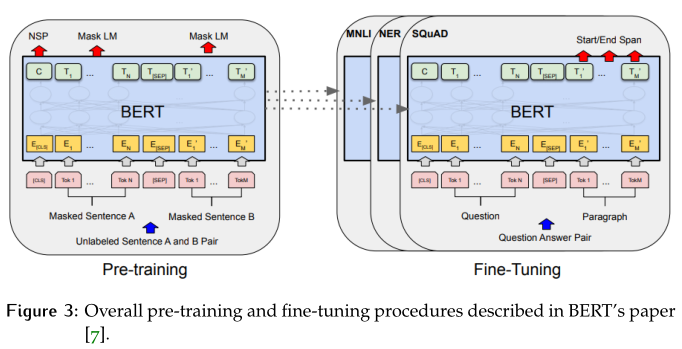
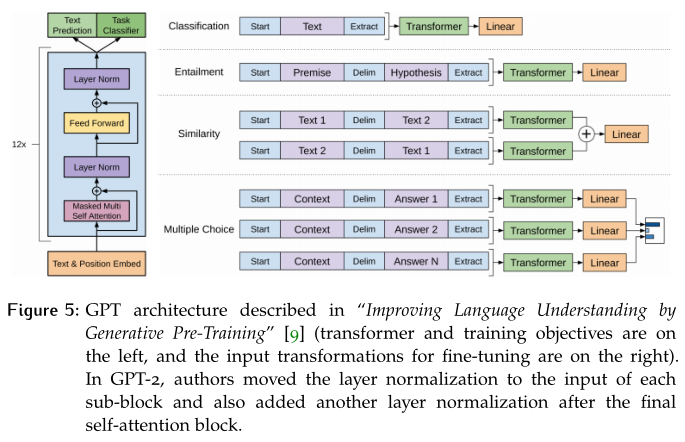
摘要 合成的文本生成具有挑战性,取得成功的不多。最近,一种名为Transformer的新架构允许机器学习模型更好地理解序列数据,比如翻译或摘要。BERT和GPT-2在其核心中都使用 Transformers,在诸如文本分类、翻译和NLI任务中表现出了良好的性能。在本文中,我们分析了这两种算法,并比较了它们在文本生成任务中的输出的质量。
介绍 自然语言处理(NLP)是一个很大的领域,我们可以在其中找到不同的任务:文本分类、命名实体识别、语言翻译……这些任务有一个共同的挑战:用人类语言编写的文本(通常是非结构化文本)。在本文中,我们关注的任务是使用条件语言模型和新的Transformer架构生成的文本。
为了理解文本生成,有必要定义什么是语言模型(LM)。在维基百科中,统计语言模型是一个单词序列的概率分布,例如,给定一个长度为m的序列,它分配一个概率P(w_1,…,w_m)到整个序列。因此,我们可以使用条件LM来查找序列中下一个单词出现的概率:P(w_m+1 |w_1,…,w_m)。
在本文中,我们假设你对深度学习、单词向量和嵌入空间有基本的了解。尽管如此,我们在这里描述一些与理解基于Transformer的模型相关的模型和技术。
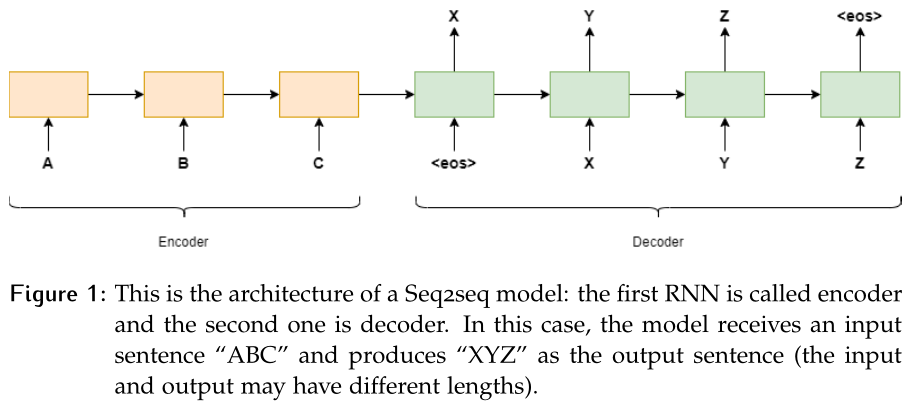
Seq2Seq 模型 在很长一段时间里,条件文本生成是基于Seq2Seq模型[1]的。Seq2Seq背后的思想是由两个递归神经网络(RRN)组成的,它们试图从前一个状态序列预测下一个状态序列(这两个神经网络分别接收编码器和解码器的名称)。扩展最广的两个RNNs是由Sepp Hochreiter和Jurgen Schmidhuber[2]于1997年引入的LSTM和Junyoung Chung等[3]于2014年引入的GRU。然而,用RNNs生成的文本远非完美:它们往往是废话,有时还包含拼写错误。基本上,一个错误的预测就有可能使整个句子变得毫无意义。此外,由于神经网络需要以序列的形式处理数据,因此不可能并行化处理。
