自监督学习(SSL)从大量未标记的训练数据中学习高质量的表示。随着数据集的不断扩大,确定哪些样本对学习这些表示最有贡献变得至关重要。这使得SSL能够通过减少学习高质量表示所需的数据量来提高效率。然而,如何量化样本对SSL的价值一直是一个未解决的问题。在这项工作中,我们首次对此进行了讨论,我们证明了对比自监督学习最有贡献的样本在期望值上是那些与其他样本的增强最相似的样本。我们为这些子集的SSL的泛化性能提供了严格的保证。从经验上看,我们发现,也许令人惊讶的是,对SSL贡献最大的那些子集是对监督学习贡献最少的那些子集。通过大量实验,我们证明了我们的子集在CIFAR100、CIFAR10和STL10上的性能超过随机子集超过3%。有趣的是,我们还发现我们可以安全地从CIFAR100中排除20%的样本,从STL10中排除40%,而不影响下游任务的性能。
https://sjoshi804.github.io/data-efficient-contrastive-learning/
1. 引言
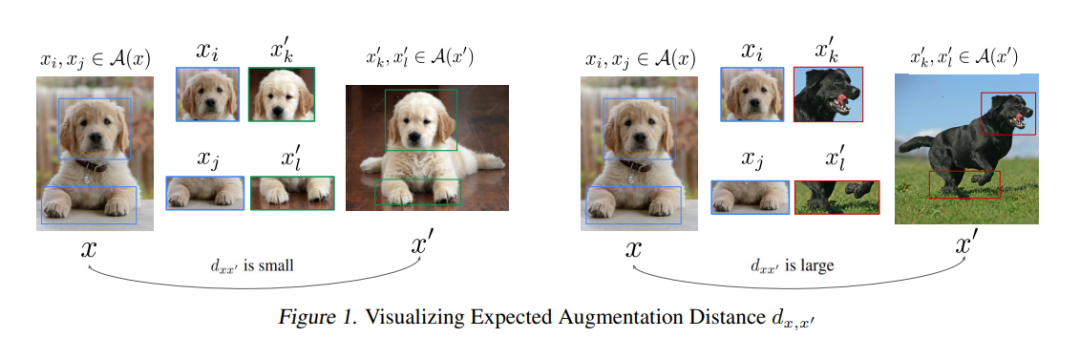
大数据集驱动现代的机器学习模型。然而,一个关键问题是:什么样的数据点对学习是必要的,是否更多的数据总能带来更好的性能?回答这个问题至关重要,因为它可以减少在大数据集上训练的大量成本,提高训练模型的性能,并指导数据收集。这激发了一系列最近的研究,寻找监督学习最基本的子集(Toneva等,2019;Paul等,2021;Mirzasoleiman等,2020;Mindermann等,2022;Sorscher等,2022;Swayamdipta等,2020)。然而,随着数据集的不断扩大,获取高质量的标签变得过于昂贵。因此,人们对大规模无标签数据集的自监督(SSL)预训练产生了浓厚的兴趣(Chen等,2020;Grill等,2020;Chen和He,2021;Zbontar等,2021)。然而,找到对SSL最重要的数据点仍然是一个未解决的问题。找出对SSL贡献最大的样例确实非常具有挑战性。当标签可用时,可以根据每个样例的损失(或预测的置信度)或梯度范数来量化学习的价值。实际上,难以学习的样例,即在训练过程中损失大或梯度范数大的例子,是对最小化训练损失贡献最大的样例。然而,在没有标签的情况下,SSL方法基于样例与其他数据点的相似性来聚类样例。因此,每个样例的SSL损失和梯度与数据集中的其他样例紧密相连。因此,删除一个样例会影响所有其他样例的损失和梯度。这使得数据选择对SSL来说比监督学习更具挑战性。在这项工作中,我们首次解决了上述挑战,找到了可以证明对SSL贡献最大的样例。特别的,我们关注的是对比自监督学习,它通过最大化同一样例的增强视图之间的对齐度,并最小化不同样例的增强视图之间的相似度来学习表示(Chen等,2020;Zbontar等,2021;Oord等,2018)。