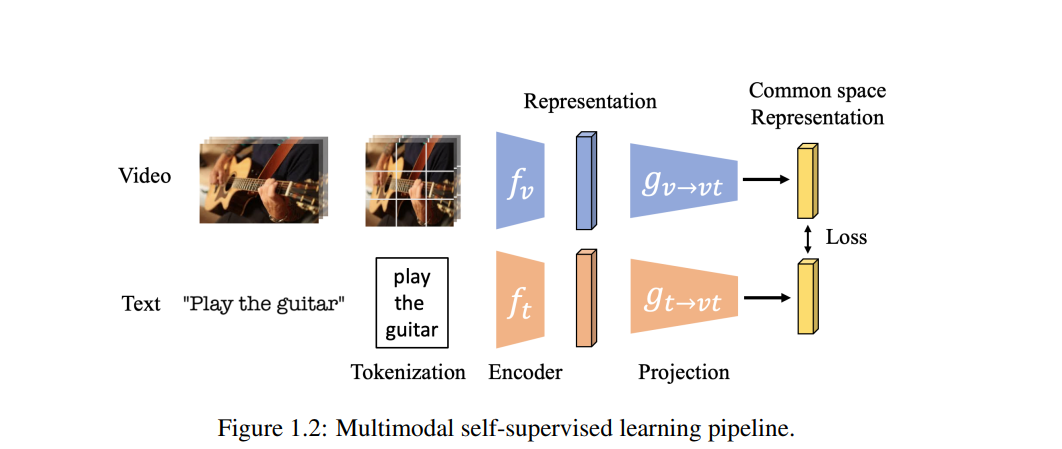
模型。模型将输入数据映射到数据表示。在多模态自监督的情况下,通常使用分词器将视频处理成补丁和句子分词,然后是每种模态的编码器,如图1.2所示。传统上,视频表示是通过使用2D卷积神经网络【16】的基于帧的编码提取的,通过平均池化或NetVLAD【17】聚合时间来获得随时间的基于帧的特征。最近,视频表示是通过3D卷积神经网络【18】提取的,以编码短期时间动态。这两种架构旨在编码视频的短期和长期时间信息。在本论文中,我们应用了广泛使用的视频编码器主干S3D【19】,R(2+1)D【20】,C3D【21】进行多模态自监督学习。对于文本模型,word2vec【22】和BERT模型【23】被广泛用于编码单词和句子级表示。对于音频模型,原始音频【3】或对数梅尔频谱图【24】被用作输入到ResNet【2】和DaveNet【25】。
Transformers [26] 在自然语言处理(NLP)领域通过其多头注意力和编码器-解码器架构来计算序列的上下文化表示而取得了巨大成功。在本论文中,我们展示了多模态学习可以从使用联合多模态Transformers(第5章)来计算视频和文本的多模态上下文表示中受益,而不是使用每种模态的独立编码器。我们展示了Transformers架构对于在提取的视觉表示之上编码时间信息以更好地进行多模态表示在事件提取(第2章)和零样本任务中的共同空间学习(第2章)中是有用的。编码器学习的表示可以用一个向量[1]表示。在Transformers模型编码器中,视频的时空表示和文本表示之间的维度基本保持一致[27]。
每种模态的编码器之后,我们学习将每种模态的表示投影到一个共同空间的网络,使得表示可以直接比较,如图1.2所示。这个网络通常实现为一个或两个线性层进行投影[28, 1, 3]。损失函数。损失函数的选择对于学习强大的视频表示至关重要。损失函数驱动学习过程,并且是自监督学习流程的关键组成部分。传统上,在多模态自监督学习设置中使用二元交叉熵或三元组(最大间隔)目标[29]。这些损失鼓励表示将来自同一视频片段的视觉和听觉数据对与其他对区分开。最近,噪声对比训练[30]在学习自监督图像表示[6, 5]中变得流行,其中模型通过将同一实例的不同数据增强拉近并将不同实例推远来学习区分能力。在本论文中,我们探索了如何在多模态设置中适应噪声对比训练,用于视频-文本(第5章)和视频-音频(第2章和第3章)表示学习。我们展示了这个损失对于在各种领域和任务中学习强大的视频表示至关重要(第5章)。另一方面,基于聚类的表示学习是在单位球上学习一个嵌入,以在最大化选定的目标函数的同时优化聚类。在[31]中,开发了一种简单的交替程序,通过在聚类结果导出的伪标签和基于k-means聚类分配伪标签之间切换来训练模型。引入前面提到的变换使网络对这些变换变得不变,并且通常通过提取和放大初始特征提取器(一个随机初始化的神经网络)来实现。在本论文中,我们在此基础上进行了扩展到多模态,其中我们学习预测多模态聚类中心以更好地进行共同空间学习(第2章)。
性能评估。通常,有两种不同的评估训练模型的方法[32]:通过微调权重或保持模型的权重冻结。对于前者,预训练模型在一些人类标注的数据集上进一步优化,如UCF-101[33]、HMDB-51[34]和Kinetics-400[10]用于动作分类,其中报告了准确率。对于后者,训练模型被冻结,通常只添加一个弱模型,如线性分类器,并在一些标注的数据集上训练。对于视频数据集,评估在UCF-101[33]和HMDB-51[34]上进行,并且还包括基于最近邻的类别检索。也可以在不进一步训练线性层的情况下进行评估:单独的表示被保存,执行k最近邻(kNN)检索[35]。在视频和文本都可用的多模态场景中,可以冻结编码器和投影层,并在MSR-VTT[36]、VATEX[37]、YouCook[38]等数据集上执行文本到视频检索,并且通常报告不同邻域级别的性能。注意,在评估期间,与训练时提供ASR转录到文本分支不同,提供了人工注释的文本描述。在我们开发的Video M2E2数据集中(见第5章),可以通过跨模态的特征相似度计算完成事件提取和论元角色标注(第5章)。此外,我们可以在没有任何微调的情况下,使用冻结的模型从文本到时空区域进行定位(第3章)。




