视觉-语言-动作(Vision-Language-Action, VLA)模型标志着人工智能领域的一项变革性进展,旨在在一个统一的计算框架中融合感知、自然语言理解与具身动作执行。本文作为一篇基础性综述,围绕该快速演进领域的五大主题支柱,对近期 VLA 模型的发展进行了系统性梳理与综合分析。 我们首先建立了 VLA 系统的概念基础,回顾其从跨模态学习架构演变为深度整合视觉-语言模型(VLMs)、动作规划器和层级控制器的通用智能体的过程。本文采用严格的文献综述方法,覆盖了过去三年内发表的80余种 VLA 模型。
关键进展涵盖了架构创新、参数高效的训练策略以及实时推理的加速方法。我们还系统探讨了 VLA 模型在多种应用领域中的实践,包括类人机器人、自动驾驶、医疗与工业机器人、精准农业以及增强现实导航等。 此外,本文还深入分析了该领域面临的主要挑战,如实时控制、多模态动作表示、系统可扩展性、对未见任务的泛化能力,以及伦理部署风险等。基于当前技术前沿,我们提出了若干应对方案,包括智能体型人工智能(agentic AI)适配、跨具身泛化以及统一的神经-符号规划(neuro-symbolic planning)。
在前瞻性讨论部分,我们描绘了一个未来蓝图:VLA 模型、VLMs 与 agentic AI 相互融合,共同驱动具备社会适应性、灵活性和通用性的具身智能体系统。本文旨在为推进智能化、现实世界机器人系统与通用人工智能(AGI)发展提供一个基础性参考。
关键词:视觉-语言-动作、VLA、人工智能、机器人、视觉-语言模型、AI 智能体、智能体型人工智能
1. 引言
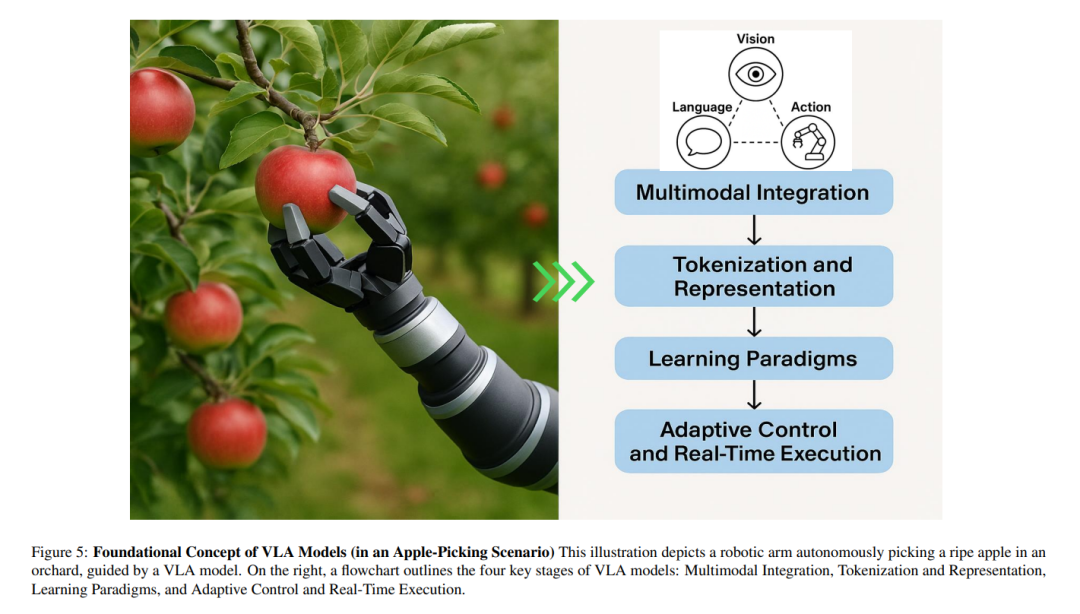
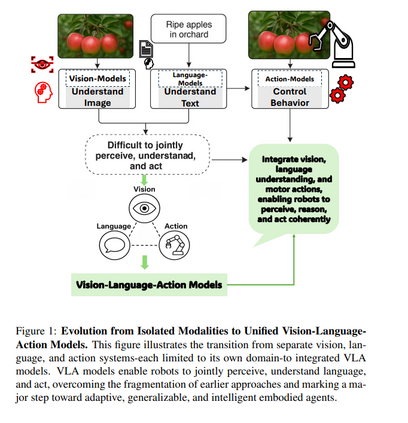
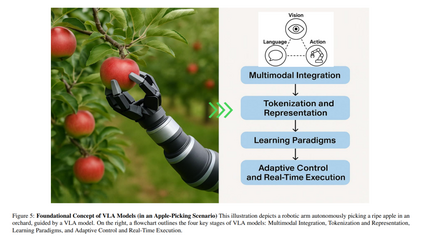
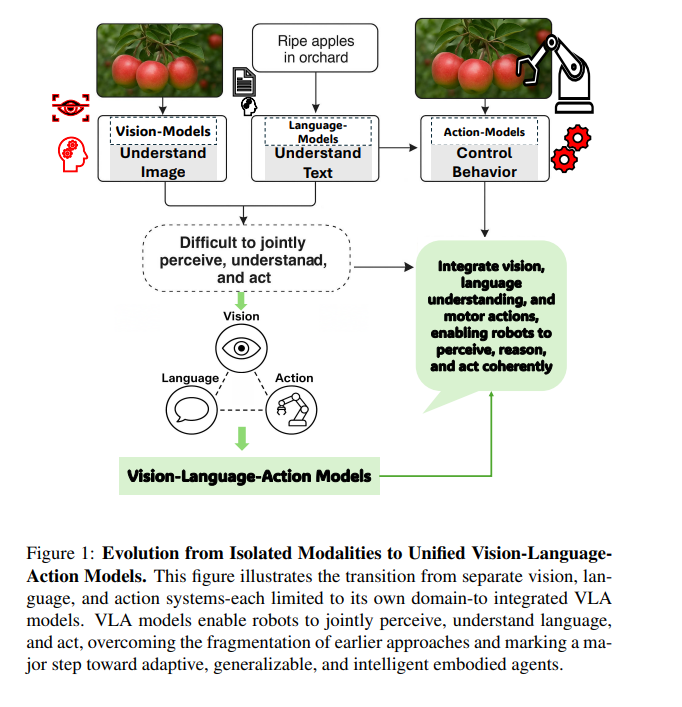
在视觉-语言-动作(Vision-Language-Action,VLA)模型出现之前,机器人技术和人工智能的进展主要分布在彼此割裂的几个子领域:视觉系统能够“看”并识别图像 [44, 69];语言系统能够理解和生成文本 [164, 137];动作系统则能够控制物体运动 [49]。这些系统在各自领域表现良好,但在协同工作或应对新颖、不可预见的情况时表现乏力 [46, 21],从而限制了它们理解复杂环境或灵活应对真实世界挑战的能力。 