
主题: Sixth Workshop on NLP for Similar Languages, Varieties and Dialects
会议简介:
VarDial 2019将与NAACL 2019共同位于美国明尼阿波利斯。该研讨会将于2019年6月7日举行。VarDial是一个完善的系列研讨会,旨在为从事与从计算角度研究非特应性语言变异相关的一系列主题的学者提供一个论坛。该研讨会专题讨论与计算方法和语言资源密切相关的语言、语言变种和方言。
主讲嘉宾:
David Yarowsky目前是约翰斯·霍普金斯大学计算机科学系教授,基础研究包括跨语言信息投影、跨域知识转移、Co-training、主动学习和随机计算、来自多个知识来源的创造性引导,应用于机器翻译和自然语言处理。个人主页:https://www.cs.jhu.edu/~yarowsky/。
成为VIP会员查看完整内容

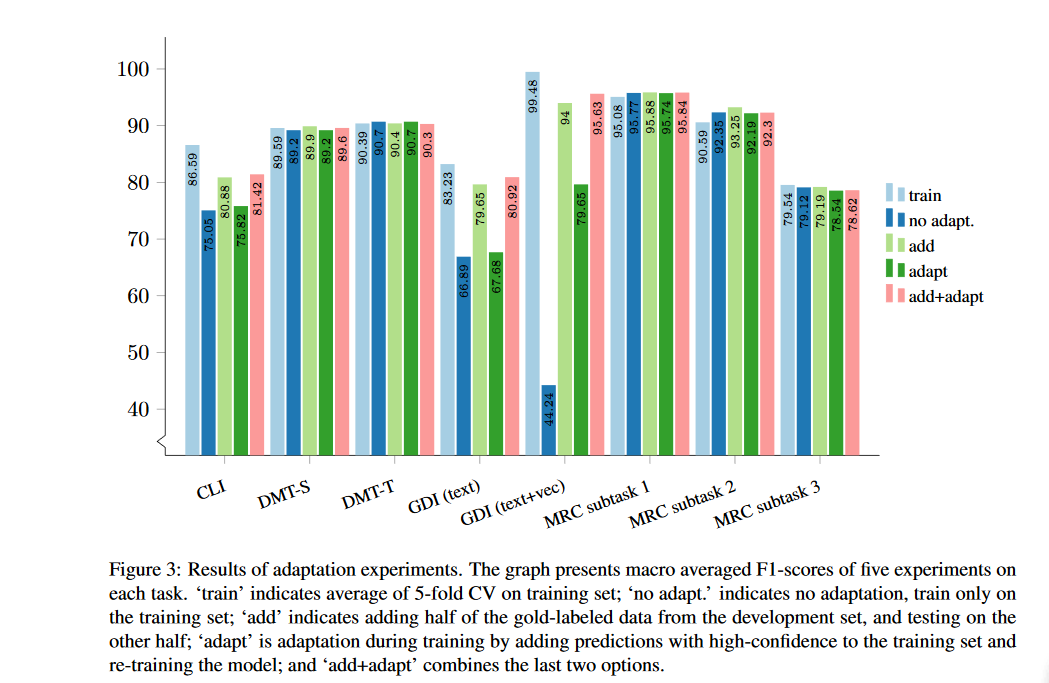

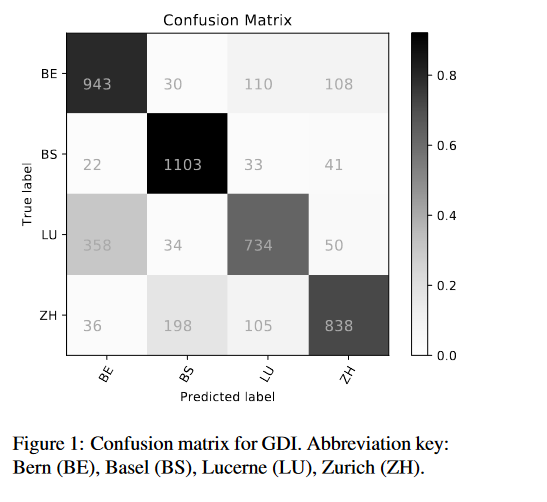

相关内容

语言变体是社会语言学研究的重要课题。R.A.赫德森(Richard Hudson)把语言变体定语为“社会分布相似的一套语项”。意指是由具备相同社会特征的人在相同的社会环境中所普遍使用的某种语言表现形式。“语言变体”是一个内涵很宽泛的概念,大至一种语言的各种方言,小至一种方言中某一项语音、词汇或句法特征,只要有一定的社会分布的范围,就是一种语言变体。 语言的变体受到复杂的社会因素制约,社会语言学对语言变体的研究一般认为,讲话人的社会阶级(Class)和讲话风格(Style)是语言变体的重要基础,而讲话人的性别对语言变体也产生重要影响。根据使用者来划分的变体叫方言,根据语言使用来划分的变体叫语体或语域。
专知会员服务
52+阅读 · 2020年2月8日
专知会员服务
48+阅读 · 2019年11月17日
Arxiv
3+阅读 · 2019年8月22日
Arxiv
5+阅读 · 2018年5月10日
Arxiv
6+阅读 · 2018年2月20日
相关主题




相关VIP内容
专知会员服务
52+阅读 · 2020年2月8日
专知会员服务
48+阅读 · 2019年11月17日
相关资讯
相关论文
Arxiv
3+阅读 · 2019年8月22日
Arxiv
5+阅读 · 2018年5月10日
Arxiv
6+阅读 · 2018年2月20日