

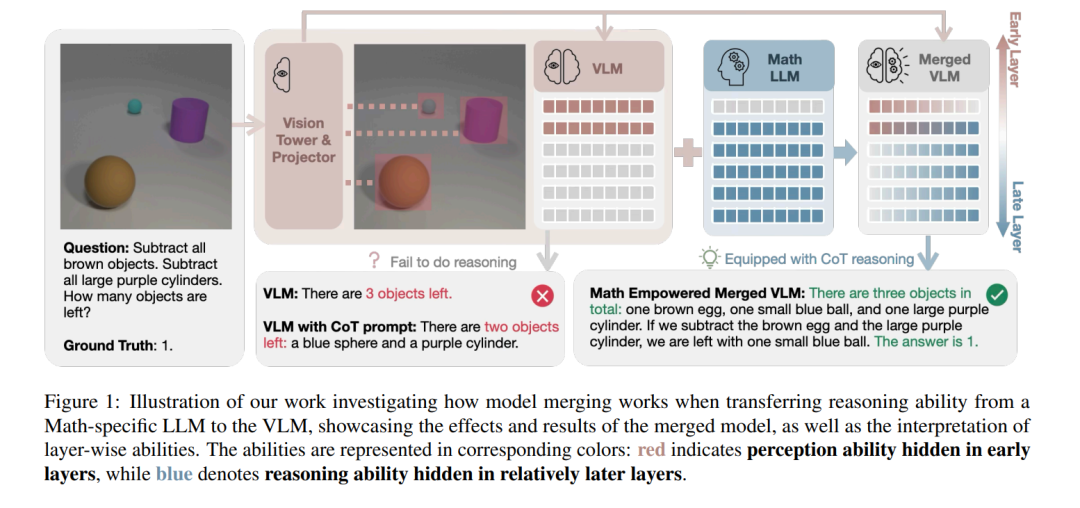
视觉语言模型(VLMs)将视觉感知能力与大型语言模型(LLMs)所具备的通用能力(如推理)结合在一起。然而,这两种能力如何协同发挥作用,其内部机制尚未被深入理解。在本研究中,我们尝试通过模型融合的方式,将感知与推理进行组合,具体方法是连接不同模型的参数。 与以往主要集中于同类模型融合的研究不同,我们提出了一种跨模态的模型融合方法,使得LLM的推理能力能够无缝引入到VLM中。通过大量实证实验,我们证明模型融合提供了一种无需重新训练即可将推理能力从LLM迁移至VLM的有效路径。 此外,我们还利用融合后的模型来研究感知与推理的内部机制以及模型融合对其影响的方式。我们的研究发现:感知能力主要编码于模型的前层结构,而推理能力则更多依赖于中后层结构。在融合之后,模型的所有层都开始对推理任务产生贡献,而感知能力的层级分布则基本保持不变。 这些发现表明,模型融合不仅是多模态集成的有效手段,同时也为理解感知与推理的协同机制提供了新的视角。我们的代码已公开,地址如下: 👉 https://github.com/shiqichen17/VLM-Merging
成为VIP会员查看完整内容
相关内容
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
39+阅读 · 2023年4月19日
Arxiv
209+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
142+阅读 · 2023年3月29日