

最近,大型语言模型(LLMs)在理解和零次学习文本数据方面展现出了卓越的能力,为许多与文本相关的领域承诺了重大进步。在图领域,各种现实世界的情景也涉及文本数据,其中任务和节点特征可以通过文本来描述。这些具有文本属性的图(TAGs)在社交媒体、推荐系统等方面有广泛的应用。因此,本文探讨了如何利用LLMs来建模TAGs。之前对TAG建模的方法基于百万级别的语言模型。当扩展到十亿级别的LLMs时,它们在计算成本方面面临巨大挑战。此外,它们还忽略了LLMs的零次推理能力。因此,我们提出了GraphAdapter,它使用图神经网络(GNN)作为与LLMs合作的高效适配器来处理TAGs。在效率方面,GNN适配器只引入了少量可训练参数,并且可以以低计算成本进行训练。整个框架使用自回归在节点文本上(下一个令牌预测)进行训练。一旦训练完成,GraphAdapter就可以通过任务特定的提示进行微调,以适应各种下游任务。通过在多个现实世界的TAGs上进行广泛的实验,基于Llama 2的GraphAdapter在节点分类方面平均改进了约5%。此外,GraphAdapter还可以适应其他语言模型,包括RoBERTa、GPT-2。这些有希望的结果表明,GNNs可以作为LLMs在TAG建模中的有效适配器。
图在现实世界中无处不在[1]。过去,图结构在许多机器学习应用中得到了广泛的探索和利用[27, 39]。在许多实际情况中,图中的节点具有文本特征,这被称为具有文本属性的图(TAGs)[37]。例如,在社交媒体[18]中,节点代表用户,节点特征是用户资料。TAGs中的节点既有文本数据也有结构数据,这两者都反映了它们的内在属性。将文本和结构数据结合起来对TAGs进行建模,是图机器学习和语言建模都在探索的一个令人兴奋的新方向,这可以促进图的应用。在TAGs中,节点的结构和文本数据之间存在复杂的相关性。理解这种相关性可以促进TAGs的建模[5]。在图1中,用户“Bob”经常在社交媒体上浏览每日新闻,这一点从他的用户资料中的描述中可以得到证实。类似于Bob的用户,他们有许多关注者并且经常浏览新闻节点,也可能对新闻感兴趣。换句话说,图可以通过结构邻近性补充节点上的文本属性。图神经网络(GNNs)是利用TAGs中的文本信息和图结构的事实上的机器学习模型。然而,缺乏一个与不同语言模型兼容的统一GNN架构,尤其是强大的基础模型。 最近,研究人员积极探索有效模拟具有文本属性的图(TAGs)中文本和结构数据的方法。其中一些研究强调了优化级联架构,该架构结合了图神经网络(GNNs)和语言模型(LMs)(级联GNN-LMs)[37, 42]。这些模型的一个主要挑战是消息传递机制带来的额外计算成本极高。为此,几项研究通过冻结主干语言模型的部分或全部参数,成功减少了这类级联模型的内存和计算开销[20, 25]。大型语言模型在各种实际应用中展现出卓越的多任务和少次学习能力[2]。然而,当考虑级联GNN-LMs时,现有技术无法扩展到像Llama 2这样的十亿级模型[33]。另一项开创性研究尝试使用无监督图信息(自监督学习GNN-LMs)对语言模型进行微调[4, 26]。例如,GIANT[4]通过邻居预测任务微调语言模型,随后使用精炼的语言模型提取节点表示以用于下游任务。在这些方法中,预训练语言模型(PLMs)可以在调优过程中间接整合图信息,从而提升其处理TAGs的能力。然而,它们将GNNs和LMs的训练分开,可能导致次优的图感知调优结果。
