国际机器学习大会(International Conference on Machine Learning,简称ICML)是机器学习领域的顶级会议。ICML 2025计划于2025年7月13日-7月19日在加拿大温哥华召开。自动化所多篇研究论文被本届会议录用,本文将对相关成果进行介绍,欢迎交流讨论。
**01. **大模型继续预训练中的学习动态
Learning Dynamics in Continual Pre-Training for Large Language Models **作者:**王星锦,Howe Tissue,王露,李林静,曾大军 ★ Spotlight
继续预训练(CPT)是将基础大模型应用于特定下游任务的有效方法。在这项工作中,我们探索了大语言模型在整个CPT过程中的学习动态。我们关注在CPT过程中每个训练步骤下通用领域和下游领域模型性能的动态,并通过相应的测试集损失来衡量性能变化。我们观察到CPT损失曲线是从一条隐藏的预训练曲线到另一条隐藏预训练曲线的转变,并且可以通过解耦数据分布转移和学习率退火的影响来描述CPT曲线。我们提出了结合这两个因素的CPT Scaling Law 可以预测CPT中任何训练步骤和学习率调度的测试集损失。我们的公式展示了对CPT中几个关键因素的全面理解,包括Loss Potential、最大学习率、训练量和预训练数据混合比。此外,我们的方法可以为不同的CPT目标定制训练超参数来平衡通用领域和下游领域的性能。
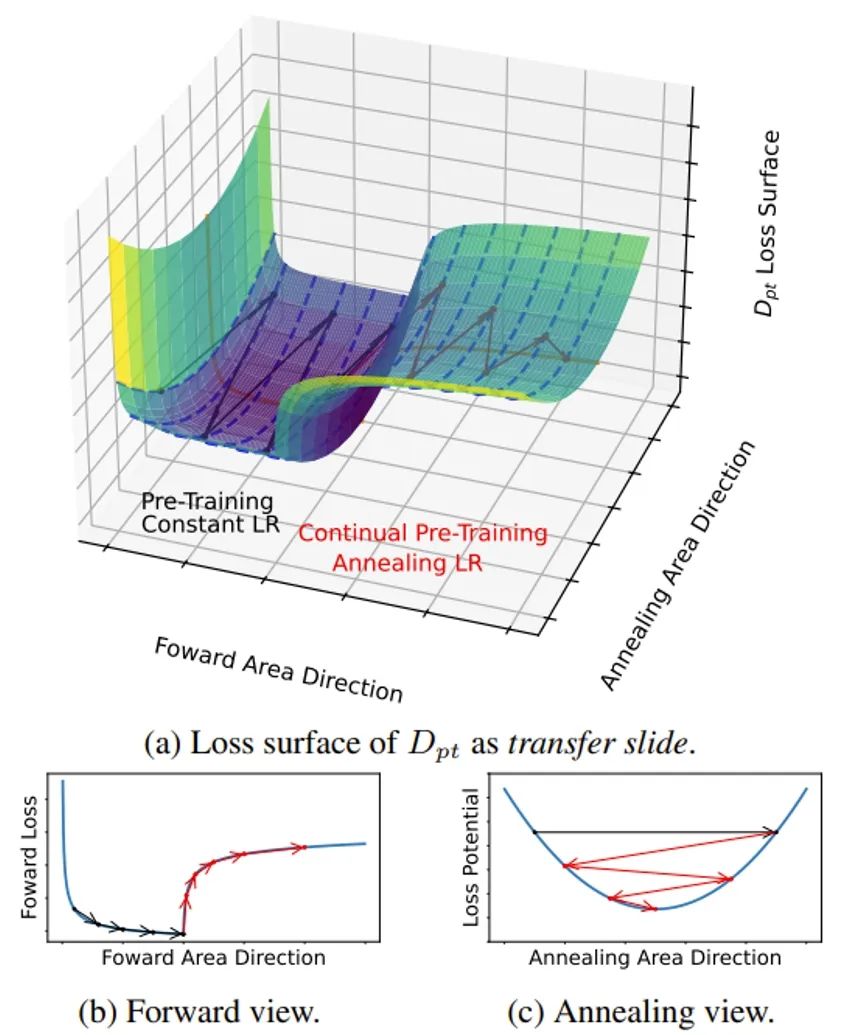
图1. 继续预训练过程中的损失曲面和两个方向的侧视图。前进方向会导致通用领域测试集损失上升和下游领域测试集损失下降,而学习率退火的方向会导致各个测试集损失的快速下降。
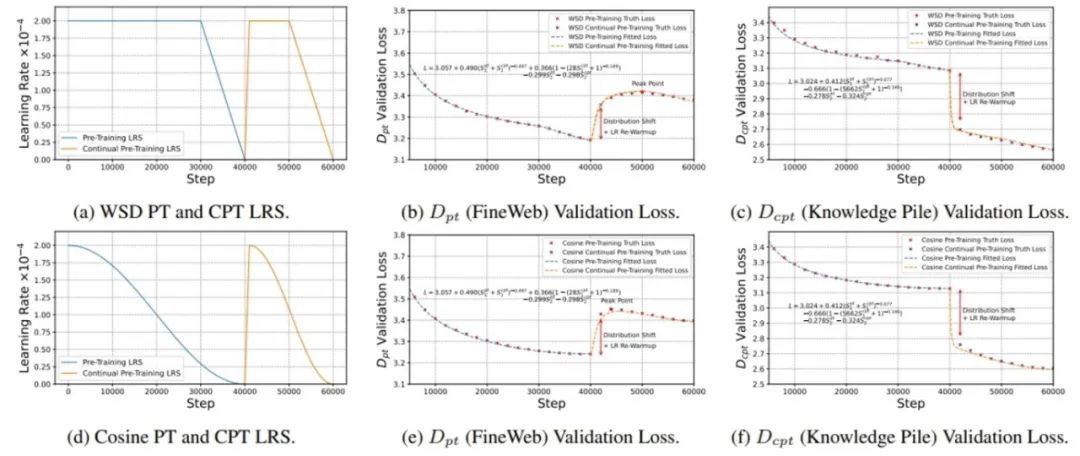
图2. 利用我们提出的CPT Scaling Law对各种学习率调度的预训练和继续预训练阶段的损失曲线进行预测。
**02. **基于树搜索的重排序推理上下文策略以增强大型视觉-语言模型性能
Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger **作者:**杨奇,张承灏,樊鲁斌,丁昆,叶杰平,向世明 ★ Spotlight
近年来,大型视觉语言模型(LVLMs)结合检索增强生成(RAG)技术在视觉问答(VQA)任务中展现出卓越的性能。然而,现有方法仍面临两个关键挑战:一是检索样本缺乏包含推理过程的知识,二是检索到的知识可能和用户问题不一致导致回答出错。为解决这些问题,本文提出了一种基于推理上下文与树搜索的多模态检索增强生成框架。 该框架主要包括两个核心模块:推理上下文丰富的知识库构建和基于启发式奖励的树搜索重排序机制。首先,通过自洽评估机制,自动为问答对生成推理上下文,从而丰富知识库中的逻辑推理模式;其次,采用蒙特卡洛树搜索(MCTS)结合启发式奖励策略,对检索结果进行重排序,优先选择最相关的样例作为上下文输入。这一方法有效提升了LVLMs在生成答案时的一致性与准确性。

图1. 推理上下文生成的示意图。该生成方法包含两个步骤:(a) 利用知识库中的问题-答案对来生成内容自洽的推理上下文。(b) 通过定量评估对预测答案进行验证,以选择最优的推理上下文。

图2. 基于启发式奖励的蒙特卡洛树搜索(MCTS-HR)示意图。为了解决用户的问题,本文首先检索出Top-N个候选样本作为候选动作,随后通过MCTS-HR方法对这些候选样本进行重新排序与选择。此外,本文还提出了一种启发式奖励策略,该策略包含两个关键组成部分:自洽性启发式奖励和互惠启发式奖励,旨在优化MCTS框架中的奖励函数。