我们证明,对SSL贡献最大的样例是那些其增强视图与其潜在类别中其他样例的增强视图之间的预期相似度最高的样例。实际上,这样的样例将一个类中的不同组样例拉到一起,并使对比损失能最大程度地把不同类别中的样例的表示推开。我们证明这样的样例(1)确保了每个类别中样例的增强视图之间的高度对齐度,(2)保留了SSL在完整数据上学习的类别表示的中心。我们利用上述属性为在子集上学习的SSL表示上训练的线性分类器的性能提供泛化保证。
我们注意到,可能令人惊讶的是,对对比自监督学习(SSL)贡献最大的样例对监督学习的贡献最小。特别地,我们使用预测的置信度以及遗忘分数(Toneva等,2019)即一个样例在训练过程中被正确分类后被误分类的次数,来量化监督学习的样例的难度。我们发现对SSL贡献最大的样例是对监督学习来说容易的样例,这些样例具有高置信度和低遗忘分数。这样的样例可以安全地从监督学习流程中排除(Toneva等,2019),而不会影响准确度。相反,对监督学习贡献最大的难以学习的样例会严重影响SSL的性能。我们广泛评估了我们提出的方法在CIFAR10,CIFAR100(Krizhevsky等,2009)和STL(Coates等,2011a)中学习样例表示的性能,使用的是ResNet50。我们证明了我们的子集在CIFAR100和STL上的性能超过随机子集超过3%。有趣的是,我们发现在CIFAR100的样例中,最多20%的样例,以及在STL中,最多40%的样例可以安全地排除,而不会影响下游性能。我们证明了对SSL贡献最大的子集可以在训练早期或通过一个小的代理模型有效地提取出来。我们也证实了我们的方法适用于其他的对比学习方法,例如BYOL(Grill等,2020),并进一步观察到,对于BYOL,丢弃STL10中20%的样例甚至可以提高下游性能2%。
2. 问题与方法
对比式自监督学习通过学习一个编码器f,最大化同一样例不同增强视图(即正对)的表示之间的一致性,并最小化不同样例的增强视图(即负对)的表示之间的一致性,从而学习训练数据中样例的表示。我们的目标是找到一个最多包含r个训练样例的子集S ⊆ V,使得通过在子集上最小化对比损失得到的编码器
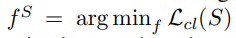
,使得神经网络分类器在完整数据上获得相似的错误。形式上,我们旨在解决以下问题:
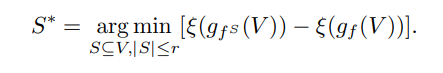
