
原创作者:周泽焜 指导老师:冯骁骋 转载须标注出处:哈工大SCIR 本文改编自综述《From Hypothesis to Publication: A Comprehensive Survey of AI-Driven Research Support Systems》 论文链接:https://arxiv.org/abs/2503.01424
1. 引言
科学研究是一项旨在拓展人类知识、推动文明进步的系统性与创造性工作[1]。研究人员通常需要确定研究主题,回顾相关文献,综合已有知识,提出研究假设,并通过理论分析与实证方法进行验证。研究成果通常以论文形式呈现,在发表前还需接受严格的同行评审[2]。然而,这一过程不仅耗时耗力,还对研究者的专业素养与认知能力提出了极高要求,构成了科研实践中需要突破的瓶颈[3]。 近年来,以大型语言模型(Large Language Models, LLM)为代表的人工智能(AI)技术迅猛发展,在文本理解、推理与生成等方面展现出卓越能力(如 DeepSeek-R1[4])。在此背景下,越来越多的研究人员开始探索如何将 AI 技术融入科研工作流程,从文献综述、假设生成与验证,到论文撰写与审稿,人工智能正在以多种形式深度参与科研活动。如何对这些方法进行划分介绍,同时使用AI参与科研可能存在哪些问题,是目前亟待被探究的问题。 本文将首先概述 AI 参与科学研究的背景,随后以模拟人类科研行为的视角,将AI在科研领域的应用归为三个阶段:假设提出,假设验证与成果发布。随后介绍相关技术在不同科研阶段的应用进展,并进一步讨论未来的改进方向与潜在伦理问题。
2. 背景