**03. **Agent Reviewers:具有共享记忆的多模态领域特定智能体论文评审系统
Agent Reviewers: Domain-speciffc Multimodal Agents with Shared Memory for Paper Review **作者:**卢凯,许世雄,李金秋,丁昆,孟高峰 同行评审的反馈对于提升科学文章的质量至关重要。然而,目前许多稿件在提交之前或提交过程中并未获得足够的外部反馈来进行完善。因此,一个能够提供详细且专业反馈的系统对于提高研究效率来说至关重要。在本文中,我们通过收集历史上的开放获取论文及其相应的评审意见,并使用大语言模型(LLM)对其进行标准化处理,得到了目前最大的论文评审数据集。随后,我们基于大语言模型开发了一个多智能体系统,该系统模拟了真实的人类评审过程。这个名为 “Agent Reviewers”的系统创新性地引入了多模态评审员,用于对论文的视觉元素提供反馈。此外,还保留了一个共享记忆池,其中存储了历史论文的元数据,为评审智能体提供了来自不同领域的背景知识。我们使用 2024 年国际学习表征会议(ICLR)的论文对该系统进行了评估,结果显示其性能优于现有的基于人工智能的评审系统。全面的消融研究进一步证明了该系统中每个模块和智能体的有效性。
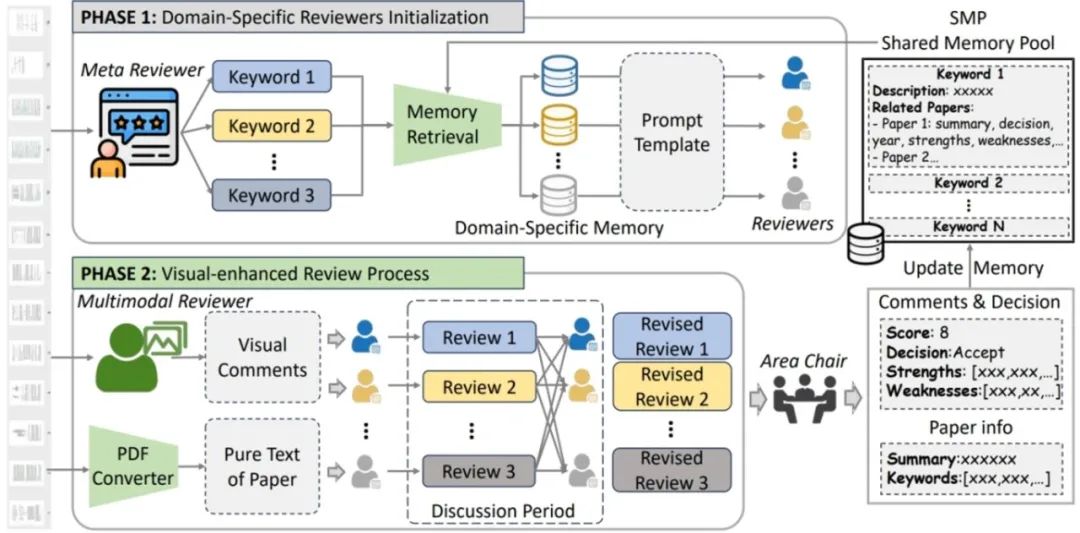
“Agent Reviewers”系统概述。在第一阶段,元审稿人从论文文本中提取关键词,并从共享内存池(SMP)中检索记忆信息,用于初始化特定领域评审员。在第二阶段,多模态审稿人提供论文视觉方面的评论,领域特定审稿人将这些视觉评论与论文文本相结合进行初步评审,并进行讨论以修订意见。最后,领域主席(AC)整合所有经过修订的评审意见,给出最终评论并做出接收决定,并用论文信息和审稿意见更新共享内存池(SMP)。
**04. **受限可利用度下降:一种求解混合策略纳什均衡的离线强化学习方法
Constrained Exploitability Descent: An Offline Reinforcement Learning Method for Finding Mixed-Strategy Nash Equilibrium **作者:**陆润宇,朱圆恒,赵冬斌 本文提出了受限可利用度下降(CED),一种求解对抗马尔可夫博弈的无模型离线强化学习算法,将可利用度下降(ED)这种博弈论方法与离线强化学习中的策略约束方法相结合。策略约束在单智能体场景下会扰动最优的纯策略解,然而这种扰动对于求解对抗博弈中的混合策略纳什均衡未必是有害的。本文理论证明了当数据集满足完全覆盖条件时,CED能在确定性两人零和马尔可夫博弈中收敛到稳定点。进一步,本文证明了在稳定点处的最小玩家策略具有混合策略纳什均衡的不可利用性质。相比基于模型且优化最大玩家的ED算法,本文提出的CED方法在限制分布偏移的同时不再依赖于广义梯度。通过矩阵博弈、树状博弈和无限时间的足球游戏实验验证了CED能够在完全覆盖的数据集下求解均衡策略,纳什误差显著低于博弈领域已有的VI-LCB-Game算法。在非完全覆盖下,CED则能逐渐降低行为克隆(BC)得到的行为策略的可利用度,在大规模的两队3v3机器人对抗博弈中展现出优于离线自我博弈(OSP)算法的性能。
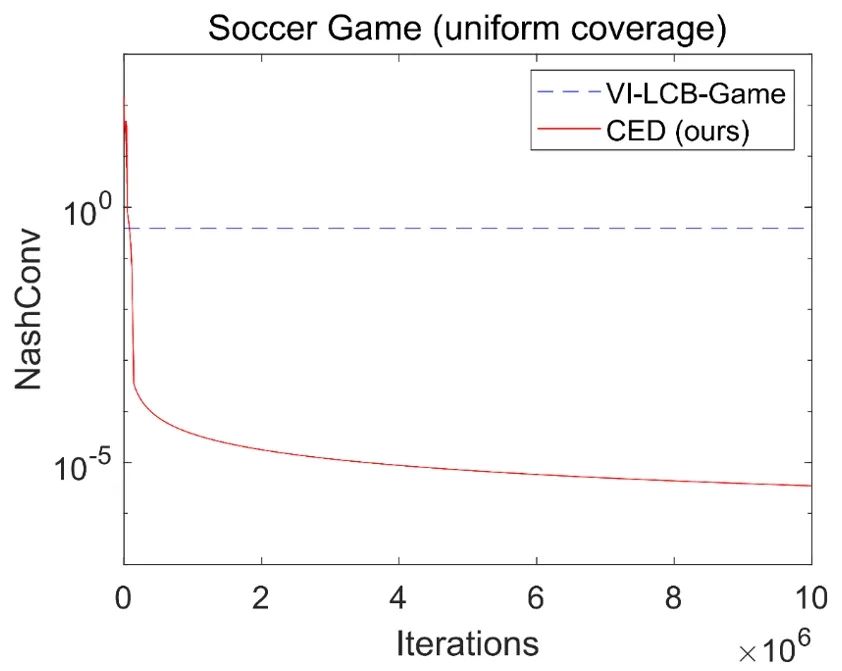
两人足球游戏(完全覆盖数据集)下对比基线算法的纳什误差曲线
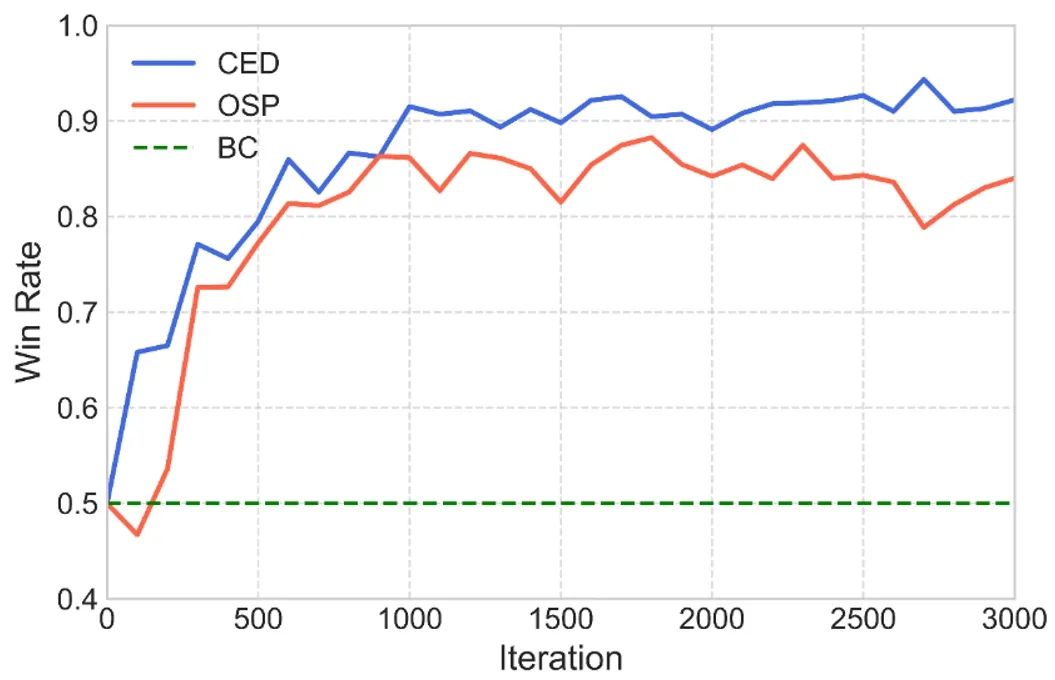
两队3v3机器人对抗博弈(非完全覆盖数据集)下对战行为策略的胜率曲线
