【导读】图学习与强化学习如何结合是个重要的问题,来自东北大学的学者最近发布了《图强化学习》综述,总结了GRL方法的方法描述、开源代码和基准数据集,非常值得关注!

图挖掘任务产生于许多不同的应用领域,包括社交网络、交通运输、电子商务等,近年来受到了理论和算法设计界的极大关注。在图数据挖掘任务中,使用正在研究中的强化学习(RL)技术进行了一些开创性的工作。然而,这些图挖掘算法和RL模型分散在不同的研究领域,难以对不同的算法进行比较。在本综述中,我们提供了RL模型和图挖掘的全面概述,并将这些算法推广到图强化学习(GRL)作为一个统一形式化。我们进一步讨论了GRL方法在各个领域的应用,并总结了GRL方法的方法描述、开源代码和基准数据集。最后,提出了未来可能需要解决的重要方向和挑战。这是对GRL文献进行全面考察的最新成果,为学者提供了一个全球视野,也为该领域以外的学者提供了学习资源。此外,我们为想要进入这个快速发展的领域的感兴趣的学者和想要比较GRL方法的专家创建了一个在线开源软件。
https://www.zhuanzhi.ai/paper/19dae52fbe743dda12652a7f8348f790
引言
RL的成功解决了机器人技术[1]、游戏[2]、自然语言处理(NLP)[3]等领域的挑战。RL解决了agent应该如何通过与环境[4]的交互来学习采取行动以最大化累积奖励的问题。RL在跨学科领域的快速发展促使学者们探索新的RL模型,以解决现实世界中的应用,如金融和经济[5,6]、生物医学[7,8]和交通[9-11]。另一方面,许多现实世界的数据可以用图来表示,图结构的数据挖掘得到了广泛的研究,如链接预测[12,13],节点分类[14],图分类[15]。