当前科研领域正面临前所未有的信息过载危机。数据显示,arXiv 上每年的论文投稿数量持续攀升,2024 年的投稿量已接近 2007 年的 5 倍。然而,与此形成鲜明对比的是,科研人员的阅读能力并未显著提高。研究表明,科研人员每年平均只能阅读约 300 篇论文[5],这一数据在过去几十年中几乎没有变化。论文数量的激增与阅读能力的相对停滞之间的矛盾,正在显著加剧科研人员在信息获取方面的负担。
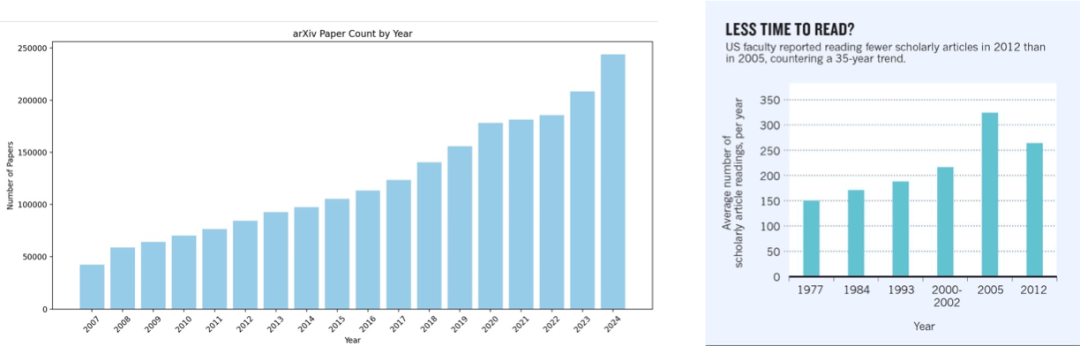
图1:arXiv 每年论文投稿数量与人类研究员平均每年阅读论文数[5] 此外,科研人员还需投入大量时间审阅最终未被接受的投稿。据估计,全球每年用于审稿却被拒的论文上所消耗的时间高达 1500 万小时[6]。这一现象不仅造成了巨大的时间浪费,也暴露出现有科研交流机制在效率上的明显瓶颈。与此同时,LLM的普及也正在显著改变科研实践。一项涵盖 816 名科研人员的问卷调查显示,约 81% 的研究者在科研流程的某一阶段中使用过 LLM[7]。在 ChatGPT 发布之后,新发表论文中可被检测出经 LLM 修改句子的比例快速上升,接近 20%[8]。在 ICLR、NeurIPS、CoRL 与 EMNLP 等顶级会议的评审意见文本中,甚至有约 6.5% 至 16.9% 的内容可能是由 LLM 生成或修改的[9]。
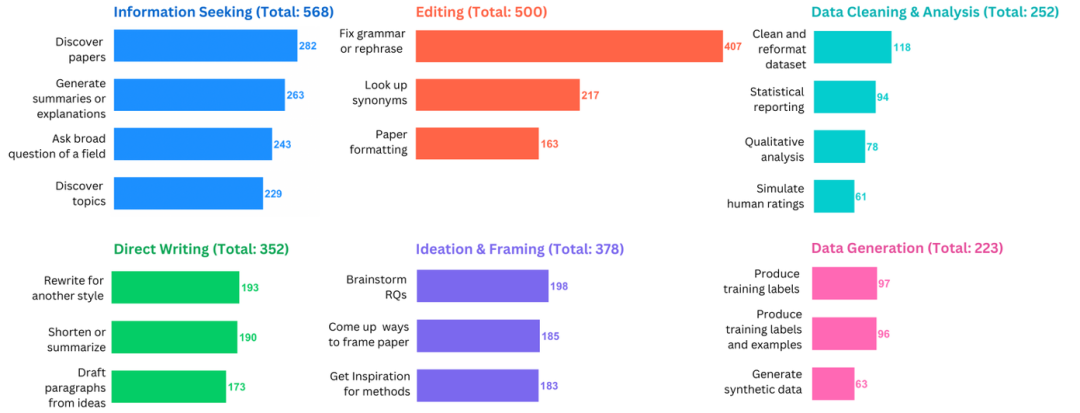
图2:816名研究人员在科研实践中使用LLM情况的调查问卷结果
3. 研究进展
随着人工智能在研究中的应用受到越来越多的关注,相关研究的数量也在不断增加,这些研究横跨多个方向,难以进行全面总结。但现有文献指出,知识整合[10],假设提出[11],假设验证[12],论文发表[13]在整个研究阶段中起到重要作用,以这些领域为骨架,本文模拟人类研究人员进行科学研究的过程,从假设生成,假设验证与论文发布三个阶段对相关研究进行介绍。