**05. **DipLLM:面向强权外交游戏战略决策的微调大语言模型
DipLLM: Fine-Tuning LLM for Strategic Decision-making in Diplomacy **作者:**徐凯旋,柴嘉骏,李思成,傅宇千,朱圆恒,赵冬斌 强权外交(Diplomacy)是一款高度复杂的多人博弈游戏,融合了合作与竞争机制,对人工智能系统提出了严峻挑战。传统方法通常依赖均衡搜索生成大规模博弈数据以训练模型,但该过程计算成本极高。大语言模型(LLMs)提供了一种具有前景的替代方案,能够借助预训练知识,在仅需少量微调数据的前提下实现强大的决策能力。然而,将LLMs应用于强权外交仍面临诸多挑战,包括指数级增长的动作空间和玩家间高度复杂的战略互动。为此,本文提出DipLLM,一种基于LLM微调的智能体,旨在高效学习该游戏中的均衡策略。DipLLM 构建于自回归分解框架之上,将多单位指令决策建模为按单位逐步生成的序列任务,并以理论定义的均衡策略为训练目标。实验结果表明,DipLLM 仅使用Cicero(Science,2022)所需数据量的1.5%进行微调,便实现了2.2%的性能提升,验证了微调后的LLMs在复杂多人博弈中的战略决策潜力。
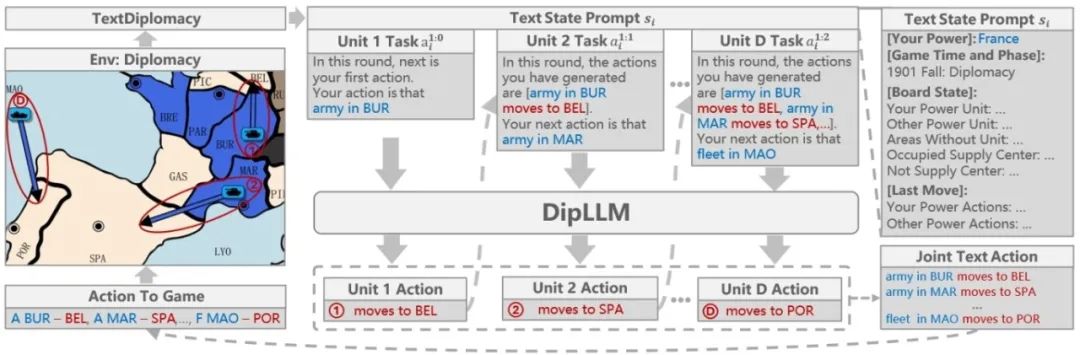
图1. 基于大语言模型的自回归分解智能体的推理流程图
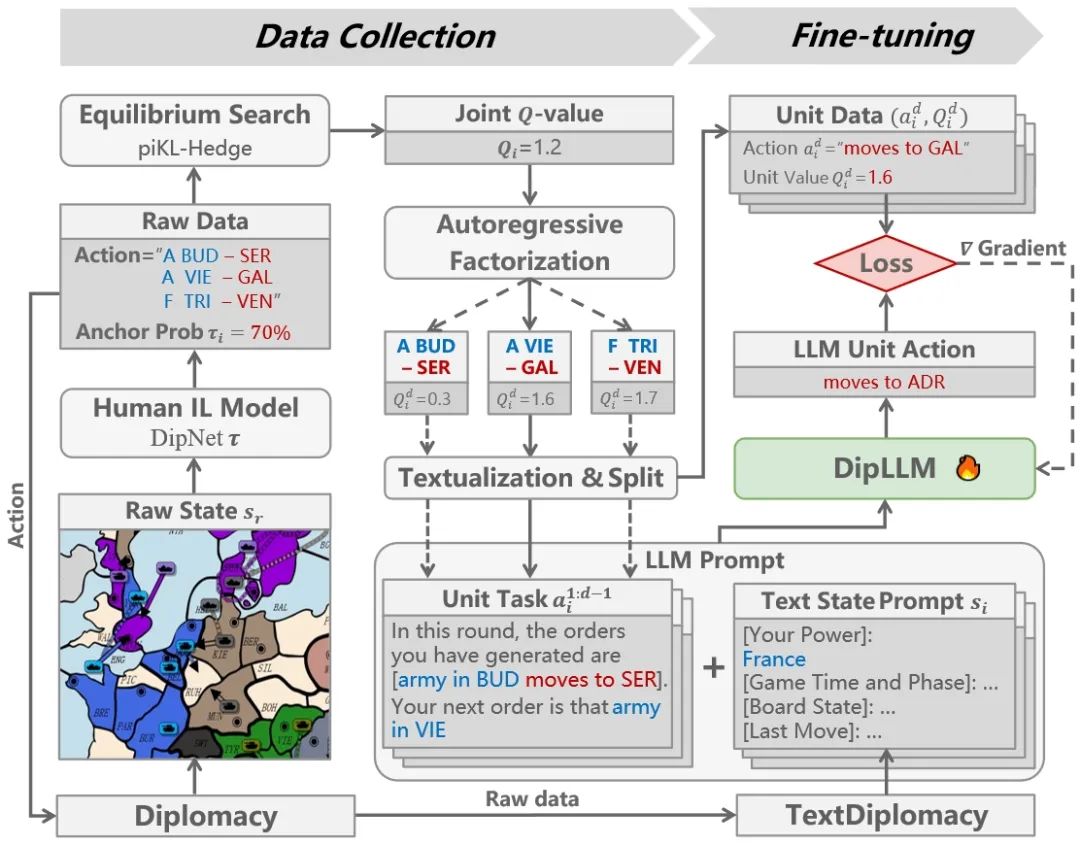
图2. 基于大语言模型的自回归分解智能体的微调流程图
**06. **重新思考联邦异质蒸馏的温度
Rethinking the Temperature for Federated Heterogeneous Distillation **作者:**亓帆,史大旭,徐踔锟,李帅,徐常胜 联邦异质蒸馏是应对联邦学习中模型与数据异构性挑战的一种有效的优化框架。然而,虽然近期的研究提出了一些额外的知识载体来进一步缓解模型异构问题,但是都不可避免地引入了安全风险和显著的计算与通信开销。因此仅使用最小知识载体——logits,在无需公共数据集或额外信息的前提下,能否有效应对联邦学习中的异构问题成为了亟待探索的关键问题。 我们提出了ReT-FHD框架,从理论与实证的角度重新审视蒸馏温度问题。该框架引入多层弹性温度机制,实现模型各层间蒸馏强度的动态调节,同时采用类别感知全局温度缩放策略,根据本地各类别的性能差异为每个类别自适应分配温度,实现更加个性化的知识蒸馏。此外,该框架还集成了Z-Score验证机制,降低标签翻转和模型投毒攻击带来的性能下降风险。 实验表明,ReT-FHD在无需依赖额外信息的情况下,能够在中心化、去中心化及基于区块链的联邦学习场景中有效提升模型性能,同时规避安全风险,并显著降低计算与通信开销。

图1. 算法伪代码
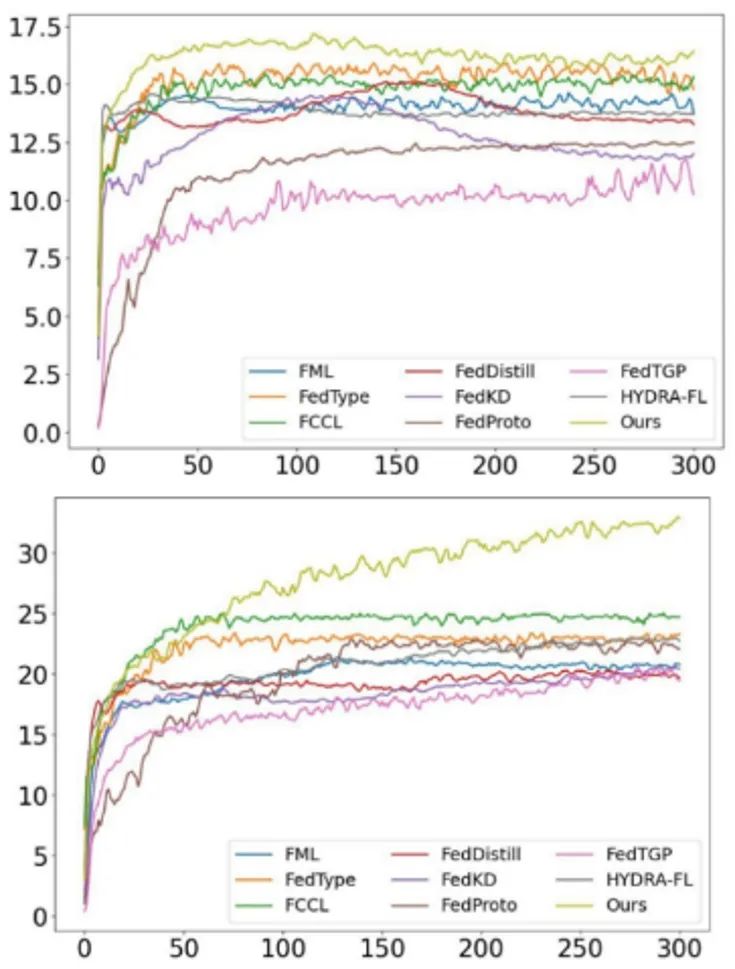
图2. 在TinyImageNet(上)、Flower102(下)上测试的Dir(0.1)分布的准确率曲线
**07. **基于保局马尔可夫状态转移的实例检索
Locality Preserving Markovian Transition for Instance Retrieval **作者:**骆霁飞,吴汶政,姚涵涛,余璐,徐常胜 实例检索(Instance Retrieval)旨在从大规模图像数据库中快速准确地找到与给定查询图像相似的所有图像。为进一步提升检索精度,尤其是弥补初步检索可能存在的误差,重排序(Re-ranking)技术应运而生,它通常通过分析初步检索结果中图像间的关系来优化排序结果。