

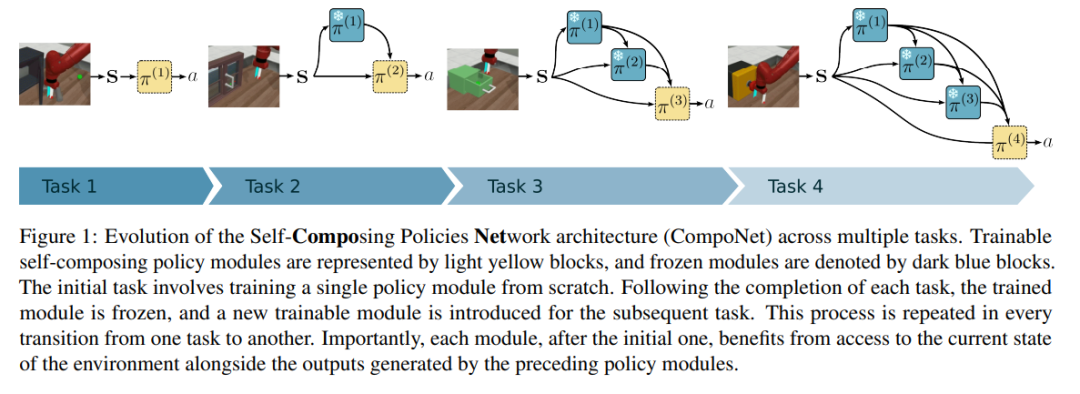
本研究提出了一种可增长且模块化的神经网络架构,能够在持续强化学习中自然地避免灾难性遗忘和任务干扰。每个模块的结构设计支持对先前策略与当前内部策略的选择性组合,从而加速当前任务的学习过程。与以往的可扩展神经网络方法不同,我们证明所提出的方法在任务数量增长时,其参数数量仅线性增长,同时在可扩展性的同时不牺牲模型的可塑性。在连续控制与视觉类基准任务上的实验表明,该方法在知识迁移能力和整体性能方面均优于现有方法。
成为VIP会员查看完整内容
相关内容
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日

相关VIP内容
相关资讯
相关论文
Arxiv
40+阅读 · 2023年4月19日
Arxiv
213+阅读 · 2023年4月7日
Arxiv
79+阅读 · 2023年4月4日
Arxiv
145+阅读 · 2023年3月29日