如图1所示,传统计算机视觉模型(主要基于卷积神经网络 CNNs)通常针对如目标检测或分类等窄域任务进行优化,严重依赖大量标注数据,且即便是环境或任务目标的微小变化也需耗费大量精力进行重新训练 [156, 62]。这些视觉模型虽然具备“看”的能力(例如识别果园中的苹果),但无法理解语言或将视觉洞察转化为有目的的动作。 另一方面,语言模型,尤其是大型语言模型(LLMs),在文本理解与生成方面取得了革命性进展 [23],但它们依然局限于语言模态,缺乏对物理世界的感知与推理能力 [76](如图1中“果园中的成熟苹果”一例所示)。与此同时,动作系统在机器人中的应用,主要依赖手工设计的策略或强化学习方法 [122],虽可实现特定行为(如操控物体),但通常难以泛化,且开发成本高昂 [119]。 尽管视觉-语言模型(VLMs)通过融合视觉与语言实现了令人印象深刻的多模态理解 [149, 25, 148],但系统在生成或执行连贯动作方面依然存在显著的集成缺口 [121, 107]。如图1进一步所示,大多数 AI 系统至多只能融合两种模态(如视觉-语言、视觉-动作或语言-动作),而难以在统一框架中整合三者。结果是,机器人可以识别物体(如“苹果”),理解相应的文本指令(如“摘下苹果”),或执行预定义的动作(如抓取),但要将这些能力整合为流畅且具适应性的行为仍十分困难。这导致系统架构呈碎片化特征,难以适应新任务或新环境,泛化能力弱,开发过程繁琐,成为具身智能发展的关键瓶颈:如果系统无法同时感知、理解并采取行动,真正的智能自主行为将无从谈起。 这一迫切需求促使 VLA 模型的兴起。VLA 模型构想于 2021-2022 年,并在 Google DeepMind 的 Robotic Transformer 2(RT-2) [224] 等研究工作中得到率先实践,提出了一种将感知、推理与控制统一于单一架构的变革性方法。作为图1中所揭示限制的解决方案,VLA 模型整合了视觉输入、语言理解与运动控制能力,使具身智能体能够感知环境、理解复杂指令并动态地执行相应动作。 早期的 VLA 方法通过在视觉-语言模型中引入动作标记(action tokens)——即用于表示机器人动作指令的数值或符号形式,实现了这种三模态融合。模型可借助配对的图像、语言与轨迹数据进行训练 [121],大幅提升了机器人对未见物体的泛化能力、对新颖语言指令的解释能力,以及在非结构化环境中的多步推理能力 [83]。 