其中,基于扩散的重排序方法因其能够有效地利用数据样本间的相似性关系,通过在近邻图上进行信息传播,从而更好地建模数据流形(data manifolds)结构,展现出良好的性能。然而,这类方法存在一个关键问题:当相似度信号在图上进行多步传播时,距离源点较远的样本其信号会迅速衰减。这意味着传统扩散方法难以有效地捕捉和利用全局范围内的相似性信息,尤其是在局部区域之外,判别能力会显著下降,限制了其在大规模检索中的表现。 为克服这一局限性,我们提出了一个全新的保局马尔可夫转移(Locality Preserving Markovian Transition, LPMT)框架,该框架借助一个具有多个状态的长程热力学转移过程,实现了更精确的流形距离测量。具体来说, LPMT首先利用双向协作扩散(Bidirectional Collaborative Diffusion, BCD)整合不同图上的扩散过程,以此更好地估计相似度关系。随后,局部状态嵌入(Locality State Embedding, LSE)将每个实例编码为一个分布,以增强局部一致性。这些分布通过热力学马尔可夫转移(Thermodynamic Markovian Transition, TMT)过程相互连接,从而在保持局部有效性的同时,实现高效的全局检索。
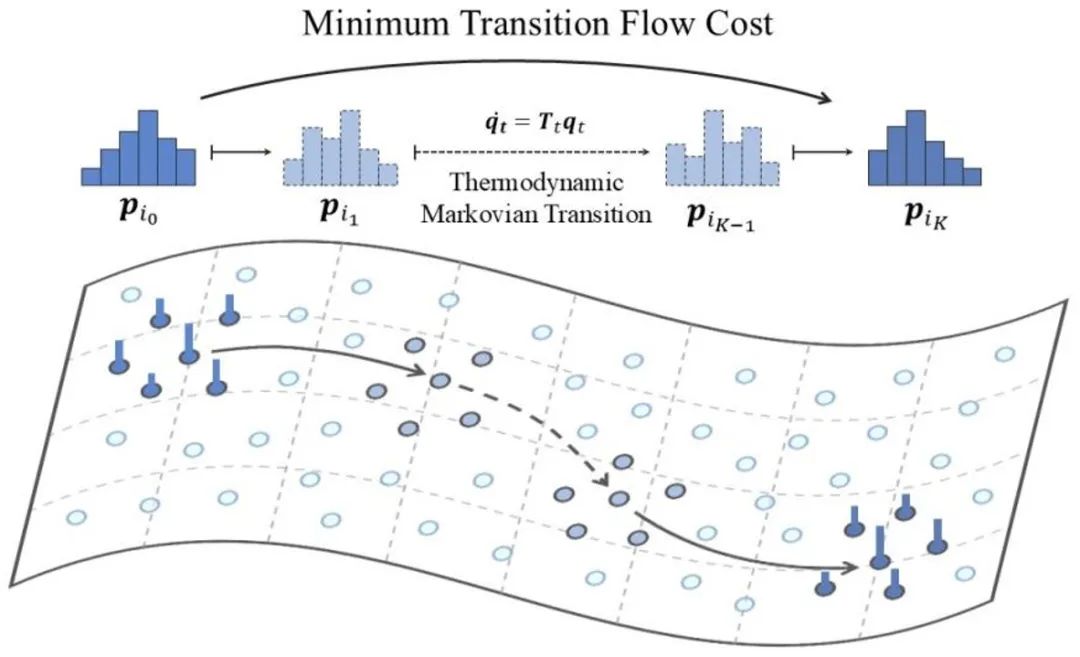
保局马尔可夫状态转移过程示意图
**08. **测试时相关性对齐
Test-time Correlation Alignment **作者:**游琳敬,禄家宝,黄夏渊 深度神经网络常因训练数据与测试数据间的分布偏移而出现显著的性能下降。尽管领域自适应(Domain Adaptation)能在一定程度上解决该问题,但现实场景中的隐私问题往往限制了其对训练数据的访问。这一限制催生了测试时自适应(Test-Time Adaptation, TTA)的研究,TTA仅需利用未标注的测试数据来调整预训练模型。然而现有TTA研究仍面临三大挑战:(1)主要关注实例级对齐,因缺失源域相关性而忽视了相关性对齐(CORrelation ALignment, CORAL);(2)依赖复杂的反向传播机制更新模型,计算开销过大;(3)存在域遗忘问题。 为应对这些挑战,本文首先通过理论分析验证了测试时相关性对齐(Test-time Correlation Alignment, TCA)的可行性,证明高置信度样本与测试样本间的相关性对齐可有效提升模型性能。基于此,本文提出两种简洁且高效的算法:LinearTCA与LinearTCA+。前者通过简单线性变换同时实现实例对齐与相关性对齐,无需额外模型更新;后者作为即插即用模块,可轻松增强现有TTA方法。大量实验证明了我们的理论和算法的有效性,实验结果表明TCA在各类任务、数据集和骨干网络中均显著优于基线。
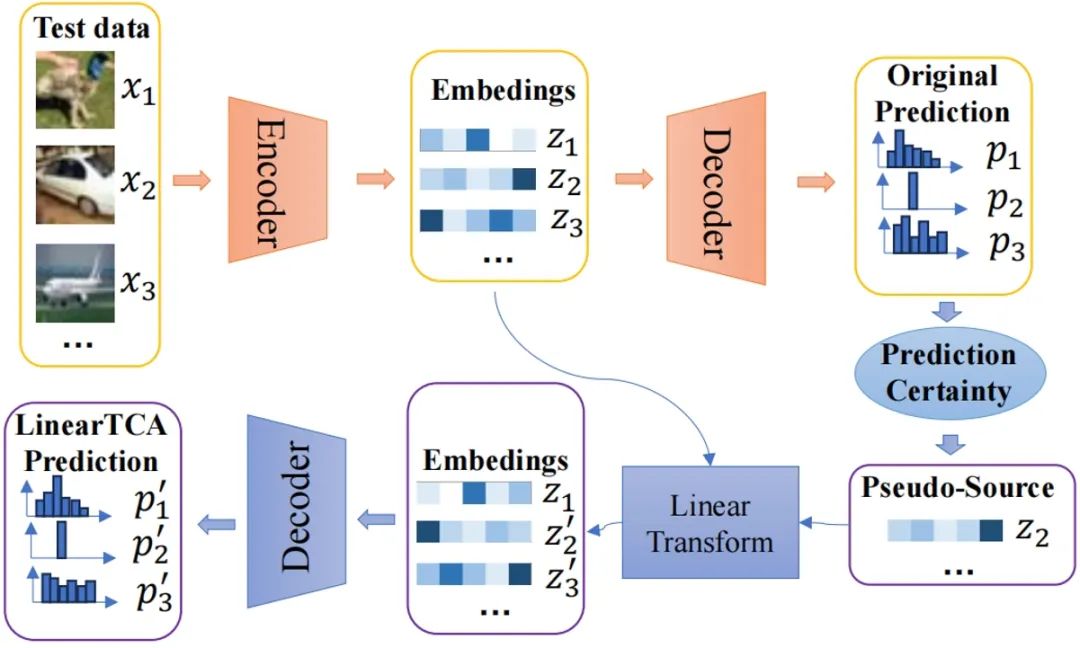
图1. 模型框架。LinearTCA算法的具体流程如下:在测试阶段,首先通源模型获取目标数据的原始嵌入特征和预测结果。根据原始预测结果筛选高置信度嵌入特征,构建"伪源域"。随后施加线性变换,将原始嵌入特征的相关性与伪源域进行对齐,最终输出LinearTCA的预测结果。值得注意的是,该过程无需更新原始模型的任何参数。
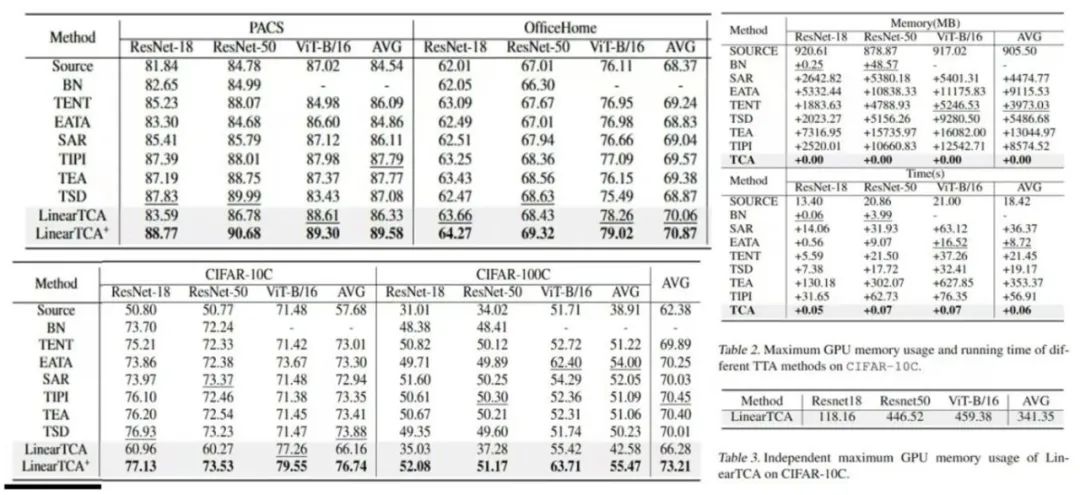
图2. 实验结果。TCA方法在多种数据集、多种网络架构下模型预测准确率、运行时间、最大GPU内存占用的具体性能表现结果。
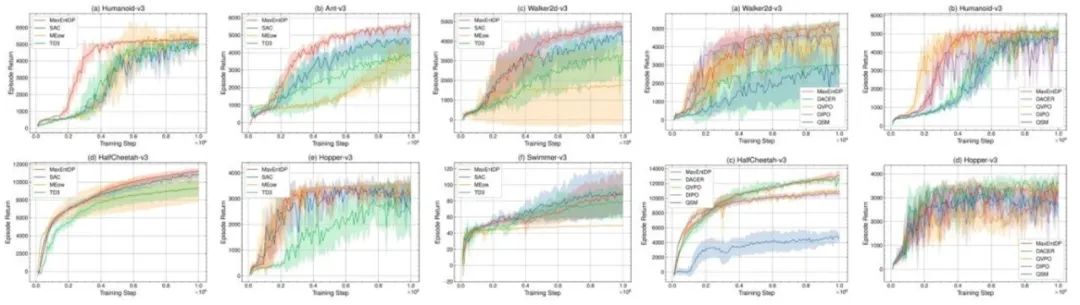
