

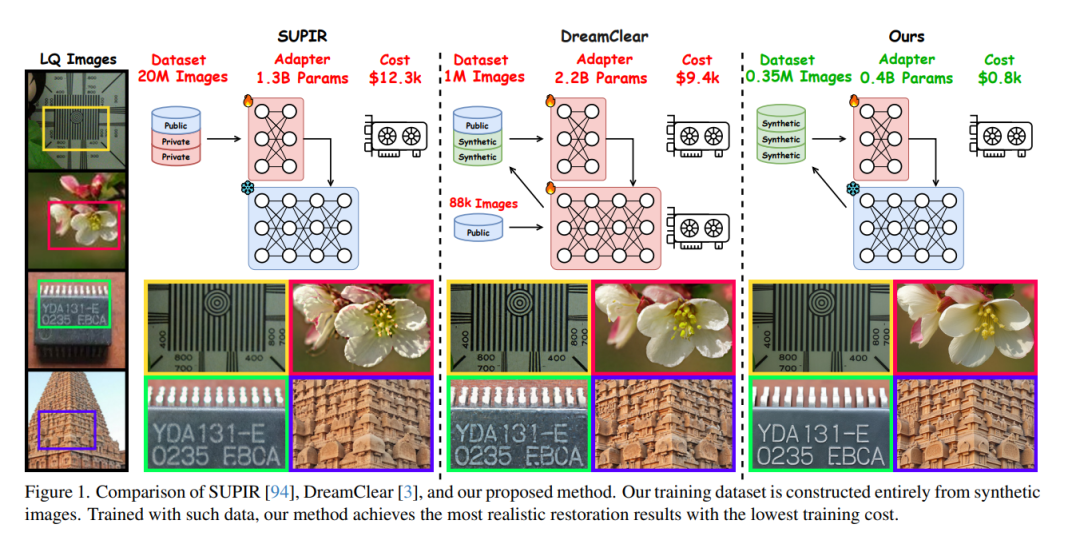
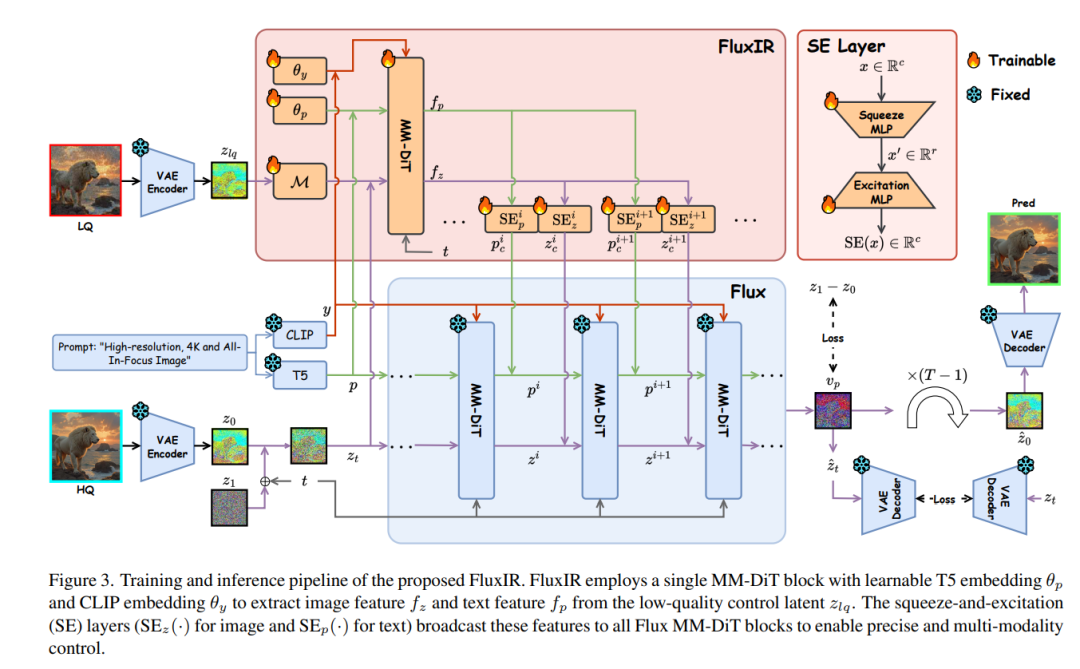
近年来,预训练的文本‑图像(T2I)模型凭借强大的生成先验,被广泛应用于真实场景的图像复原。然而,要让这些大型模型在图像复原任务中可控,通常需要大量高质量图像和巨额计算资源进行训练,既昂贵又不利于隐私保护。本文发现,经过充分训练的大型 T2I 模型(即 Flux)能够生成与真实分布一致的多样化高质量图像,可为训练提供近乎无限的样本,缓解上述难题。为此,我们提出了一条名为 FluxGen 的图像复原训练数据构建流程,包括无条件图像生成、图像筛选和退化图像模拟。我们还精心设计了一种轻量级适配器 FluxIR,其采用 squeeze‑and‑excitation (SE) 层来控制基于 Diffusion Transformer (DiT) 的大型 T2I 模型,从而恢复合理细节。实验证明,该方法能有效地使 Flux 模型适配真实场景图像复原任务,并在合成与真实退化数据集上取得了更优的定量指标和视觉质量——训练成本仅为现有方法的约 8.5%。
成为VIP会员查看完整内容
相关内容
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
142+阅读 · 2023年3月29日
Arxiv
83+阅读 · 2023年3月21日

相关VIP内容
相关资讯
相关论文
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
142+阅读 · 2023年3月29日
Arxiv
83+阅读 · 2023年3月21日