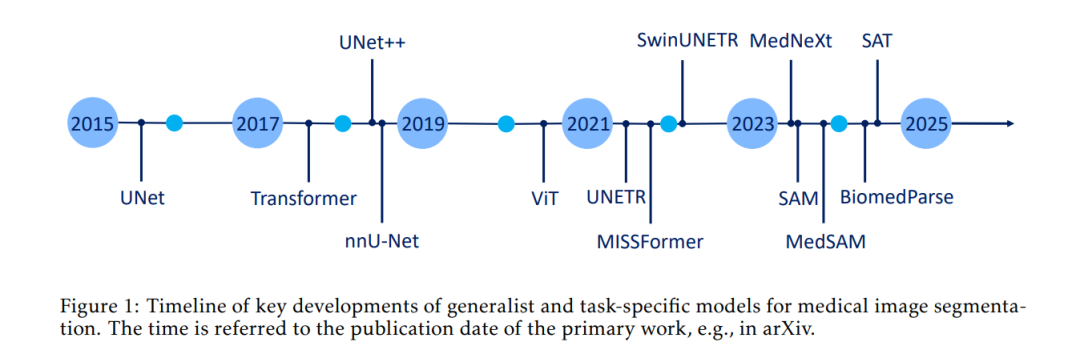
1 引言
在过去十年中,生物医学图像分割经历了显著的发展,从最初的简单卷积神经网络(CNN)方法逐步演进为复杂的深度学习架构。该领域的首个重大突破来自 Ronneberger 等人于 2015 年提出的 U-Net 模型,其独特的编码器-解码器结构与跳跃连接机制彻底改变了医学图像分割的格局。U-Net 为语义分割,特别是生物医学图像中的语义分割,提供了一个稳健的框架,使得解剖结构的精确勾画成为可能,并被广泛应用于各种计算机视觉任务中。 随后,基于 Transformer 的架构在图像分析与分割中带来了又一关键转折点。最初用于自然语言处理的 Transformer 迅速被引入计算机视觉领域,挑战了传统的 CNN 范式。谷歌的《Attention is All You Need》(Vaswani 等,2017)与《An Image is Worth 16x16 Words》(Dosovitskiy 等,2020)奠定了架构创新的基础,推动医学影像的转型发展。不久后,Liu 等人提出的 Swin Transformer(2021a,2022b)引入了分层视觉 Transformer(ViT)架构,在提升计算效率的同时改善了图像处理能力。 与 Transformer 的发展并行,CNN 架构也持续演进。Meta 的 Woo 等人提出的 ConvNeXt(2023)重新构想了 CNN,融合了诸如倒置瓶颈结构、深度可分离卷积和宽卷积核等 Transformer 风格的设计原则。其继任者 ConvNeXt V2 在此基础上进一步改进,引入了如掩码图像重建等先进的无监督预训练策略,初步迈向(但尚未进入)“基础模型”(Foundation Models)领域。 随着架构与预训练框架在更大规模数据集上的发展,这一进程最终促成了基础模型的诞生。基础模型被定义为在大规模数据上进行自监督学习训练的模型,可通过微调等方式适应多种下游任务(Bommasani 等,2021)。也有学者将这类具备高迁移性与多任务处理能力的模型称为“通用模型”(universal models)(Chen 等,2024c)。由于二者均指向“通用人工智能”(generalist AI)的理念,因此我们在此统一使用“通用模型”(generalist models)一词指代它们。 计算机视觉领域的通用模型崛起,源于大语言模型(LLMs)带来的成功范式转移,如 BERT(编码器型 Transformer)与 GPT(解码器型 Transformer)。这些模型证明了在大规模数据集上进行自监督预训练能够学得具有强泛化能力的表示,并揭示了模型规模与计算资源扩展对于特征学习的重要性(Devlin 等,2019;Radford 等,2018)。 这一范式首先通过两大自监督预训练方法在视觉领域实现:OpenAI 的 CLIP(Contrastive Language–Image Pre-training,Radford 等,2021)利用图文对训练获得强大的视觉表示能力;Meta 的 DINO(Distillation with No Labels,Caron 等,2021)则提出无监督方式对 ViT 进行预训练。随后,领域逐渐向更具泛化能力的架构发展,如 SEEM(Segment Everything Everywhere All at Once,Zou 等,2023a,b)、SAM(Segment Anything Model,Kirillov 等,2023a)以及其迭代版本 SAM 2(Ravi 等,2024a)。 随着语言领域的通用模型向视觉迁移,医学影像领域也开始从监督式、任务特定模型(通常仅限于小范围数据集、特定解剖结构、单一任务或单一成像模态)转向“预训练+适配”范式(Moor 等,2023)。其中一些典型例子包括 SAM 的医学适配版本,如 MedSAM(Ma 等,2024a)和 Medical SAM 2(Zhu 等,2024),以及原生的通用医学模型,如微软提出的 BiomedParse(Zhao 等,2024b)。该领域的关键进展可参见图 1 所示的时间线。 与当前常将 Transformer 与 CNN 的对立作为主流讨论的视角不同,我们的研究认为,现代医学图像分割的核心分歧并不在于架构类型,而在于“通用模型”与“任务特定模型”之间的根本差异。前者在百万级多模态医学图像上进行预训练,展现出卓越的适应性和一致性,能够跨越不同解剖区域,而后者通常局限于特定任务和单一模态。 医学图像中的通用模型不仅是技术上的突破,更是 AI 方法论上的一次哲学转变。通过大规模预训练和多模态学习,这些模型打破了对任务过度专门化的传统思维,展现出在复杂医学任务中实现泛化学习的潜力,从而减少了对大量任务特定标注数据的依赖。