**09. **基于扩散策略的最大熵强化学习算法
Maximum Entropy Reinforcement Learning with Diffusion Policy **作者:**董晓艺,程健,张希 最大熵强化学习将策略熵加入强化学习的目标函数中,来提高智能体的探索能力并增强所学策略的鲁棒性。目前,使用高斯策略的Soft Actor-Critic(SAC)算法已成为实现最大熵强化学习目标的主流算法。尽管高斯策略在简单任务中表现良好,但在复杂的多目标强化学习环境中,其固有的单峰性会限制SAC算法的探索能力和潜在性能。由于扩散模型能够拟合复杂的多峰分布,因此本文在SAC算法中引入扩散模型作为策略表示,提出了一种基于扩散策略的最大熵强化学习算法MaxEntDP,可以实现高效探索,并使策略更接近最大熵强化学习目标下的最优策略。MaxEntDP算法的训练过程涉及两个关键步骤:拟合Q函数的指数分布以及计算扩散策略的对数概率,这对于扩散模型而言并非易事。为了解决这两个挑战,我们提出了一种Q加权噪声估计(Q-weighted Noise Estimation)方法来训练扩散策略,同时引入一种数值积分方法来近似计算扩散模型的对数概率。在Mujoco基准测试上的实验结果表明,MaxEntDP在最大熵强化学习框架下优于高斯策略和其他生成模型,并且性能与现有基于扩散模型的在线强化学习算法相当。
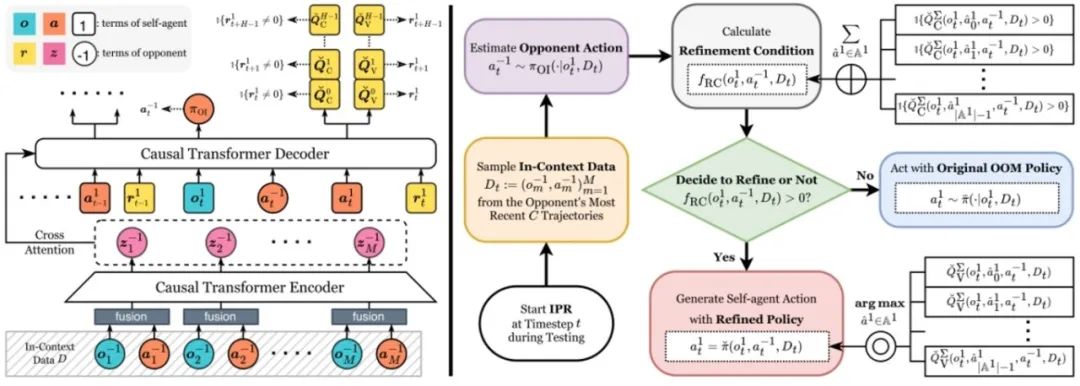
**10. **离线对手建模算法改进框架:截断Q驱动的即时策略精炼
Offline Opponent Modeling with Truncated Q-driven Instant Policy Refinement **作者:**景煜恒,李凯,刘秉运,张紫闻,傅浩波,付强,兴军亮,程健 离线对手建模(OOM)旨在使用来自多智能体博弈的离线数据集,学习一种能够动态适应对手的自适应自主智能体策略。先前的工作假设数据集是最优的。然而,这个假设在现实世界中难以满足。当数据集是次优的时,现有方法难以有效工作。为了解决这个问题,我们提出了一个简单且通用的算法改进框架,即由截断Q驱动的即时策略精炼(TIPR),以处理由数据集引发的OOM算法的次优性问题。TIPR框架本质上是即插即用的。与原始的OOM算法相比,它仅需要两个额外的步骤:(1)使用离线数据集学习一个时域截断的、基于上下文的动作价值函数,即截断Q(Truncated Q)。截断Q估计在一个固定的、截断的时域内的期望回报,并且以对手信息为条件。(2)在测试期间,使用学习到的截断Q来即时决定是否执行策略精炼,并在精炼后生成策略。理论上,我们从无最大化偏差概率的角度分析了截断Q的原理。实验上,我们在四个代表性的竞争环境中进行了广泛的比较实验和消融实验。TIPR有效地改进了多种使用次优数据集预训练的OOM算法。
**11. **基于目标导向技能抽象的离线多任务强化学习
Goal-Oriented Skill Abstraction for Offline Multi-Task Reinforcement Learning **作者:**何金珉,李凯,臧一凡,傅浩波,付强,兴军亮,程健 离线多任务强化学习旨在利用预先收集的数据集学习一个统一的策略,以在无需与环境进行任何在线交互的情况下解决多个任务。然而,该领域在跨任务有效共享知识方面面临巨大挑战。受人类学习中高效知识抽象机制的启发,我们提出了一种新方法——面向目标的技能抽象GO-Skill,旨在提取和利用可复用技能,以提升离线多任务强化学习中的知识迁移能力和任务表现。我们的方法通过目标导向的技能提取过程挖掘可复用技能,并利用向量量化构建离散技能库。为缓解广泛适用技能与任务特定技能之间的类别不平衡问题,我们引入了一个技能增强阶段,对提取出的技能进行优化。此外,我们通过分层策略学习将这些技能整合起来,从而构建出一个高层策略,能够动态组合离散技能以完成特定任务。在MetaWorld基准平台的多种机器人操作任务中进行的大量实验表明,GO-Skill在有效性和通用性方面都具有显著优势。