VLA 模型在实现统一多模态智能的道路上迈出了关键一步,打破了长期以来视觉、语言与动作分立建模的局限 [121]。借助大规模互联网级数据集,这些数据集整合了图像、文本与行为信息,VLA 模型不仅能够识别与描述环境,还可以进行语境推理并在复杂、动态的场景中执行合适的动作 [196]。如图1所展示,从各模态割裂的孤立系统发展到集成式的 VLA 模型,标志着朝着真正具备适应性与泛化能力的具身智能体迈出了根本性的一步。 鉴于该范式转变具有深远影响,亟需开展一项系统、深入的综述研究,基于丰富的文献资料与批判性分析,全面梳理 VLA 模型的发展: 1. 首先,该综述有助于明确 VLA 的基本概念与架构原则,从而区分其与以往多模态系统的本质差异; 1. 其次,梳理该领域快速发展的进程与关键技术节点,帮助研究人员与从业者把握其技术演进路径; 1. 第三,深入探讨 VLA 在现实世界中已展现变革潜力的多个应用场景,如家庭机器人、工业自动化、辅助技术等; 1. 第四,分析当前亟待解决的挑战,包括数据效率、安全性、泛化能力及伦理风险等,为未来部署提供指导; 1. 第五,通过综合这些研究洞见,向更广泛的 AI 与机器人研究社群传达新兴研究方向与工程考量,促进协同创新。
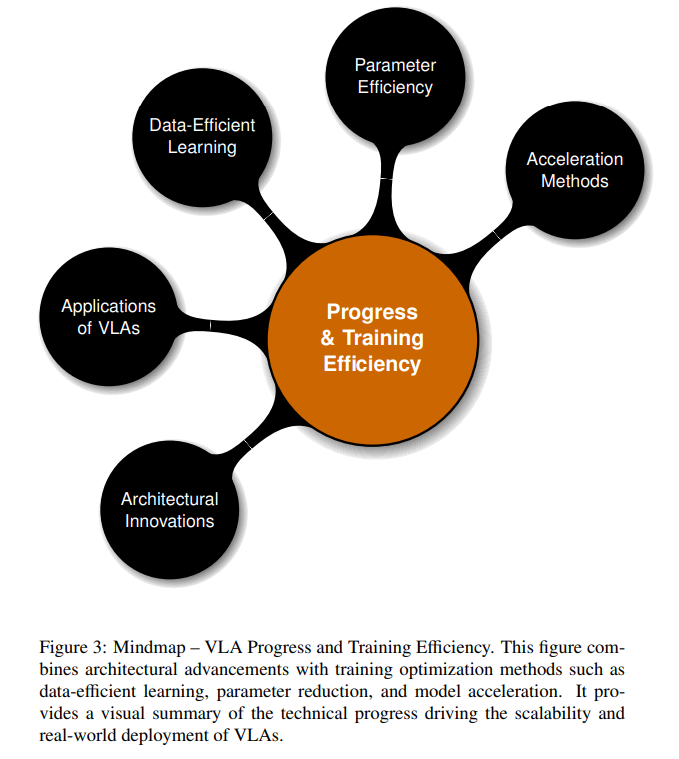
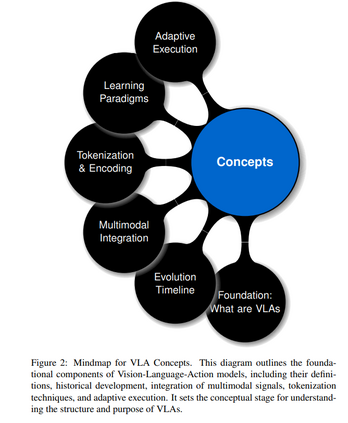
本综述系统分析了 VLA 模型的概念基础、发展进展与技术挑战,旨在凝聚当前研究成果,明确尚存的技术瓶颈,并提出未来的研究方向。 我们首先将深入剖析 VLA 模型的核心概念(图2),包括其构成要素、历史演化、多模态融合机制以及基于语言的编码策略,这些内容为理解 VLA 在模态间的协调提供了基础。 在此基础上,我们梳理了近年来的技术进展与训练效率策略(图3),涵盖使 VLA 更具泛化能力的架构创新、数据高效学习机制、参数优化建模方法及推理加速技术。这些进展对实现 VLA 在现实环境中的应用至关重要。 接着,我们全面讨论了当前 VLA 系统所面临的关键挑战(图4),包括推理瓶颈、安全问题、计算资源开销、有限的泛化能力及伦理风险。我们不仅指出了这些问题,还从分析角度提出了潜在解决思路。 上述三幅图共同构建了本综述的视觉化框架,辅助文本内容展示其概念图景、创新亮点与亟待解决的问题。本综述旨在为未来的研究提供指导,促进更加稳健、高效、伦理的 VLA 系统的发展。