为了实现图挖掘,学者们提出了多种策略,包括新的信息聚合函数[16]、图结构池化[17]和邻域采样方法[12]。近年来,随着图尺度的增加和RL方法的不断发展,学者们开始关注将图挖掘任务与RL方法相结合,利用强大的RL方法解决图挖掘任务中出现的决策问题引起了越来越多的兴趣[14,15,18 -20]。
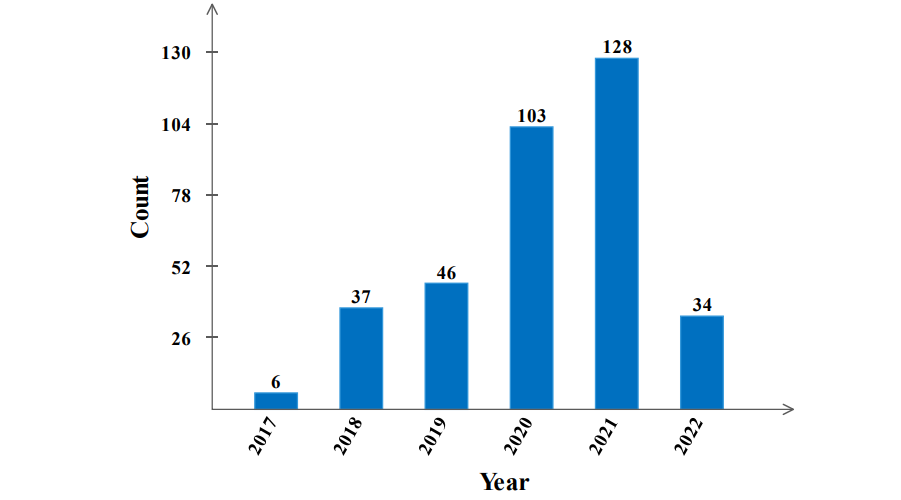
图强化学习发展
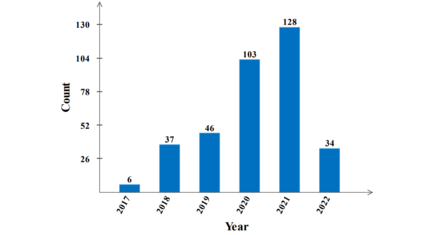
图挖掘算法与RL模型的合作研究逐渐增多,我们在图1中展示了2017年1月至2022年3月在GRL上发表的论文的趋势。我们将继续更新我们发布的开源知识库中的更多研究文章。图挖掘任务的传统方法和基于深度学习的模型在模型设计和训练方法方面与基于RL的方法有很大的不同,学者们在使用RL方法分析图数据时面临着许多挑战。虽然通常用于计算机视觉和NLP的机器学习模型可以有效地捕获欧氏数据(如图像和语音)的隐藏模式,但由于图数据的复杂性,这些模型不能直接用于图数据。其次,由于图数据的复杂性,使得RL方法难以准确建立环境或状态空间,以及为具体任务[21]设计动作空间或奖励函数。具体地说,图形是大量的、高维的、离散的对象,并且在建模上下文中具有挑战性。第三,图挖掘捕获任务的目标各不相同,这就需要RL方法为特定的目标设计有效的架构,并适应图的结构。第四,大规模图数据的出现给RL方法的使用带来了限制。历史数据驱动的RL方法需要不断从环境中学习来更新参数,数据规模的增大导致了RL方法的低效。