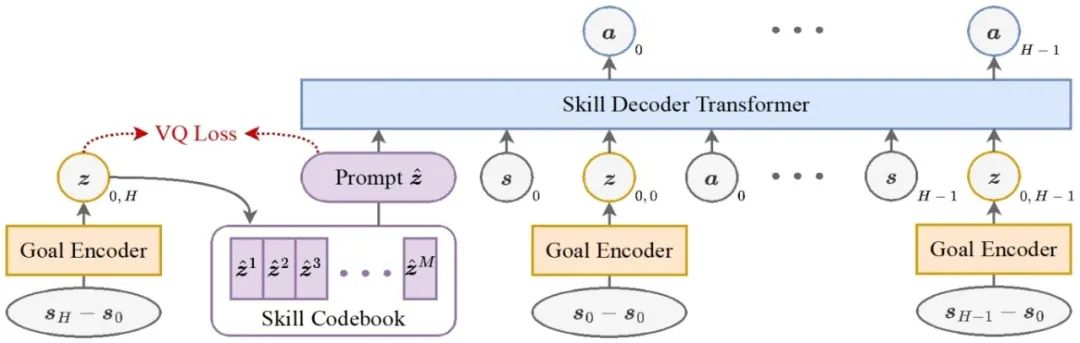
图1. GO-Skill目标导向的技能模型
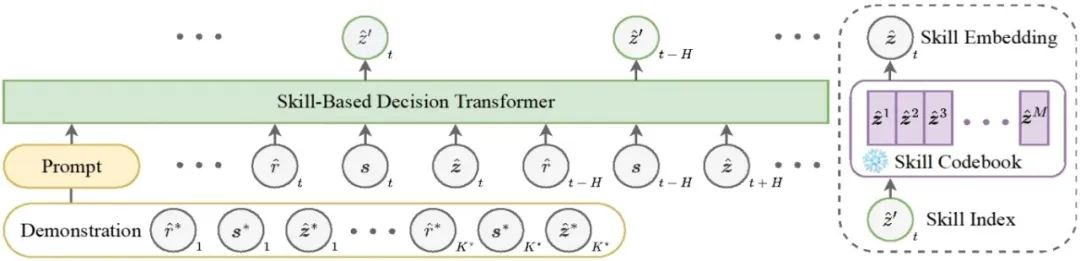
图2. GO-Skill基于技能的策略模型
**12. **CSTrack: 通过紧凑时空建模来增强RGB-X跟踪
CSTrack: Enhancing RGB-X Tracking via Compact Spatiotemporal Features **作者:**丰效坤,张岱凌,胡世宇,李旭晨,武美奇,张靖,陈晓棠,黄凯奇 有效建模和利用来自RGB及其他模态(例如,深度、热成像和事件数据,简称为X)的时空特征是RGB-X追踪器设计的核心。现有方法通常采用两个平行分支分别处理RGB和X输入流,这要求模型同时处理两个分散的特征空间,复杂化了模型结构和计算过程。更为关键的是,每个分散空间内模态内的空间建模会产生较大的计算开销,限制了用于模态间空间建模和时间建模的资源。为了解决这一问题,我们提出了一种新的追踪器,CSTrack,其重点是建模紧凑的时空特征,以实现简单而有效的追踪。具体来说,我们首先引入了一个创新的空间紧凑模块,将RGB-X双输入流整合为紧凑的空间特征,从而实现彻底的模态内和模态间空间建模。此外,我们设计了一个高效的时序紧凑模块,通过构建优化的目标分布热图紧凑地表示时间特征。广泛的实验验证了我们紧凑时空建模方法的有效性,CSTrack在7个主流RGB-X基准上取得了新的SOTA结果。
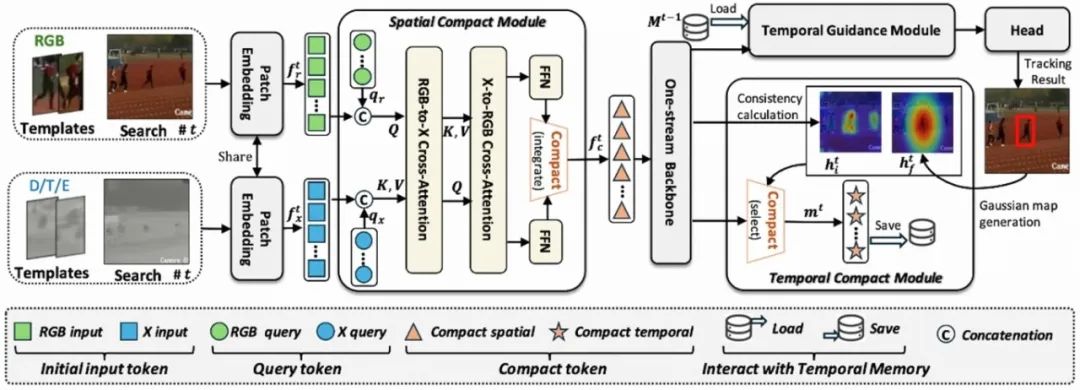
CSTrack的模型框架。对于时间t时刻的RGB和X(例如热成像数据)输入流,通用的嵌入模块最初将它们转换为token序列。然后,空间紧凑模块将它们整合为一个紧凑的特征空间,该特征空间随即被输入到单流骨干网络中进行全面的空间建模。接下来,时间指导模块利用之前存储的时间特征进行追踪指导,随后跟踪头生成最终的追踪结果。之后,时间紧凑模块为当前时间步构建紧凑的时间特征,这些特征被存储以便在下一时间步t + 1进行追踪引导。
**13. **基于双层优化的大语言模型数据选择与利用
LLM Data Selection and Utilization via Dynamic Bi-level Optimization **作者:**于杨,韩凯,周航,唐业辉,黄凯奇,王云鹤,陶大程 尽管大规模训练数据是构建高性能大型语言模型(LLM)的基础,但如何战略性地筛选高质量数据,已成为提升训练效率与降低计算成本的关键途径。现有数据选择方法主要依赖静态、与训练过程无关的标准,难以反映模型在训练过程中对数据的动态需求。为此,本文提出一种新的数据加权模型(DWM),用于动态调整每一批次训练数据的权重,从而实现训练过程中更有效的数据利用。为更精准地捕捉模型的动态数据偏好,DWM采用双层优化框架进行更新。实验结果表明,DWM不仅提升了相较于随机数据选择所训练模型的性能,且其所学习的加权策略具有良好的迁移能力,可推广至其他数据选择方法及不同规模模型中。进一步分析还揭示了模型在训练过程中数据偏好的演化规律,为理解LLM的数据利用机制提供了新的视角。

基于DWM的双层优化框架,其中LLM模型和加权模型交替训练
