近年来,以强化学习(Reinforcement Learning, RL)为核心的训练方法显著提升了大语言模型(Large Language Models, LLMs)的推理与对齐性能,特别是在理解人类意图、遵循用户指令以及增强推理能力方面。尽管已有一些综述工作对基于RL增强的LLM进行了梳理,但它们的研究范围通常有限,未能系统总结RL在LLM全生命周期中的作用。本文系统回顾了RL赋能LLM的理论与实践进展,尤其关注“可验证奖励的强化学习”(Reinforcement Learning with Verifiable Rewards, RLVR)。首先,我们简要介绍RL的基本理论。其次,我们详细探讨RL在LLM生命周期各阶段(包括预训练、对齐微调以及强化推理)的应用策略。特别地,我们强调,RL方法在“强化推理”阶段是推动模型推理能力逼近极限的关键动力。随后,我们整理了当前用于RL微调的现有数据集与评测基准,涵盖人工标注数据集、AI辅助的偏好数据以及程序验证类语料。接着,我们回顾了主流的开源工具与训练框架,为后续研究提供了清晰的实践参考。最后,我们分析了RL增强LLM领域面临的未来挑战与发展趋势。本文旨在向研究人员和实践者呈现RL与LLM交叉领域的最新进展与前沿趋势,以期推动更智能、更具泛化能力与更安全的LLM演进。
1 引言
诸如 ChatGPT [126] 等大语言模型(Large Language Models, LLMs)近年来迅速兴起,并在通用对话 [9]、代码生成 [105]、数学推理 [40] 等多种任务中展现出卓越性能,逐渐成为交互式人工智能系统的重要基石 [20, 21, 89, 98, 205, 206]。尽管 LLM 拥有广泛的泛化能力,但当前模型仍存在关键缺陷:它们往往难以可靠地捕捉细微的人类意图,并可能生成具有误导性或不安全的输出 [11, 14, 43, 81, 158, 185]。此外,若干最新研究 [65, 123, 151] 指出,LLM 的推理能力依然存在显著不足。因此,如何有效地将 LLM 的生成能力与人类偏好、价值观及具体任务需求对齐,并提升其解决复杂问题的推理能力,已成为当前 LLM 研究的重大挑战之一。
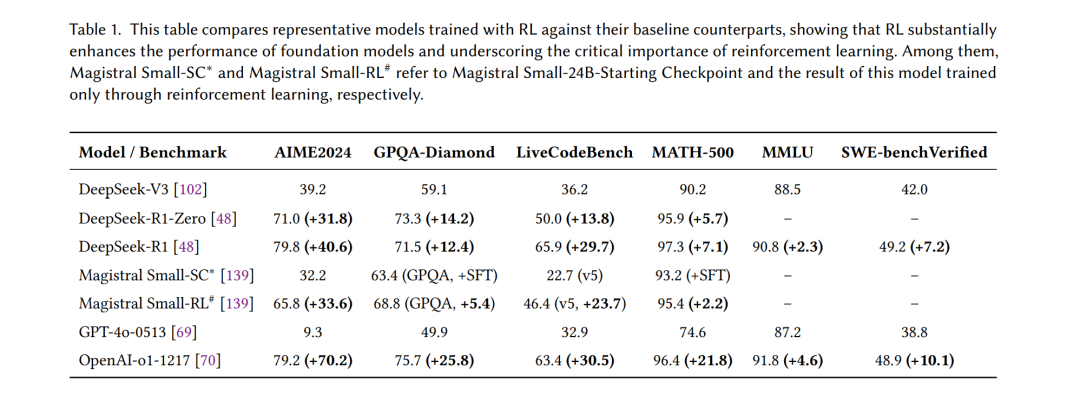
为应对这一挑战,强化学习(Reinforcement Learning, RL)被引入作为一种强有力的框架,通过交互式反馈与奖励信号直接优化模型行为。表1展示了典型模型在应用 RL 训练后,相较基线模型的性能提升情况。自 Ouyang 等人 [129] 首次提出“人类反馈强化学习”(Reinforcement Learning from Human Feedback, RLHF)以来,基于 RL 的微调已经成为提升 LLM 与人类指令和偏好对齐的核心方法。通过利用人类评估反馈或学习到的奖励模型,RLHF 使模型能够迭代地调整输出,使其更加符合人类偏好与需求,超越了单纯监督训练的效果。
