

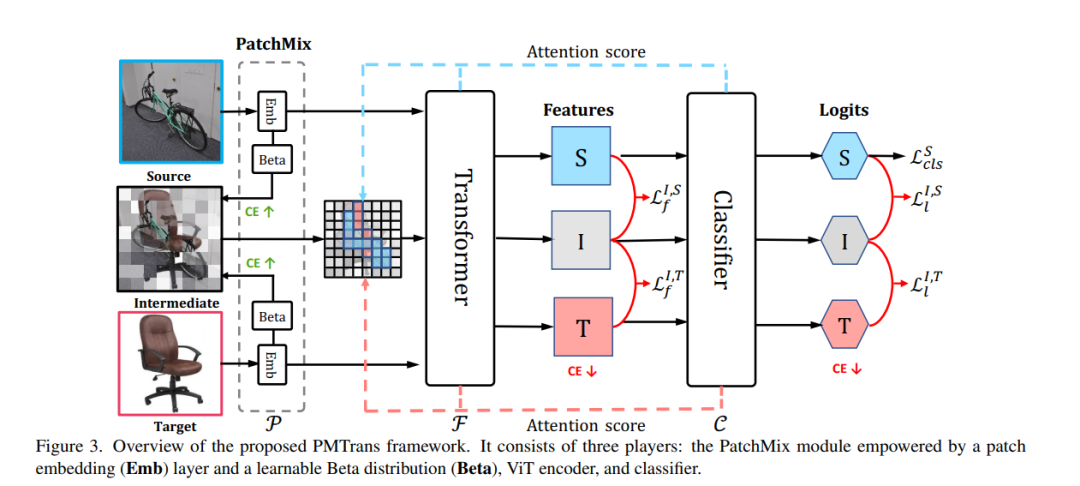
最近,人们努力利用视觉transformer (ViT)来完成具有挑战性的无监督域适应(UDA)任务。它们通常采用ViT中的交叉注意力来进行直接域对齐。然而,由于交叉注意力的性能高度依赖于目标样本的伪标签质量,当域差距较大时,交叉注意力的效果就会变差。本文从博弈论的角度解决这个问题,提出了PMTrans模型,将源域和目标域与中间域连接起来。提出了一个新的基于vit的模块PatchMix,通过学习基于博弈论模型从两个域采样补丁,有效地建立了中间域,即概率分布。通过这种方式,它学会混合来自源域和目标域的块以最大化交叉熵(CE),同时利用特征和标签空间中的两个半监督mixup损失来最小化它。将UDA的过程解释为一个有三个参与者的最小最大CE游戏,包括特征提取器、分类器和PatchMix,以找到纳什均衡。利用ViT的注意图,根据每个块的重要性重新加权每个块的标签,使其能够获得更具有领域区分性的特征表示。在四个基准数据集上进行了广泛的实验,结果表明,PMTrans在Office-Home上显著优于基于ViT和基于CNN的SoTA方法,分别在Office31和DomainNet上提高了3.6%、1.4%和17.7%。https: / / vlis2022.github.io / cvpr23 / PMTrans。
成为VIP会员查看完整内容

相关内容
相关主题



相关VIP内容
相关资讯