**14. **从概率神经-行为表征对齐中涌现的神经表征一致性
Neural Representational Consistency Emerges from Probabilistic Neural-Behavioral Representation Alignment **作者:**朱宇,宋纯锋,欧阳万里,余山,黄铁军 大脑在不同个体间存在显著的结构和生理差异,却能产生高度一致的功能特性,这一悖论在神经科学领域尚未得到充分探索。虽然近期研究已通过手动对齐方法观察到运动皮层中跨个体的神经表征保留现象,但对这种保留特性的零样本验证及其在多种皮层区域中的普适性仍有待深入研究。本研究提出了概率神经-行为表示对齐(PNBA)框架,该框架采用概率模型处理不同试验、实验时段和个体间的层次性差异,并通过生成性约束防止表示退化。PNBA通过建立稳健的跨模态表示对齐,成功地通过零样本验证揭示了猴子初级运动皮层(M1)和背侧预运动皮层(PMd)中稳定保留的神经表示模式。我们还将研究扩展至小鼠初级视觉皮层(V1),证实了类似的表征保留现象,表明这可能是一种普遍的神经组织原则。这些发现通过建立零样本预测范式有效解决了神经异质性悖论,实现了跨脑区和跨物种的神经表征迁移,不仅深化了对神经编码机制的理解,还为零样本行为解码提供了新的方法论基础。
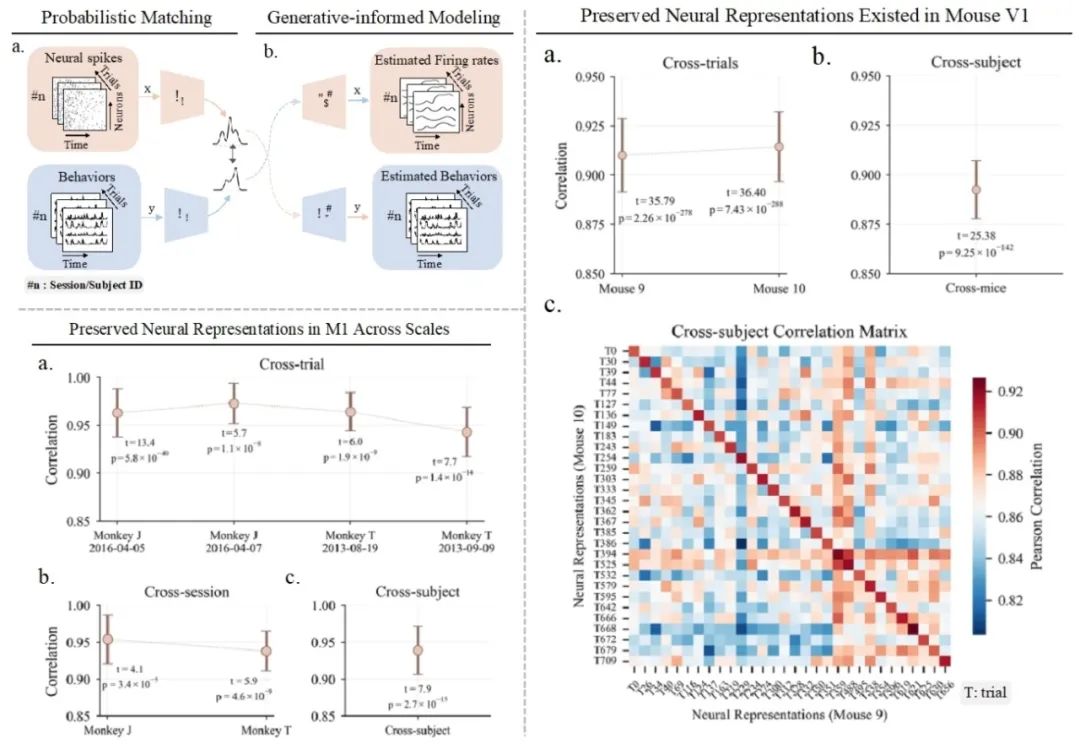
PNBA方法及其在不同物种皮层中揭示的保留神经表征。左上:PNBA方法框架。(a) 通过概率匹配策略对神经活动与行为表征进行对齐,有效处理不同个体间的神经异质性。(b) 生成性约束建模确保表征稳定性,防止退化现象。左下:猴子运动皮层(M1)中跨尺度的保留神经表征。(a) 神经元活动模式在不同个体间存在共性特征。(b-c) 零样本验证结果表明,尽管存在神经异质性,单一共享网络仍能在新个体上准确预测行为,证实了M1中神经编码的跨个体保留特性。右侧:小鼠初级视觉皮层(V1)中发现的保留神经表征。(a) V1中神经活动序列的跨个体共性特征。(b) 不同视觉刺激诱发的神经响应保留模式。(c) 零样本迁移结果显示V1表征在不同个体间的一致性,支持神经编码保留现象的普适性。
**15. **MM-RLHF:多模态大模型对齐的新里程碑
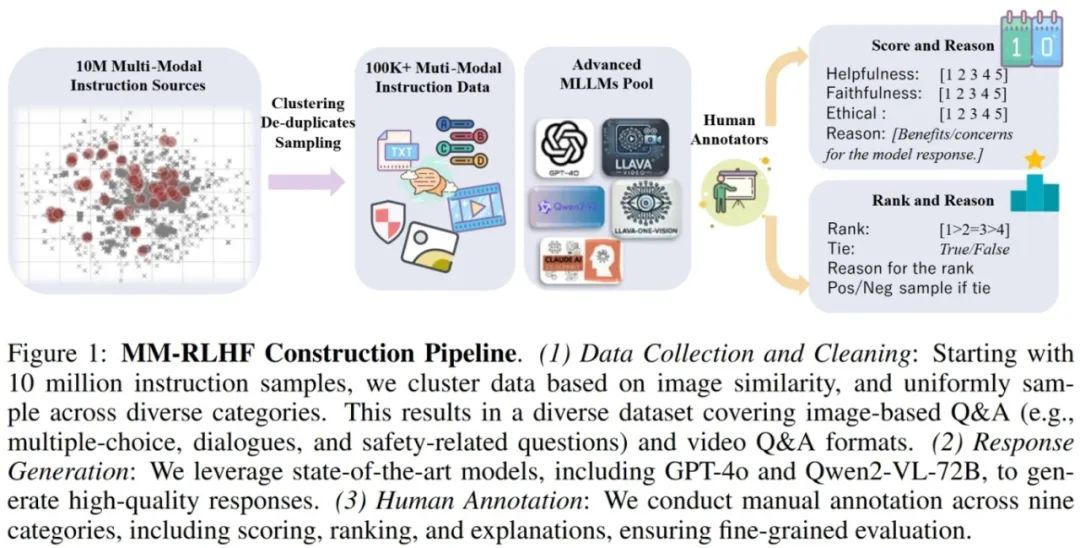
MM-RLHF: The Next Step Forward in Multimodal LLM Alignment **作者:**张一帆,于涛,田浩辰,傅超友,李沛言,曾建树,谢武林,史阳,张桓瑜,吴俊康,王雪,胡一博,文彬,杨帆,张彰,高婷婷,张迪,王亮,金榕,谭铁牛 尽管多模态大语言模型(MLLMs)取得了显著的进展,但现有的先进模型仍然缺乏与人类偏好的充分对齐。这一差距的存在主要是因为现有的对齐研究多集中于某些特定领域(例如减少幻觉问题),是否与人类偏好对齐可以全面提升MLLM的各种能力仍是一个未知数。 本文从三个层面入手推动MLLM alignment的发展,包括数据集,奖励模型以及训练算法,最终的alignment pipeline使得不同基础模型在10个评估维度,27个benchmark上都取得了一致的性能增益,比较突出的是,基于本文提出的数据集和对齐算法对LLaVA-ov-7B模型进行微调后, conversational 能力平均提升了 19.5%,安全性平均提升了 60%, 而且没有观察到安全性和基础性能之间的tradeoff。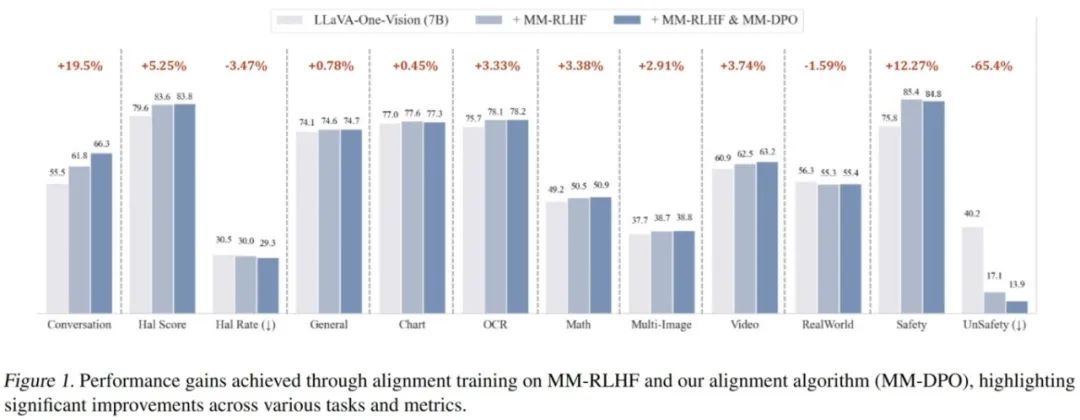