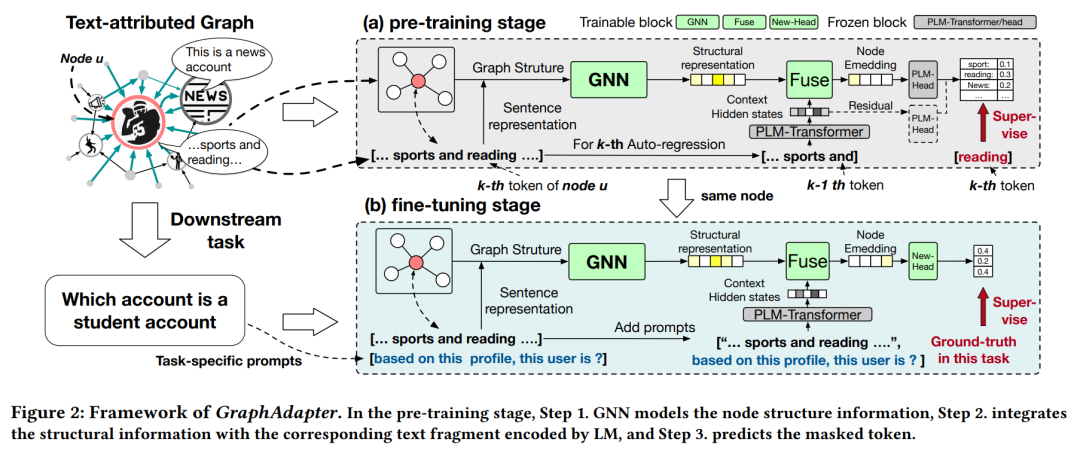
我们认为,与其使用图信息作为监督,不如利用图结构通过语言建模丰富文本特征。在我们之前的例子中,可以使用结构邻近性来推断用户的偏好,即使他或她没有在个人资料中提及。因此,与自监督学习方法不同,我们考虑预训练一个框架,该框架可以通过利用丰富的文本特征,结合图感知结构和LLMs。然而,传统的框架,如级联GNNs和LLMs,在预训练场景中面临效率问题。因此,受到对LLMs进行参数高效调优工作的启发[14, 22, 23],我们提议使用GNNs作为LLMs的高效适配器(即GraphAdapter)。在GraphAdapter中,LM被冻结,LM的最终输出通过可训练的适配器GNNs进行修改。GraphAdapter提供了几个优势: * 轻量级:GNN适配器引入了少量可训练参数和低计算成本。 * 语言感知的图预训练:使用语言指导图结构的建模,这可以帮助LLMs理解文本和结构信息。 * 方便的调优:一旦预训练了特定于图的适配器,它可以被微调用于多个下游任务。
现在,我们提出GraphAdapter的详细信息,关于适配器GNNs的预训练和微调。为了捕获图的数据分布,我们在节点文本上对LLMs进行参数高效的调优。这种方法类似于语言模型的持续训练[31],除了GNN是调优参数,这有助于减少预训练语料库和目标数据之间的分布差异。为了进一步提高效率,我们专门在变换器的最后一层使用GNN适配器。这确保了所有变换器的计算过程只执行一次,然后可以被缓存用于适配器训练。此外,我们对GNN适配器和LLMs预测的logits进行平均池化,然后优化它们下一个词预测的最终结果,这可以帮助适配器更多地关注与图相关的令牌。一旦训练了适配器,就可以将GraphAdapter与主干LLMs一起用于各种下游任务。例如,我们使用分类头放在最后一个令牌的嵌入上,以便微调节点分类。为了验证GraphAdapter的有效性,我们在包括社交和引用网络在内的多个真实世界TAGs上进行了广泛的实验。GraphAdapter在平均上比最先进的级联GNN-LM方法改进了4.7%,比自监督学习GNN-LMs改进了5.4%,同时训练参数和存储减少了30倍。此外,一旦预训练了GraphAdapter,就可以方便地微调用于各种任务。我们的消融分析显示,预训练步骤在不同图上一致地提高了模型性能。我们总结我们的贡献如下, * GraphAdapter是一种新颖的方法,它利用大型语言模型处理图结构数据,并进行参数高效的调优。 * 我们提出了一种残差学习程序,以LLMs预训练GNN适配器。预训练步骤显著提高了GraphAdapter的微调性能。 * 我们在使用最先进的开源大型语言模型(GPT-2 1.5B[28]和Llama 2 13B[33])的大规模TAGs上进行了广泛的实验。结果表明,GraphAdapter也可以从更大的模型中获益。
