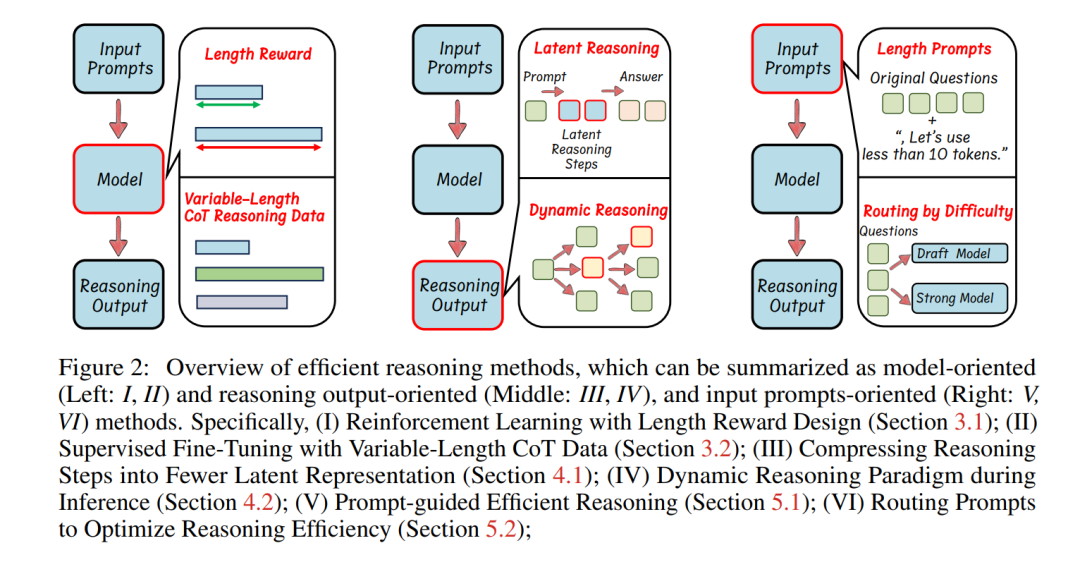
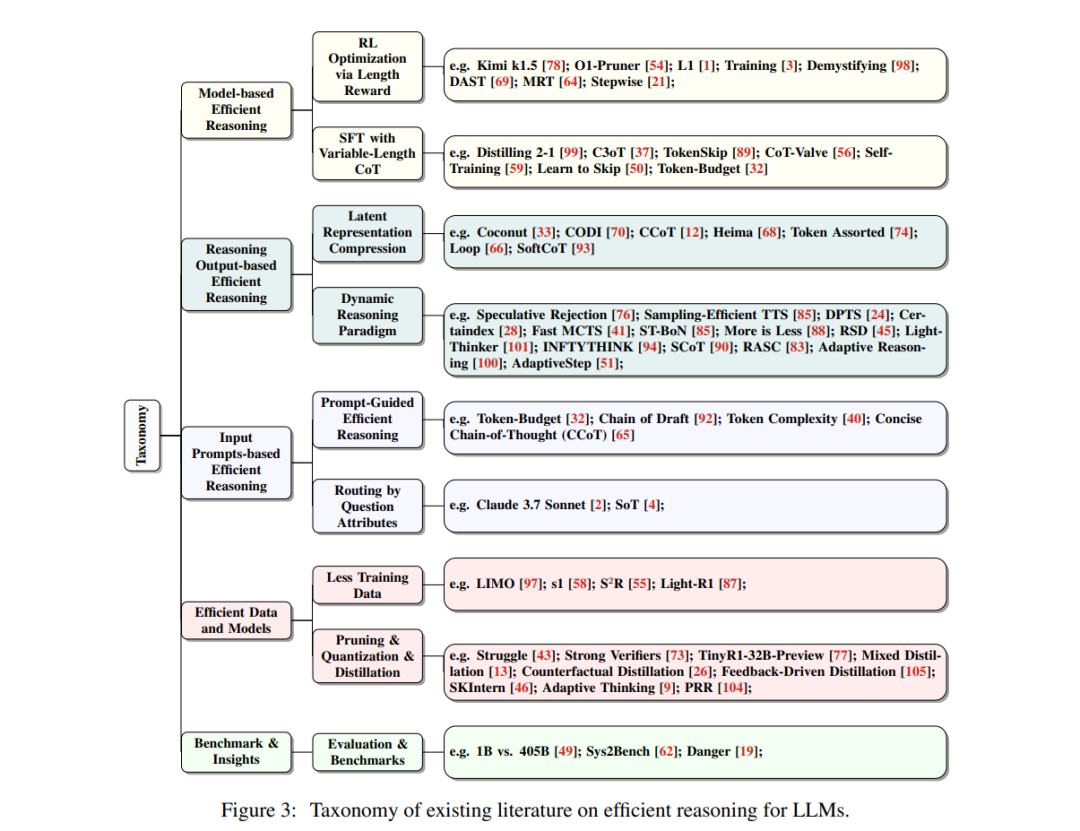
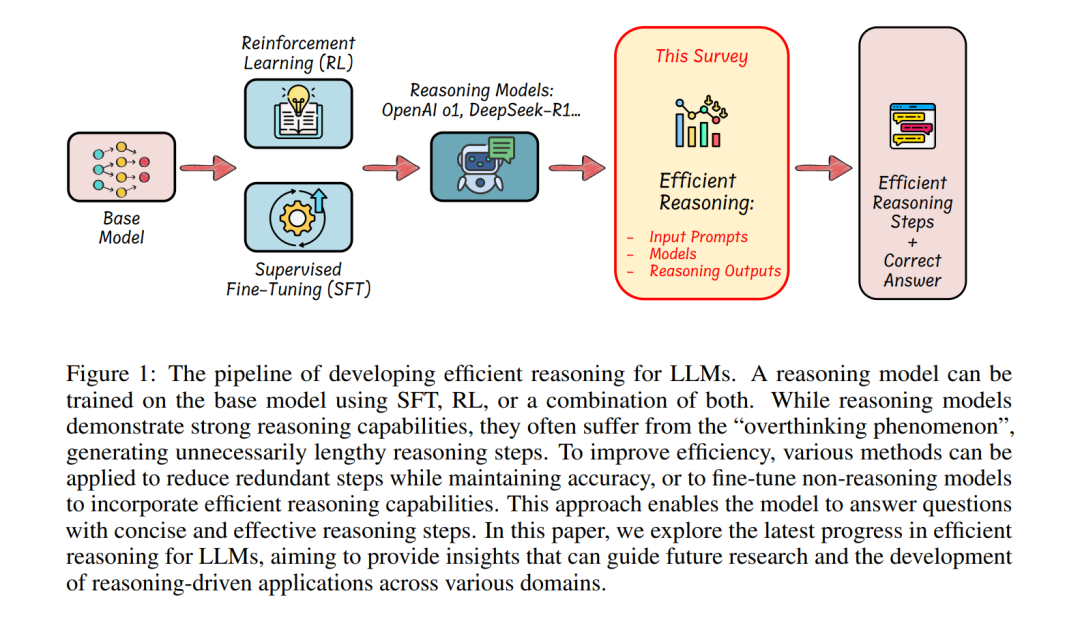
大型语言模型(LLMs)在复杂任务中展现了卓越的能力。近年来,大型推理模型(LRMs)的进展,例如OpenAI的o1和DeepSeek的R1,通过利用监督微调(SFT)和强化学习(RL)技术来增强链式思维(CoT)推理,进一步提升了在数学和编程等系统-2推理领域的性能。然而,尽管更长的CoT推理序列能够提高性能,但它们也因冗长和冗余的输出而引入了显著的计算开销,这种现象被称为“过度思考现象”。高效推理旨在优化推理长度,同时保留推理能力,从而带来降低计算成本和提高实际应用响应速度等实际益处。尽管其潜力巨大,高效推理仍处于研究的早期阶段。在本文中,我们首次提供了结构化综述,系统性地研究和探索了当前在LLMs中实现高效推理的进展。总体而言,基于LLMs的内在机制,我们将现有研究分为几个关键方向:(1)基于模型的高效推理,即考虑将完整推理模型优化为更简洁的推理模型,或直接训练高效推理模型;(2)基于推理输出的高效推理,旨在推理过程中动态减少推理步骤和长度;(3)基于输入提示的高效推理,通过输入提示的属性(如难度或长度控制)来提高推理效率。此外,我们还介绍了使用高效数据训练推理模型的方法,探索了小型语言模型的推理能力,并讨论了评估方法和基准测试。我们维护了一个公共资源库,以持续跟踪和更新这一前景广阔领域的最新研究进展。
1 引言