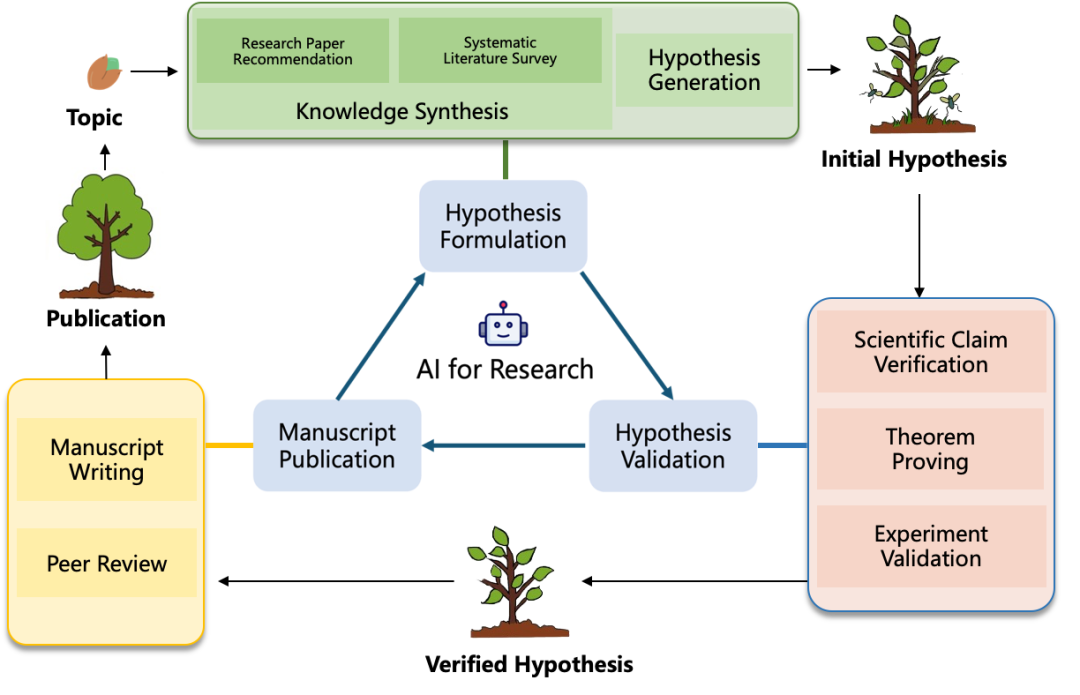
图3:AI for Research的整体流程
3.1 假设提出
这一阶段主要围绕假设形成的流程展开。它始于对领域知识的全面理解,随后确定一个特定方面并提出相关假设。本节进一步分为两个关键部分:知识整合和假设生成,对应人类研究员科研过程中背景知识的获取以及想法的提出。
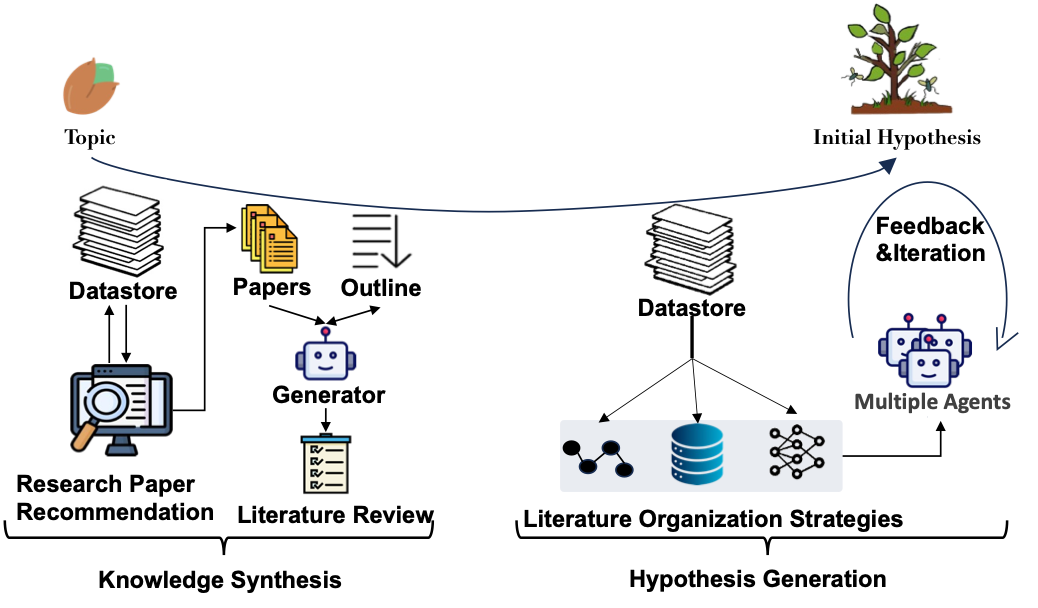
图4:假设提出的整体流程
3.1.1 知识整合
知识整合构成了研究过程的基础步骤。在此阶段,研究人员需要获取现有文献,并批判性地评估现有文献,建立对领域的深入理解。这一步骤对于发现新的研究方向、完善方法论以及得出有理有据的决策至关重要。 获取一个领域相关的文献是理解该领域的重要起点,常见的工具包括检索引擎与推荐系统。先前的研究已经表明,推荐系统在从大规模数据集中提取有价值见解时,在效率和可靠性方面优于基于关键词的搜索引擎[14]。早期的研究遵循常规的推荐系统范式,可以分为基于内容过滤、协同过滤、基于图的方法以及混合系统,这些系统多以论文为中心。而近期的研究更加强调“以用户为中心”的设计理念,如构建作者关系图[15]或利用 LLM 推理用户研究兴趣,从而实现个性化推荐。此外,在推荐内容的呈现方面,也从简单的“推荐了什么”,扩展到“为何推荐”以及“与用户已知文献的差异性”[16],提升了系统的透明度与用户体验。 获取某个领域的文献集合后还需要深入理解该领域。系统性地阅读文献并进行综述,是一种严谨且结构化的方法,旨在评估与整合特定主题的现有研究成果。与单一文档摘要不同,文献综述的核心在于对多篇相关科学文献信息进行综合。当前主流方法通常将综述过程分为两步:大纲生成与内容生成。近期研究强调,结构化大纲的生成能显著提升综述的连贯性[17]。