在 RLHF 在对齐任务中取得成功的基础上,研究者们近来也开始探索利用 RL 范式增强推理能力。值得注意的是,自 2024 年起,一系列先进 LLM 借助推理时(test-time)或后训练(post-training)的 RL 技术,在复杂推理任务(如数学与编程)上表现出显著提升。典型代表包括 OpenAI 的 o1 系统 [70]、Anthropic 的 Claude 3.7/4 [3]、DeepSeek R1 [48]、Kimi K1.5 [160] 以及 Qwen 3 [204] 等,它们均在推理阶段融合了强化驱动的推理策略。这些成功案例表明,将 RL 应用于推理或后训练阶段,能够解锁超越预训练知识的新型问题求解能力。
支撑这些最新进展的核心创新是“可验证奖励的强化学习”(Reinforcement Learning with Verifiable Rewards, RLVR)[48, 87, 204]。该范式在标准 RL 循环中引入了可客观验证的自动化奖励信号,例如程序化检查或对模型输出的正确性证明。通过奖励那些能够通过严格正确性测试的输出(如代码的单元测试或数学定理验证),RLVR 直接激励模型生成可靠正确、逻辑严谨的解答。这一方法已成为推动推理能力提升的关键动力,使模型能够持续推理多步问题,直到得到可验证的正确结果。
然而,将 RL 整合进 LLM 的训练与应用过程中,仍存在若干开放性问题与局限性。首先,学界仍在争论 RLVR 是否真正拓展了 LLM 的推理能力,而不仅仅是放大了其预训练中已学到的知识 [190, 218, 235]。其次,对于不同的 RL 技术在 LLM 生命周期各阶段(从预训练、指令对齐到推理优化)的最佳应用方式,目前尚无明确共识。第三,RL 在数据构建与优化策略上仍面临实际挑战,例如如何基于人工偏好标签、AI 助手偏好或程序化奖励构建高质量奖励数据集,以及如何在策略梯度与奖励模型优化等 RL 算法之间做出合理选择,都是复杂的设计难题。最后,如何在大规模场景下高效且稳定地实施 RL 微调,而不破坏模型已有性能,依然是未解问题。
鉴于这些不足,本文旨在系统、全面地回顾 RL 增强 LLM 的最新进展,尤其聚焦自 2025 年以来快速发展的 RLVR 范式。我们希望澄清 RL 方法在整个 LLM 训练流程中的作用,以及其在推动模型对齐与推理前沿中的贡献。具体而言,本文将从以下几个维度展开深入分析与讨论:(1)RL 应用于 LLM 的理论基础;(2)RL 在不同训练阶段(初始预训练、对齐微调、推理时强化)的应用策略;(3)用于训练与评估 RL 微调 LLM 的数据集与基准;(4)支持大规模 RL 训练的最新工具与框架。通过这些维度的组织,我们期望为研究者和实践者提供清晰的领域全景,深入剖析 RL 技术(尤其是 RLVR)的成效与局限,并为未来如何利用 RL 使 LLM 更加对齐、强大与可靠提供参考路径。