最后,现实世界中的许多跨学科数据都可以建模为网络结构,而整合领域知识的跨学科数据分析将导致模型的扩展性和复杂性,这也给RL方法的设计带来了很大的困难。我们认为,解决图挖掘任务的可扩展和高效的RL方法是关键的研究问题。
为了应对上述挑战,学者们在RL和图挖掘领域进行了广泛的工作,在很多领域都有尝试[22,23],从解决诸如谣言检测[24]到使用GRL技术解决交互式推荐系统[25]等任务。经过全面的调研,我们发现现有的将RL技术与图数据挖掘相结合进行协同学习的方法主要分为两大类:** (1) 利用图结构解决RL问题[26-32],(2) 利用RL方法解决图挖掘任务[15,22,33 -35]。我们将GRL定义为基于图中的节点、链接、子图等关键组件,利用RL方法探索网络的拓扑和属性信息,来解决图挖掘任务的一系列解决方案和措施。 从这次综述来看,我们认为GRL方法还处于早期阶段。GRL在多个领域的成功部分归功于: (1) 泛化和适应性**。RL方法通过将图挖掘任务表示为具有顺序决策特征的MDP,实现了自适应学习,在不考虑网络结构对预测性能影响的情况下,能够在不同拓扑的网络中学习特定的目标。(2) 数据驱动,高效。现有的图数据挖掘方法引入了丰富的专家知识或需要人工开发一些规则[7,18,36],而RL方法可以在没有专家知识的情况下快速学习,这些方法可以更有效地实现学习目标。对于这些利用RL方法解决图数据挖掘问题的工作,目前已有的综述非常有限,因此有必要对GRL的方法和框架进行系统的综述。本文综述了上述领域的最新研究现状和趋势,并对现实世界中一些具体问题的大量文献进行了总结,以证明GRL的重要性。我们的目的是为不同的方法提供一个直观的理解和高层次的洞察,使学者们可以选择合适的探索方向。据我们所知,这是对GRL中各种方法进行全面综述的最新工作。