大型语言模型(LLMs)已成为异常强大的人工智能工具,在自然语言理解和复杂推理任务中展现了卓越的能力。近年来,专注于推理的大型语言模型(也称为大型推理模型,LRMs)[91]的出现,例如OpenAI的o1 [61]和DeepSeek的R1 [31],显著提升了其在系统-2推理领域(如数学[16, 35]和编程[7, 17])的性能。这些模型从基于下一词预测训练[23]的基础预训练模型(如LLaMA [30, 80]、Qwen [95])演化而来,通过链式思维(CoT)提示[86]生成显式的、逐步的推理序列,从而在推理密集型任务中大幅提高了有效性。LLMs的推理能力通常通过监督微调(SFT)和强化学习(RL)来开发,这些方法促进了迭代和系统化的问题解决能力。具体而言,OpenAI的o1 [61]训练流程可能结合了SFT和RL,并采用了蒙特卡洛树搜索(MCTS)[71]和经过处理的奖励模型(PRM)[47]。DeepSeek-R1则首先使用SFT对长链式思维推理数据进行微调,这些数据由经过RL训练的DeepSeek-R1-Zero生成,随后通过基于规则的奖励函数进一步优化。然而,尽管长链式思维推理显著增强了推理能力和准确性,但类似CoT机制(如自洽性[84]、思维树[96]、激励性RL[31])的引入也导致了冗长的输出响应,从而带来了巨大的计算开销和思考时间。例如,当向OpenAI-o1、DeepSeek-R1和QwQ-32B-Preview提问“2加3等于多少?”[10]时,这些模型的推理序列有时可能长达数千个词元,其中许多是冗余的,并未对得出正确答案起到实质性作用。