我们首先研究子集S ∗必须满足哪些属性,以使得在子集上学习到的表示能够提供较小的下游分类错误。为此,我们依赖最近对对比学习优化和泛化的理论结果。特别是,Huang等人(2021)最近的结果显示,通过对比学习获得的表示的泛化性能依赖于:(1)正对的对齐,(2)类中心的离散度,以及(3)增强数据的集中度。对齐反映了样例的增强视图的表示之间的相似性,期望中的这种相似性。良好的对齐需要一个样例的所有增强视图具有相似的表示。类中心的离散度反映了类中心µl和µk有多远。良好的离散度会导致所有类中心对之间的距离足够大。

3. 实验结果
在本节中,我们首先评估对比学习训练的模型在由CL-Core和随机子集找到的常见图像分类基准数据集(即CIFAR10、CIFAR100和STL10)上的下游泛化性能。然后,我们对近似潜在类别和用于估计预期数据增强距离的代理模型的效果进行了广泛的消融研究。最后,我们研究了在子集中用于监督学习的样本的难度。
3.1. 下游泛化性能
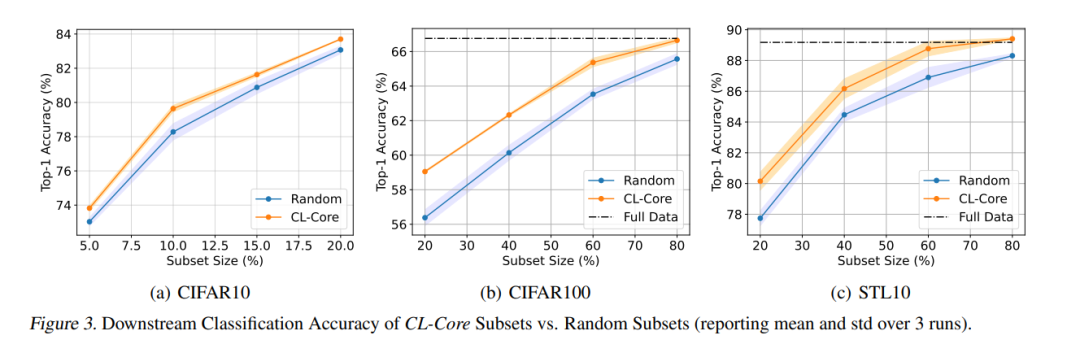
SimCLR 图3显示,使用CL-Core找到的不同大小的子集在CIFAR100和STL10上比随机子集的训练性能提高了超过3%,在CIFAR10上提高了最多2%。BYOL 图4(a)显示,使用CL-Core从STL10找到的不同大小的子集进行训练,在性能上超过随机子集超过3%。有趣的是,80%大小的子集在全数据上的性能超过了BYOL 2%。这证实了CL-Core可以有效地找到对对比学习做出最大贡献的样例,并排除可能有害的样例。
3.2 探究由CL-Core找到的子集
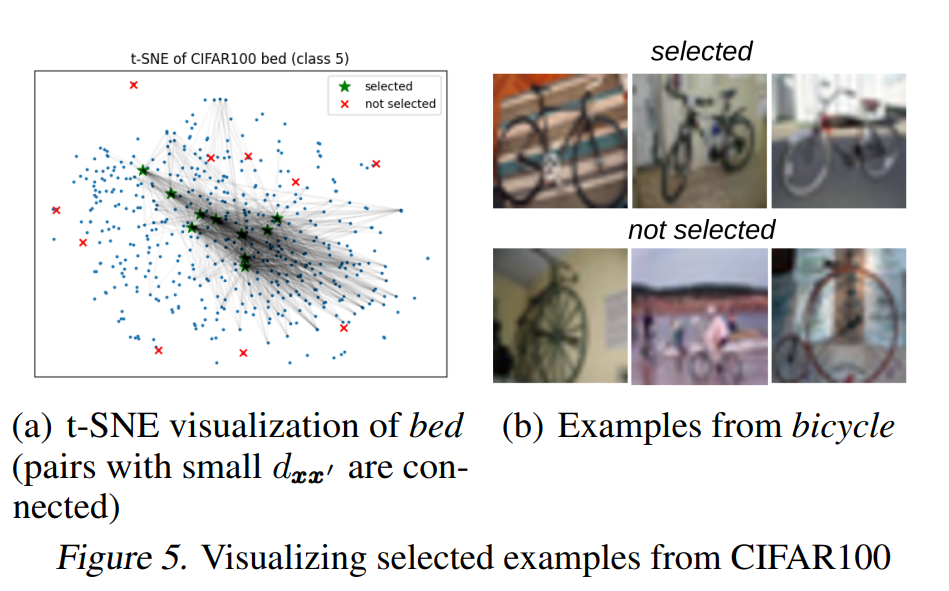
图5(a)使用t-SNE可视化了在CIFAR100中从“bed”类别中由CL-Core选择和未选择的样例。与选择和未选择样例之间的预期数据增强距离较小的样例之间有连接线。我们可以看到,被选择的样例与该类别中的许多其他样例之间的预期数据增强距离很小。图5(b)展示了从“bicycle”类别中选择和未选择的一些样例。我们可以看到,被选择的样例代表了整个类别,而未被选择的用哪个例则呈现了不常见的姿势或视角。易样本是最重要的接下来,我们使用遗忘分数(Toneva等人,2019),即在监督学习期间被正确分类后被错误分类的次数,来量化一个样例的难度。图4(e)显示了那些在监督学习中可以安全丢弃的最不易遗忘的样例(Toneva等人,2019)能够显著优于随机基线,并且在较小的子集上实现可比较的性能。附录A的图6显示了由CL-Core找到的子集具有较低的遗忘分数和较高的置信度,平均而言,它们对于监督学习来说是易样本。实际上,对于SSL来说最重要的子集对于监督学习来说却是最不重要的。困难样例损害对比学习最后,图4(f)确认了由CL-Core排名最低的样例,即由具有与其潜在类别的其他样例之间较大预期数据增强距离的样例组成的子集,会严重阻碍对比学习。这些样例很难学习,并且对于监督学习非常有益(Toneva等人,2019)。