本文的主要贡献如下:
- 全面综述。本文对现代图数据的GRL技术进行了系统和全面的综述,并根据RL方法的研究领域和特点对GRL文献进行了分类,这些方法专注于用RL解决图数据挖掘问题。
- 最近的文献。我们总结了最近关于GRL的工作,并对现实世界的应用进行了研究。通过此次综述,我们希望能为图挖掘和RL社区提供一个有用的资源和全局视角。
- 未来的发展方向。讨论了GRL研究的新方向,并提出了六个可能的未来研究方向:自动化RL、分层RL、多智能体RL、子图模式挖掘、可解释性和评价指标。
- 资源丰富。我们收集了关于GRL的丰富资源,包括最先进的模型、基准数据集和开源代码。我们为GRL创建了一个开源的资源库,其中包含了近年来关于GRL的大量论文,按出版年份进行分类。在这个开源的资源库中,我们提供了论文和代码的链接(可选),让学者们更快的了解研究进展和方法,并为GRL的研究提供更多的灵感。
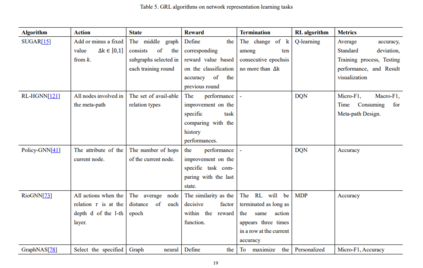
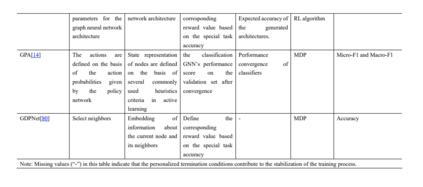
本综述的其余部分组织如下。第二节简要介绍了本文讨论的图数据挖掘概念,并简要回顾了GRL研究中常用的关键算法。在第三节中,我们回顾了目前关于GRL的一些研究,并列出了该研究的状态、行动、奖励、终止、RL算法和评价指标。在第四部分,我们讨论并提出了一些未来的研究方向和挑战。最后,我们在第5节对本文进行了总结。
