论文题目:Croppable Knowledge Graph Embedding
本文作者:朱渝珊(浙江大学)、张文(浙江大学)、刘治强(浙江大学)、陈名杨(浙江大学)、梁磊(蚂蚁集团)、陈华钧(浙江大学)
发表会议:ACL 2025
论文链接:https://arxiv.org/abs/2407.02779
代码链接:https://github.com/YushanZhu/croppable-kge
欢迎转载,转载请注明出处****

一、引言
知识图谱嵌入(KGE)的维度与性能存在显著关联:高维KGE虽然表达能力更强,但需要更多存储和计算资源。实际应用中,不同设备对KGE维度的需求各异,如下图所示,服务器等高性能设备可部署高维KGE,而智能手机、车载系统等资源受限设备则需低维KGE。传统方法需要为每个目标维度单独训练模型,当需求变更时不得不重新训练,尤其在低维场景下,为了确保KGE的良好性能,还需借助知识蒸馏等模型压缩技术。这显著增加了训练成本,并限制了 KGE 在不同场景中服务的效率和灵活性。 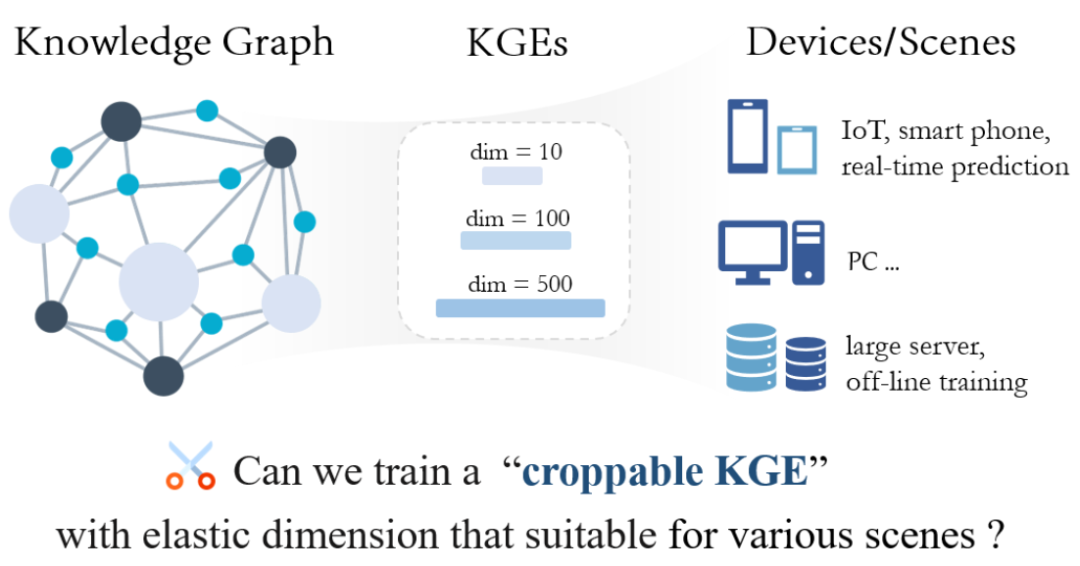
我们提出的可裁剪KGE框架MED包含个不同维度的子模型(),每个子模型对应维度是,其嵌入由完整嵌入的前维构成。对于给定三元组,知识图谱嵌入模型的评分函数记为,则子模型对三元组的评分为,其中表示向量的前维。子模型的参数会被更高维度的()共享。