上下文的词嵌入
传统上,模型接收一系列标记(通常是单词),并将它们转换为静态向量。简而言之,它们只是表示单词含义的数字向量。一个广泛扩展的模型是Word2vec(由Mikolov等人在2013年引入),它计算每个 token的静态向量(这些向量称为嵌入)[4]。此外,Word2vec的向量在句法和语义词的相似性方面提供了最先进的(SOTA)性能。
使用单词向量的强大之处在于它们可以使用数学运算符。例如,我们可以对向量进行加减运算:
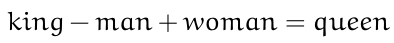
最近的技术包括将上下文合并到单词嵌入中:用上下文化的单词表示替换静态向量已经使几乎每个NLP任务的显著改进。ELMo在2018年[5]中引入了这种单词嵌入:向量是深双向语言模型(biLM)内部状态的学习函数。这是一个突破,它将引导模型进一步理解单词。例如,它们可能有不同的歧义词(例如rock可以是一块石头或一种音乐类型),而不是拥有相同的静态矢量。
Transformer
谷歌的研究人员在2017年的论文“Attention Is All You Need”[6]中发布了一种名为Transformer的新模型。简单地说,这个体系结构由自注意力层和逐点的全连接层组成(参见图2)。与我们描述的Seq2seq类似,Transformer包括编码器、解码器和最后的线性层。
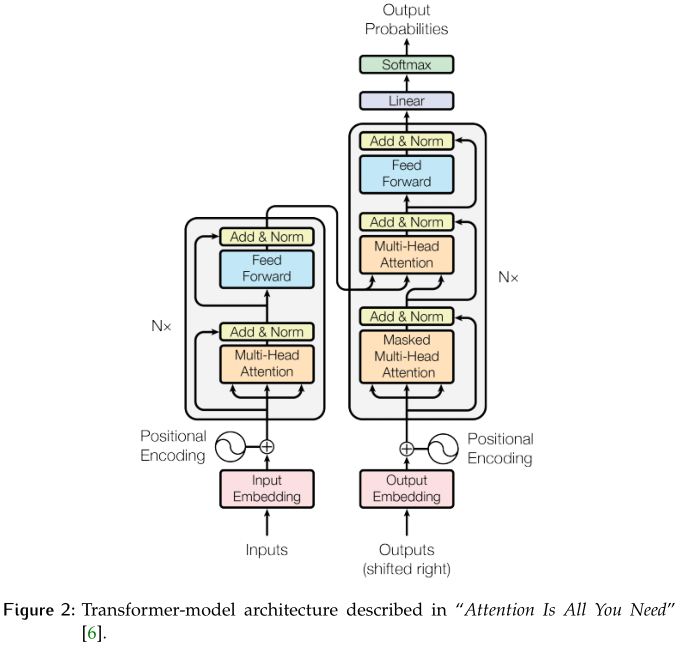
这些模型被设计用来处理序列数据(在NLP中特别有用)。注意,与Seq2seq相反,它们不包含递归或卷积,所以它们不需要按顺序处理序列。这个事实允许我们并行化(比RNNs多得多)并减少训练时间。