图强化学习 Reinforcement Learning on Graph
利用RL方法解决图数据挖掘问题的现有方法主要集中在网络表示学习、对抗攻击、关系推理等方面。此外,许多实际应用从不同的角度研究了GRL问题。本节将详细介绍GRL的研究进展。 数据&开源资源**
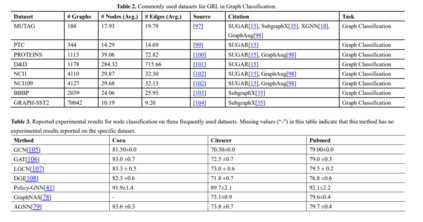
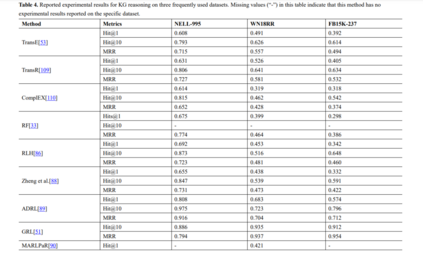
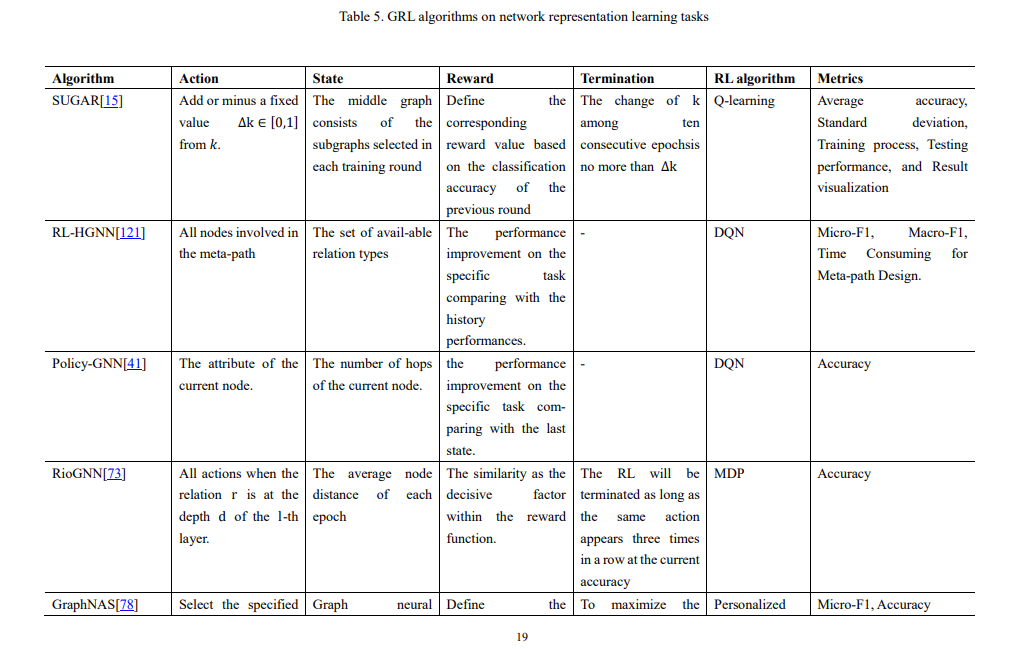
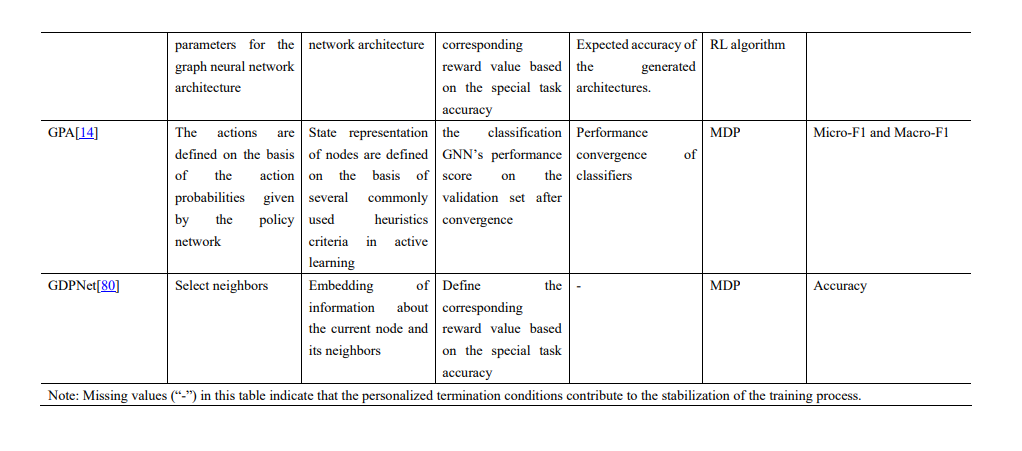
我们提供了在本综述中引用的这些研究中使用的实验数据集的总结,以及数据集、来源、任务和使用这些数据集的方法的统计信息列表,如表1和表2所示。此外,我们总结了Cora、Citeseer和Pubmed上的节点分类实验结果,以及NELL995、WN18RR和FB15K-237上的知识图推理结果,其中,分类精度是节点分类任务的评价指标,Hit@1、Hit@10、和MRR为知识图推理的评价指标,如表3和表4所示。
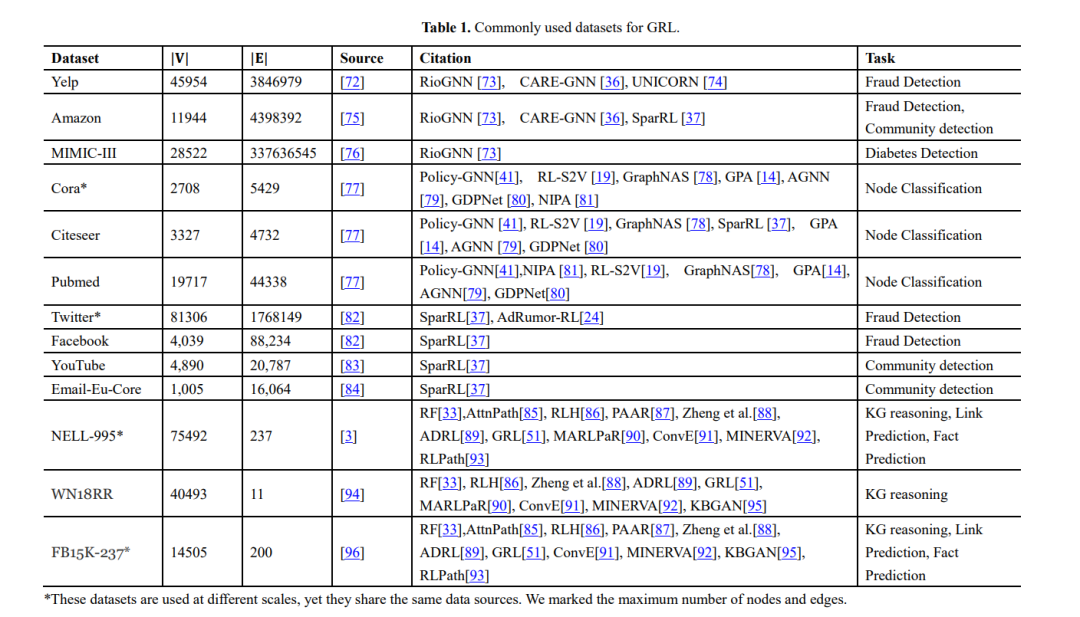
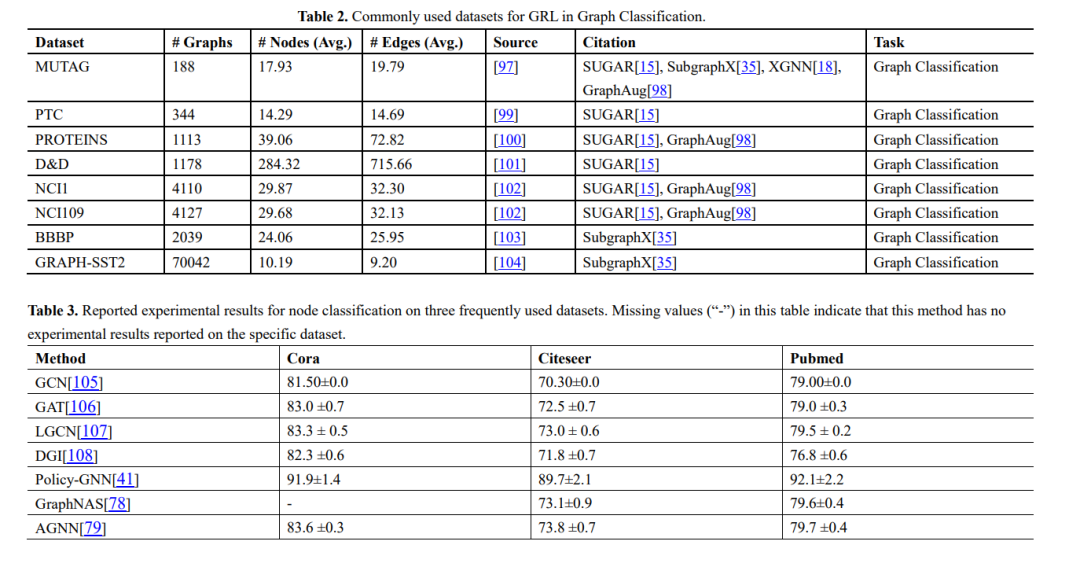
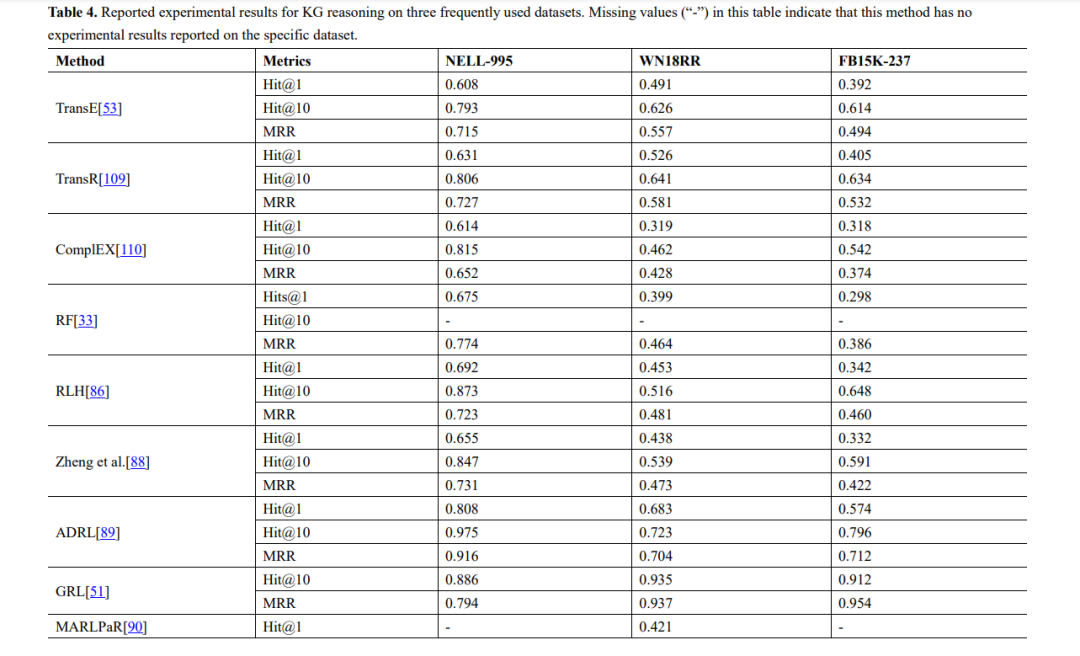
图挖掘强化学习
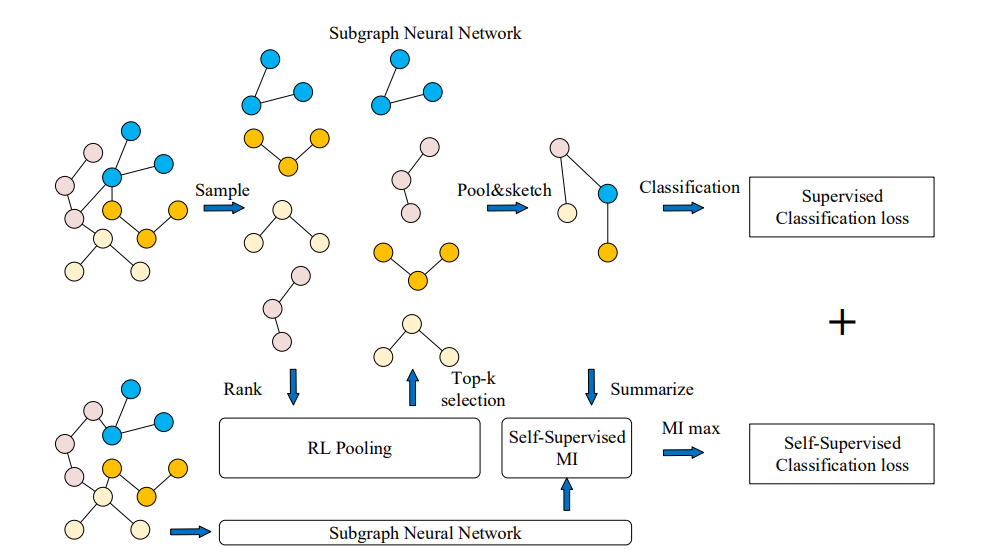
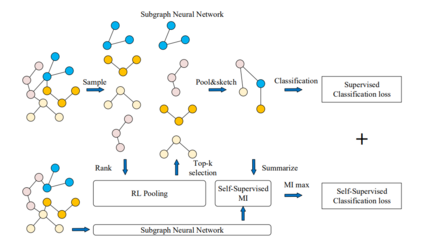