这种冗长性直接增加了推理成本和延迟,限制了推理模型在计算敏感的实际应用中的使用,包括实时自动驾驶系统、交互式助手、机器人控制和在线搜索引擎。高效推理,尤其是减少推理长度,具有显著的优势,例如降低成本并增强实际部署中的推理能力。近年来,许多研究[32, 33, 54, 56, 98]尝试开发更简洁的推理路径,使高效推理成为一个备受关注且快速发展的研究领域。在本文中,我们首次提供了结构化综述,系统性地探索了LLMs高效推理的当前进展。如图2所示,我们将现有研究分为以下关键方向:(1)基于模型的高效推理,即将完整推理模型优化为更简洁的推理模型,或直接通过微调实现高效推理;(2)基于推理输出的高效推理,即在推理过程中动态减少推理步骤和输出长度;(3)基于输入提示的高效推理,通过利用提示属性(如提示引导的长度或提示难度)提高推理效率。与LLMs中的模型压缩技术(如量化[27, 48]或kv缓存压缩[52,103])不同,这些技术侧重于压缩模型规模并实现轻量级推理,而LLMs中的高效推理则强调通过优化推理长度和减少思考步骤来实现智能且简洁的推理。总体而言,我们将高效推理方法总结为以下几类:基于长度奖励设计的强化学习(第3.1节);基于可变长度CoT数据的监督微调(第3.2节);将推理步骤压缩为更少的潜在表示(第4.1节);推理过程中的动态推理范式(第4.2节);基于提示引导的高效推理(第5.1节);通过路由提示优化推理效率(第5.2节);此外,本文还探讨了其他有趣的主题,包括:使用高效数据训练推理模型(第6.1节);小型语言模型的推理能力与模型压缩(第6.2节);高效推理模型的评估与基准测试(第7节);我们将持续更新公共资源库,以跟踪高效推理领域的最新研究进展。