子模型数量及各子模型维度可根据实际需求设置。 在模型设计上,我们追求两个目标:(1)低维子模型需最大化性能,(2)高维子模型不仅要保持低维子模型的能力,还需学习低维模型无法掌握的知识(即正确预测那些被低维子模型预测错误的三元组)。MED基于知识蒸馏技术,通过以下机制实现:
- 互学习机制(Mutual Learning Mechanism):高低维子模型相互学习,使低维模型性能提升,同时高维模型保留低维模型的基础能力;
- 进化提升机制(Evolutionary Improvement Mechanism):帮助高维模型掌握低维模型难以学习的知识;
- 动态损失加权(Dynamic Loss Weight):自适应平衡各子模型的多重优化目标。
三、实验
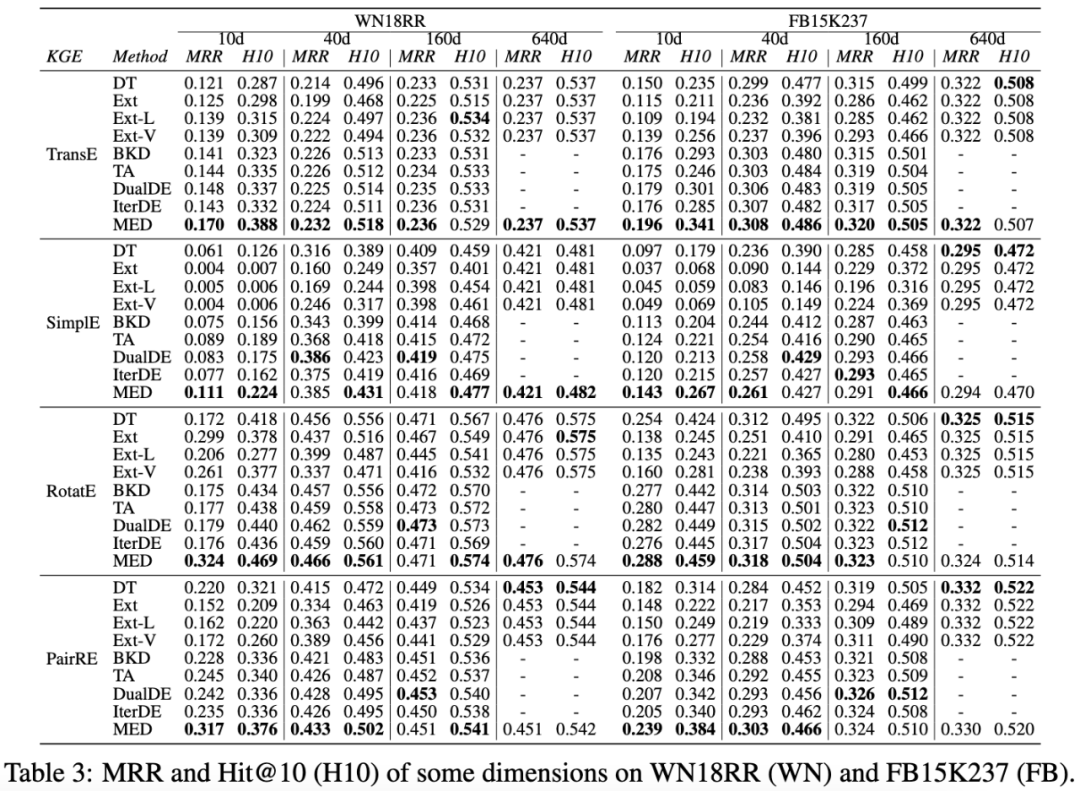
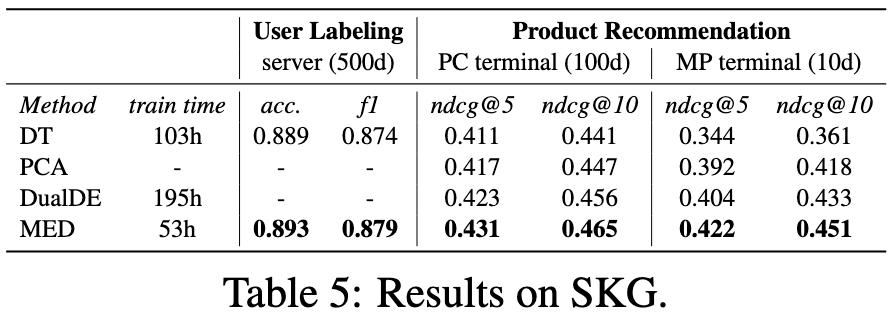
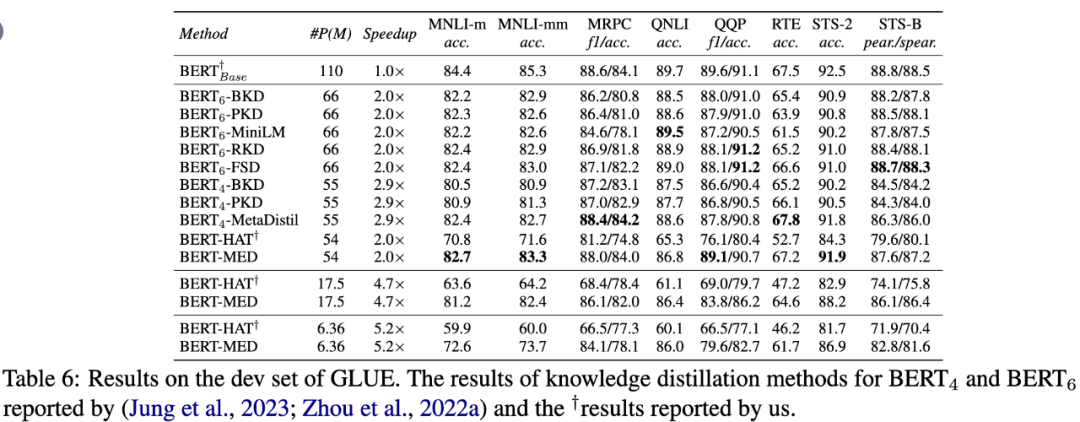
本文在4个标准知识图谱补全数据集(WN18RR, FB15K237, CoDEx-L, YAGO3-10)上测试了4种KGE模型,并基于大规模社交知识图谱(SKG)验证了3种实际应用场景,还将该方法拓展应用到BERT语言模型。实验结果表明,MED方法不仅具有显著效果和高效性,还展现出灵活的可扩展能力。