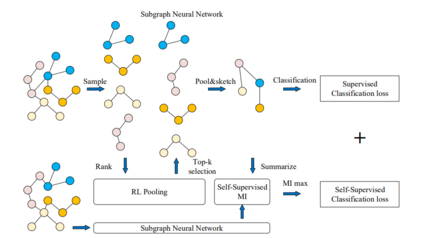
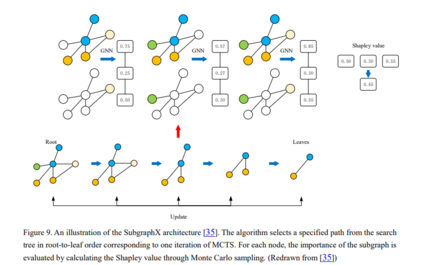
网络表示学习是学习一种映射,将图的节点嵌入为低维向量,同时编码各种结构和语义信息。这些方法旨在优化表示,使嵌入空间中的几何关系保持原始图的结构[111,112]。得到的向量表示可以有效支持节点分类、节点聚类、链接预测和图分类等广泛任务[113,114]。现有的网络嵌入方法[15]普遍存在三个问题: (1) 特征识别能力差。融合所有的特征和关系来获得一个总体的网络表示,往往会带来过度平滑的潜在问题,导致图的特征难以区分。(2) 对先验知识的需求。以相似度量或主题的形式保存结构特征总是基于启发式,并需要大量的先验知识。(3) 低explainability。许多方法通过逐步池化来利用子结构,这会丢失大量详细的结构信息,并导致下游任务缺乏足够的可解释性。为了解决上述问题,SUGAR[15]通过Q-learning自适应地选择有意义的子图来表示图的区别性信息,从而保留了“节点-子图-图”级别的结构信息,这种分层学习方法提供了强大的表示、泛化和可解释性。
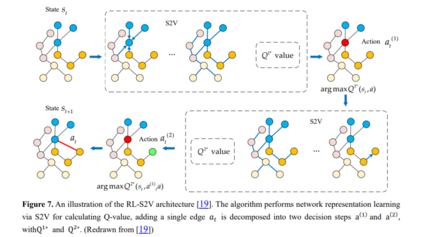
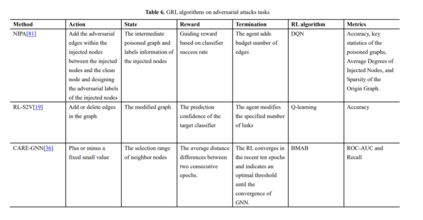
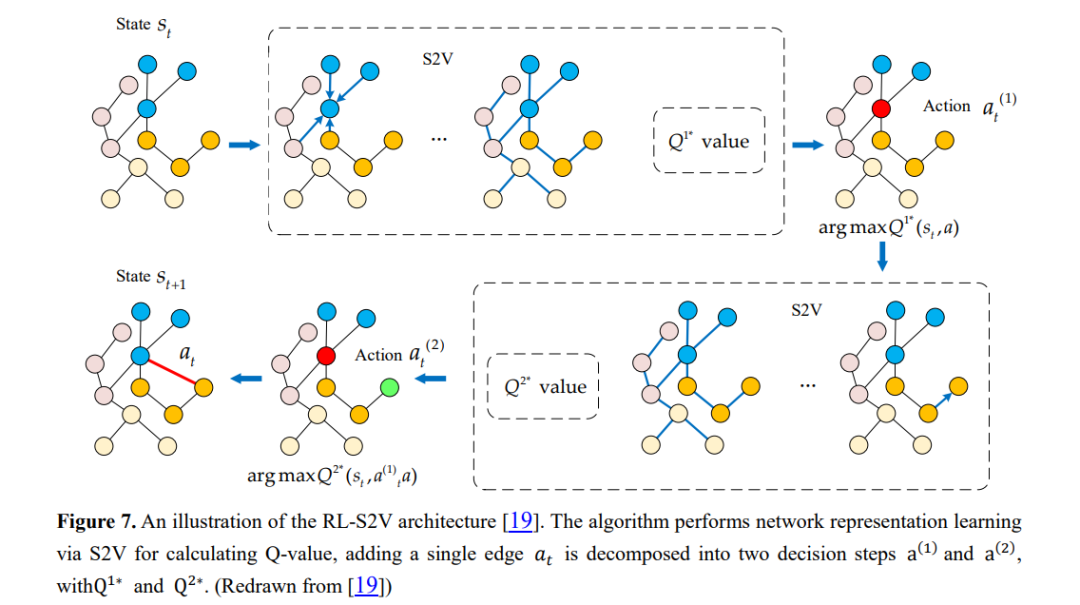
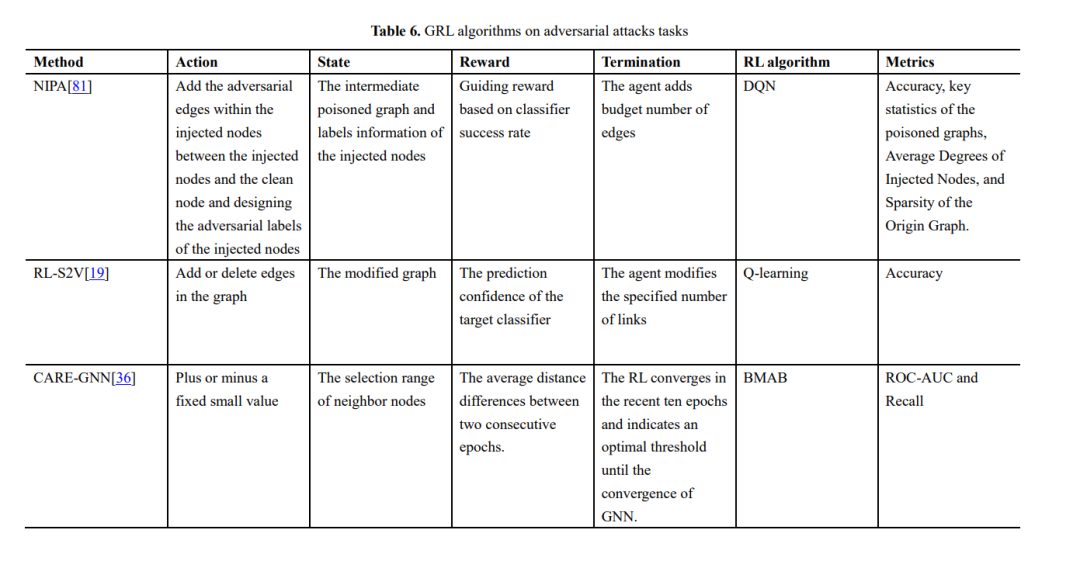
