

近来,大语言模型(LLM)内在推理能力的进展催生了基于 LLM 的智能体系统,这类系统在多种自动化任务上展现出接近人类的性能。然而,尽管它们都依赖 LLM,不同的智能体推理框架会以不同方式引导并组织推理过程。为此,本文提出一种系统化的分类体系,对智能体推理框架进行拆解,并通过跨场景对比其应用来分析这些框架如何在框架层面主导推理。具体而言,我们提出一种统一的形式化语言,将智能体推理系统进一步划分为单智能体方法、基于工具的方法和多智能体方法。随后,我们全面综述它们在科学发现、医疗健康、软件工程、社会仿真与经济学等关键应用场景中的实践。我们还分析各类框架的特征,并总结不同的评估策略。我们的综述旨在为研究社区提供一幅全景式图景,帮助理解不同智能体推理框架的优势、适用场景与评测实践。
1 引言
大语言模型(LLM)凭借其强大的泛化能力与可观的推理能力,正在迅速重塑从日常生活(如创意构思、邮件撰写或学习新概念)到特定领域研究的诸多方面 [198]。研究者日益将 LLM 作为核心组件来赋能科研与创新 [166],涵盖从面向领域知识的问答 [310]、代码生成 [118],到辅助科研工作 [164] 等多种任务。通过这些路径,LLM 正在迅速成为现代生活与研究的重要组成部分。
然而,尽管 LLM 在多个领域具有巨大潜力,它们也存在内在局限,可能限制其实用性。例如,LLM 往往面临幻觉、知识过时、训练与推理成本高昂等问题 [111]。这些问题常常导致 LLM 的可靠性与一致性受损,从而限制其在医疗健康与软件工程等对结果可靠性要求极高的关键领域中的应用。
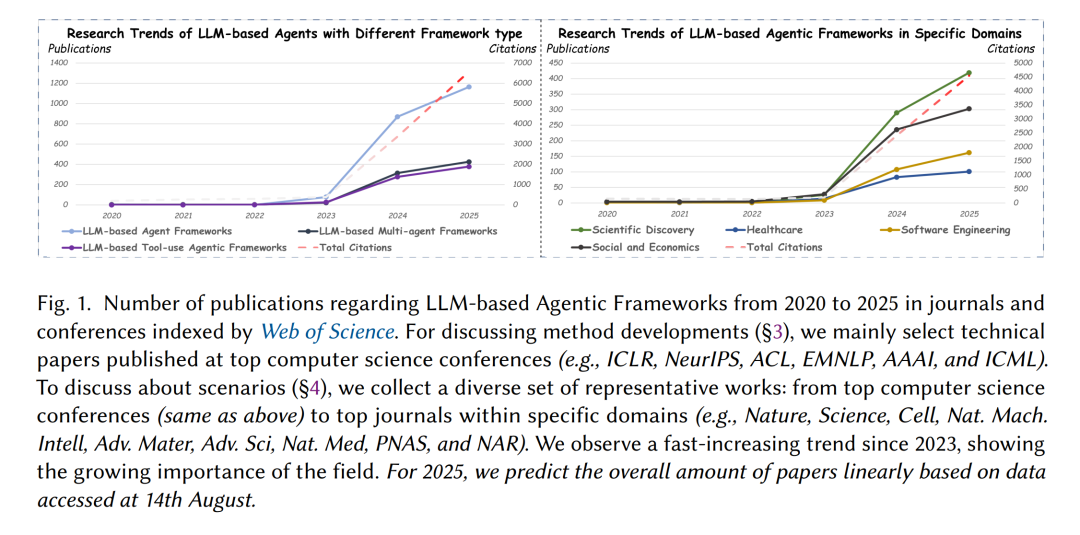
为克服上述障碍,学术界正在积极探索以 LLM 为核心引擎、能够执行复杂多步推理任务的基于 LLM 的智能体推理框架 [217, 266]。如图 1 所示,我们观察到顶级会议论文数量显著上升。最初,“智能体”(Agent)在文献 [227] 中被定义为“通过传感器感知环境并通过执行器对环境采取行动”的系统,能够对环境进行动态适应并采取相应行动 [166]。这一新兴范式有机整合了规划、记忆与工具使用等关键模块,将 LLM 重塑为一个能够感知环境、动态适应并持续行动的任务执行器 [112, 154, 266]。通过纵向延展、横向扩展或逻辑回溯,该范式在可靠性与任务复杂度上,从根本上超越了传统 LLM 的单步推理能力。 这一趋势也在工业界得到广泛回应,科技巨头正积极将智能体工作流融入其核心业务。例如,微软的 AutoGen¹ 被设计用于帮助企业构建定制化的多智能体应用。此外,从深度集成智能体能力的“vibe coding” 编辑器 Cursor² 到自主式 AI 软件工程师 Devin³,基于智能体推理框架的清晰演进正获得广泛认可,并逐步替代传统的开发方式。
然而,与此同时,该领域的爆发式增长也模糊了基于 LLM 的智能体的边界 [305]。例如,与传统多智能体系统 [30, 87, 315] 与自治系统 [255] 等领域概念的交叉,使得研究范围难以界定。与此同时,往往也难以清晰区分:智能体能力的增强究竟源自精心的框架设计、模型层面的改进,还是其他技术进步。这种双重模糊性给不同项目的横向比较带来严峻挑战,并有忽视框架设计在智能体系统推理能力中基础性作用的风险。 因此,我们认为,此时进行一项系统综述,以总结智能体推理框架的最新进展与应用场景,恰逢其时。我们首先明确界定这些框架的边界,并据此提出统一的方法学分类体系。随后,我们进一步分析这些方法在多样化场景中的应用与评测策略,旨在为智能体的发展提供规范化与安全化的清晰路线图。我们的分类法也契合当前诸如“上下文工程”等热门议题。 总体而言,本文的贡献如下: * 据我们所知,这是首个提出统一方法学分类,用以系统性凸显智能体框架中核心推理机制与方法的综述; * 我们采用一种形式化语言来描述推理过程,清晰展示不同方法对关键步骤的影响; * 我们广泛考察了智能体推理框架在若干关键场景中的应用。在这些应用场景中,我们依据所提分类法对代表性工作进行深入分析,并给出相应的数据集与评测设置集合。
本文结构如下:第 §2 章将进一步介绍并比较相关综述与本文的差异。第 §3 章将给出技术分类法,系统分析现有的智能体推理技术。第 §4 章将进一步给出智能体推理框架的应用场景,并介绍各场景中智能体的常见设计。最后,第 §5 章讨论未来方向,第 §6 章给出全文结论。