**16. **自适应中值平滑:在推理阶段对遗忘后文生图扩散模型的对抗防御
Adaptive Median Smoothing: Adversarial Defense for Unlearned Text-to-Image Diffusion Models at Inference Time **作者:**韩晓轩,杨嵩林,王伟,李洋,董晶 文生图扩散模型引发了关于生成不当内容(如色情暴力)的担忧,尽管已有工作尝试通过机器遗忘技术来擦除模型中的不良概念,这些遗忘后模型仍然容易受到对抗性输入的攻击,进而重新生成不良内容。为保护遗忘后模型,我们提出了一种新颖的推理阶段防御策略,用以缓解对抗性输入的影响。具体而言,我们首先将确保遗忘后扩散模型鲁棒性的挑战建模为一个鲁棒回归问题。在原始的中值平滑方法基础上,我们提出了使用各向异性噪声的广义中值平滑框架,为模型的对抗鲁棒性提供了理论保证。基于该框架,我们引入了一种基于词元自适应调整的中值平滑方法,能够根据每个词元与不良概念的相关程度动态调整噪声强度。此外,为提升推理效率,我们在文本编码阶段实现了该自适应方法。实验表明,我们的方法有效提升了遗忘后模型的对抗鲁棒性,同时保持了模型效用和推理效率。
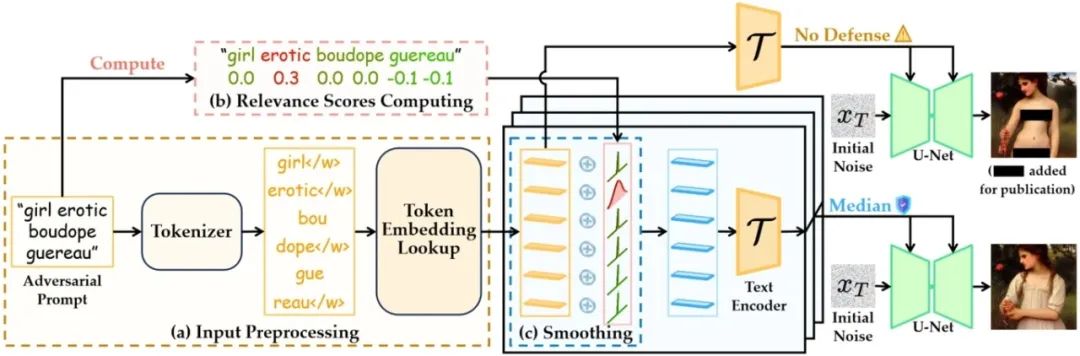
自适应中值平滑流程图
**17. **基于少样本学习实现AI生成图像跨域检测泛化
Few-Shot Learner Generalizes Across AI-Generated Image Detection **作者:**吴诗雨,刘静,李晶,王业全 图像生成模型的快速发展使得AI合成图像达到前所未有的逼真程度。尽管这项技术为创作者提供了便利,但其滥用已严重威胁数字内容的可信性。当前检测方法面临两大核心挑战:一是检测器对未知生成模型图像的泛化能力不足,难以适应持续迭代的生成技术发展。二是闭源模型训练数据的获取存在显著成本壁垒。多数方案依赖大规模训练数据的支持,在少样本应用场景中易出现过拟合现象,难以满足实际应用中快速响应新型生成模型的技术需求。 针对上述挑战,本文首次将AI生成图像检测重构为小样本分类任务。论文提出基于原型网络构建度量空间,利用给定的少量样本计算合成图像的原型表征,通过与待测图片表征差异的比较,实现合成图像检测的跨域泛化。实验表明,论文提出的图像检测框架具有良好的泛化性和适应性,在主流基准测试上取得了新的突破。该方法通过构建动态适配机制,可快速兼容新兴生成模型,为应对持续演进的图像深度伪造技术提供有效解决方案。
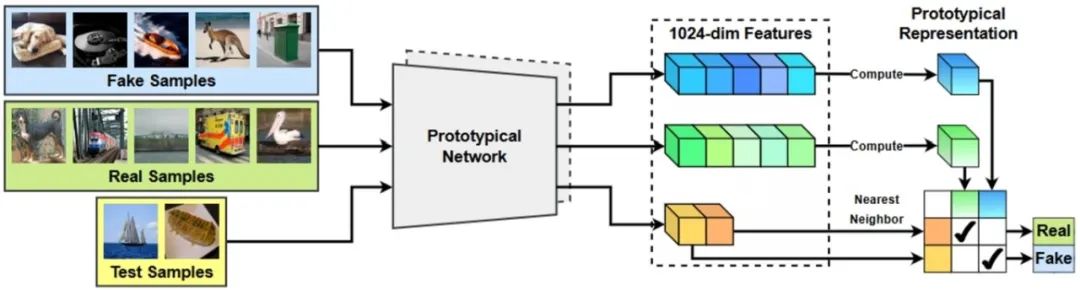
基于原型网络的AI合成图片检测框架
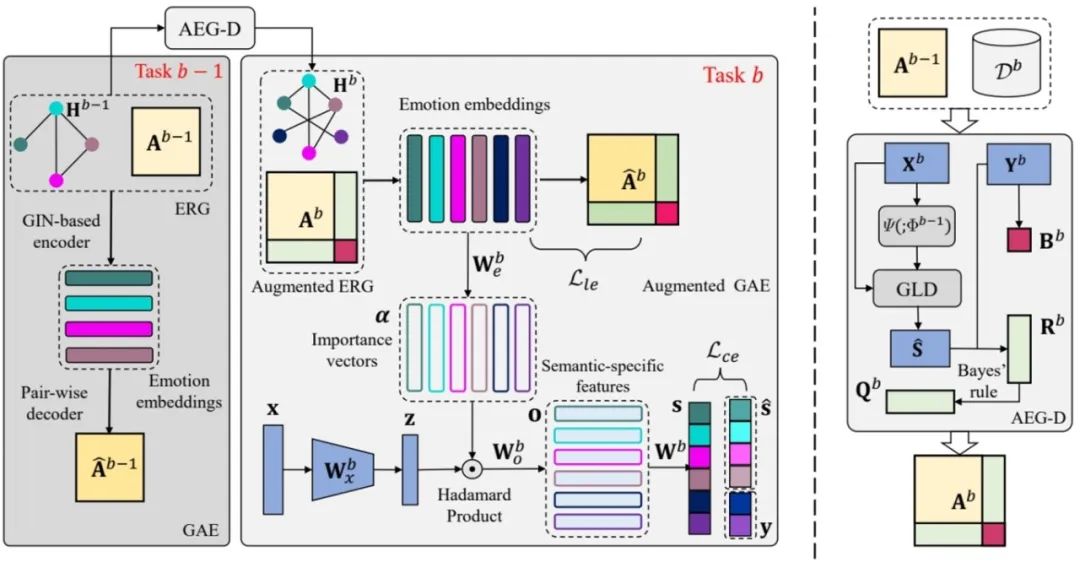
**18.**EmoGrowth:基于可增广情绪关系图的多标签类增量情绪解码
EmoGrowth: Incremental Multi-label Emotion Decoding with Augmented Emotional Relation Graph **作者:**付铠城,杜长德,彭杰,王坤鹏,赵双辰,陈晓宇,何晖光 情绪解码算法在人机交互系统中扮演着重要角色。然而,现有的情绪解码算法忽略了现实世界中的动态场景,即人类感受到的复杂多样的情绪需要增量地整合到模型中,产生了多标签类增量情绪解码问题。已有的模型受限于由过去和未来部分标签缺失造成的灾难性遗忘以及未充分挖掘标签的语义信息,难以解决多标签类增量学习问题。由此,本文提出一个可增广的情绪语义学习框架。具体地,设计了一个带有标签消歧的可增广情绪关系图模块,用于处理过去部分标签缺失问题。接着,利用来自情感维度空间的领域知识,通过基于样本关系的知识蒸馏缓解未来部分标签缺失问题。此外,研究中设计了一个由图自编码器构成的情绪语义学习模块,用于获取情绪语义标签嵌入,并用于指导语义特定的特征解耦,用以更好地进行多标签学习。