最近的研究表明,GNN是基于图中的节点属性和链接结构进行训练的,攻击者可以通过修改用于训练的图数据来攻击GNN,从而影响节点分类性能[19,122]。目前针对GNN的对抗性攻击的研究主要集中在修改现有节点之间的连通性,攻击者在原始图中注入恶意节点的虚假链接,降低了GNN在现有节点分类中的性能。RL-S2V[19]仅利用下游任务的反馈,学习如何通过顺序添加或删除到图的链接来修改图结构。采用Q-学习算法作为RL模块的实现方案,对网络结构进行顺序修改。该算法用structure2vec对原始图结构进行训练,得到每个节点的表示,然后用图神经网络对每个节点进行参数化,得到Q值,通过Q学习得到需要修改的候选链接,实现黑盒攻击。
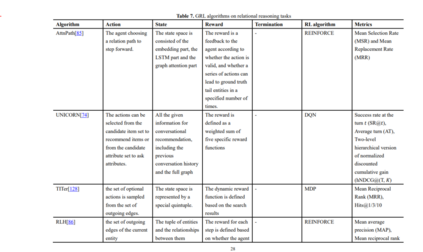
RL方法在从观测数据中发现因果关系方面取得了良好的效果,但在有向无环图空间中搜索因果关系或发现因果关系的隐含条件往往具有较高的复杂性。发现和理解因果机制可以定义为寻找能够最小化已定义分数函数的DAG。具有随机策略的智能体可以在学习策略的不确定性信息的基础上自动定义搜索策略,并利用奖励信号进行快速更新。因此,Zhu等[123]提出利用RL从图空间中寻找底层的DAG,而不需要平滑的评分函数。该算法采用Actor-Critic作为搜索算法,输出训练过程中生成的所有图中,得到奖励最好的图。然而,该方法存在计算分数较差的问题,由有向图组成的动作空间通常难以完全探索。Wang等人[124]通过将RL方法整合到基于排序的范式中,提出了基于排序的强化学习(CORL)方法的因果发现。该方法将排序搜索问题描述为一个多步骤MDP,并采用编码器-解码器结构实现排序生成过程,最后基于对每个排序设计的奖励机制,使用RL对所提出的模型进行优化。然后使用变量选择对生成的排序进行处理,以获得最终的因果图。