1.1 相关综述
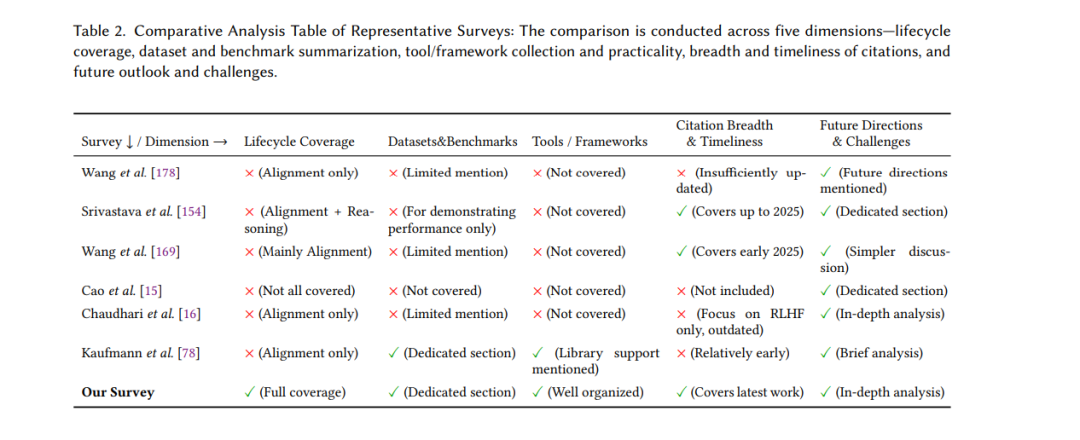
近年来,大量综述工作 [8, 12, 15, 16, 51, 72, 75, 78, 80, 85, 134, 154, 169, 178, 197, 224, 239, 240, 244] 对与大语言模型相关的强化学习研究进行了回顾,并提出了不同的分类方案。然而,这些综述的研究范围往往有限。例如,一些研究 [78, 178, 239] 仅聚焦于基于 RL 的对齐技术,其分类体系主要围绕奖励模型的使用展开,而忽略了若干重要的新兴方法。尽管在 2025 年已有若干工作尝试总结推理时 RL 的研究进展 [8, 12, 80, 197, 240],但这些回顾大多不够全面,未能系统审视推理阶段强化学习的多重维度。Pternea 等人 [134] 探讨了 RL 与 LLM 的协同效应,但其分析主要局限于双向 RL–LLM 协作的视角。Zhu 等人 [244] 则专注于“简洁与自适应思维”这一狭窄领域。虽然这些综述框架各有价值,但它们往往受限于特定视角,缺乏对 RL–LLM 交互进行统一的、端到端生命周期视角的系统分析。相比之下,本文系统性地考察了 RL 在整个 LLM 训练流水线中的作用(涵盖预训练、对齐微调与推理),并提出了一个据我们所知尚未在既有研究中得到全面覆盖的组织框架。表2总结了本文与其他代表性综述相比的优劣势。
1.2 贡献总结
本文对 LLM 的 RL 技术进行了结构化综述,主要贡献体现在以下三方面: * 生命周期组织:我们系统覆盖了 LLM 生命周期中的全流程 RL,详细阐述了各阶段(预训练、对齐、推理强化)的目标、方法与面临的挑战。这一组织方式有助于厘清 RL 技术在 LLM 开发生命周期中的应用与优化路径。 * 聚焦先进的 RLVR 技术:本文重点分析 RLVR 的最新方法。我们深入探讨了 RLVR 的实验现象与前沿应用,研究了如何确保奖励的客观与可验证性,并讨论了可验证奖励对模型性能与对齐的促进作用,同时展示了 RLVR 在真实应用中的优势与局限。 * 资源整合:我们总结了 RL 研究中关键的数据集、评测基准与开源框架,为 LLM 中 RL 的实验、评估与实践提供参考。通过整合这些资源,我们为未来研究者提供了有价值的资料,提升 RL 驱动 LLM 研究的可复现性与透明度。
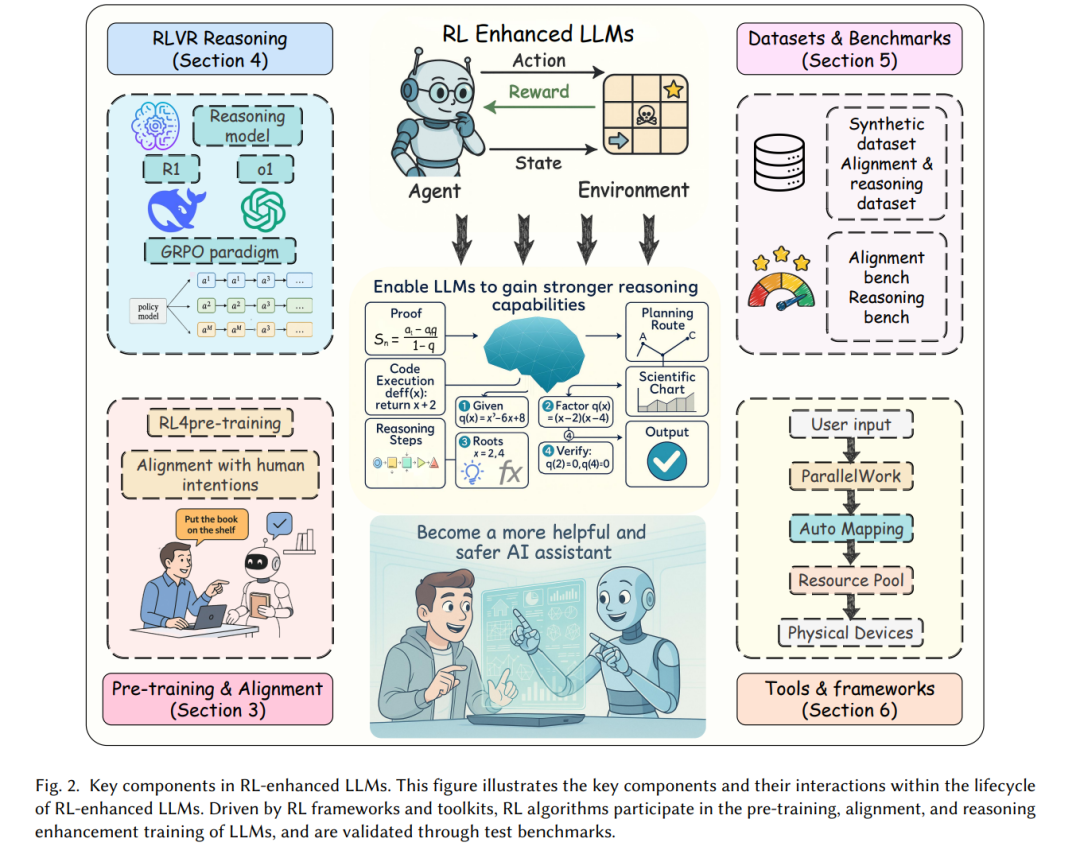
为提供组织化的路线图,图1给出了一个综合性分类法,将现有方法划分为五个分支:预训练、对齐、RLVR、数据集与基准、开源框架。如图2所示,本文围绕 LLM 的完整 RL 生命周期进行综述,特别强调可验证奖励的强化学习。总的来说,本文以生命周期为主线综合现有方法,突出 RLVR,并结合研究与应用的实践资源,形成一个系统性全景综述。