图强化学习应用
在过去的几年里,关于GRL的研究蓬勃发展,GRL方法在解决现实世界的各种应用中发挥了重要作用,引起了学者们的广泛关注。我们总结了现实世界中在交通网络优化、电子商务网络推荐系统、医学研究中药物结构预测和分子结构生成、控制新冠病毒的网络扩散模型等方面的丰富应用,进一步证明了该领域的发展热点。 可解释性 城市服务 传染病控制 组合优化 医药
图强化学习开放方向
虽然目前学者们已经探索并提出了几种GRL方法,但我们认为该领域仍处于起步阶段,具有很大的探索空间和研究价值,并提出了该领域学者可能感兴趣的一些未来研究方向。
- 自动强化学习
- 层次强化学习
- 多智能体强化学习
- 子图模式挖掘
- 图强化学习可解释性
- 图强化学习评估
结论
网络科学已经发展成为一个跨学科的领域,跨越了物理学、经济学、生物学和计算机科学,具有许多关键的现实世界的应用,并使复杂系统中的实体交互的建模和分析成为可能[170]。在本次综述中,我们对GRL中最先进的方法进行了全面的概述,提出了针对不同图数据挖掘任务的各种解决策略,其中RL方法可以结合起来更好地解决现有的挑战。虽然GRL方法已经在很多领域得到了应用,但更高效的RL与优秀的图神经网络模型的深入结合,有望提供更好的泛化和可解释性,提高对样本复杂度的处理能力。我们希望这次综述能够帮助学者们理解GRL的关键概念,并推动该领域在未来的发展。我们认为,GRL方法可以在日益增长的图结构数据中揭示有价值的信息,使学者和工程师能够更清晰地分析和利用图结构数据。