实现结构化大纲的常用策略包括:运用聚类算法构建多级子标题,或利用 LLM 初步草拟大纲,再通过多智能体系统讨论迭代优化。此外,多层次树状结构也被证明是系统化知识表示的有效框架。内容生成紧随大纲之后,其核心任务是依据大纲指引,通过检索相关文献或整合外部知识图谱等方式获取知识,并采用迭代机制持续提升生成内容的质量。
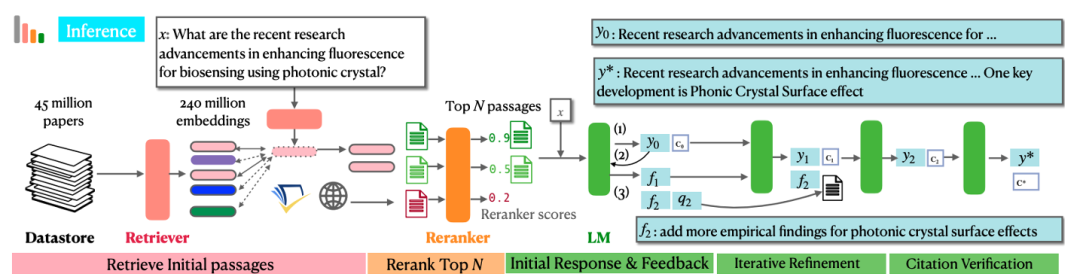
图5:OpenScholar的整体架构[18]
3.1.2 假设生成
假设生成,指的是提出新概念、解决方案或方法的过程,这是推动整个研究进展的最重要的一步。 早期研究主要聚焦于预测概念间的关系,其理论基础在于新概念常被视为源于现有概念的组合[19]。随着语言模型能力的显著提升,研究重心逐渐转向开放式的科学假设生成。以大语言模型 LLM 为核心的研究范式,通常将前置信息输入模型以驱动假设生成,已有的方法很多也将目光集中于对输入数据的优化与输出假设的优化。输入数据优化阶段的主要目标是提升生成假设所依赖信息的组织质量,例如通过构建三元组[20]、链式结构、复杂数据库和知识图谱等方式,增强语义关系建模能力。假设质量优化阶段是提升生成假设的科学性与创新性。典型策略包括引入人类或自动化反馈机制,基于实验结果或评审意见不断迭代假设[21],从而提升假设质量。
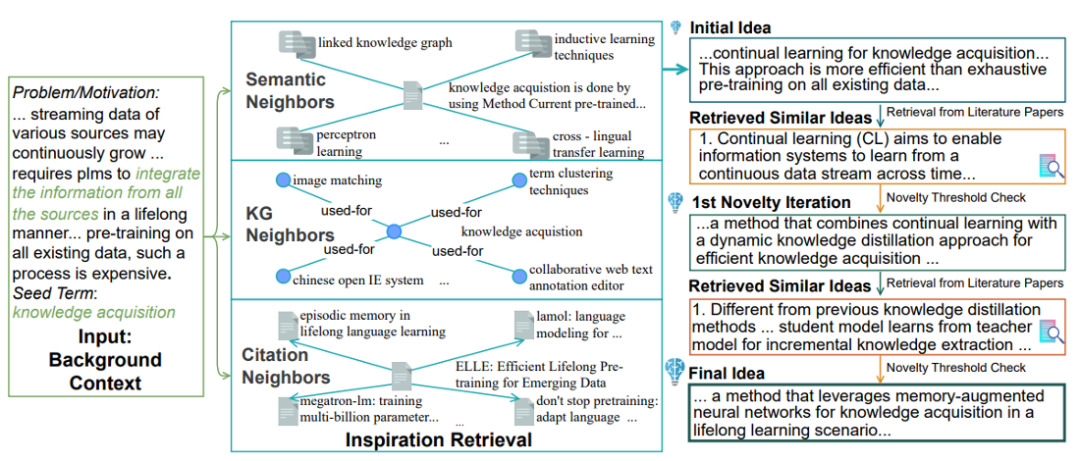
图6:SciMON的整体流程[19]
3.2 假设验证
在科学研究中,提出的假设并不总是正确,可能存在理论性错误或者实践性错误,任何提出的假设都必须经过严格的验证来确定其有效性,在某些研究中,这一过程也被称为“证伪”[22]。具体来说,科学声明验证和定理证明通过形式推理和逻辑演绎提供对假设的理论验证,而实验验证则通过实证测试提供全面的实践验证。
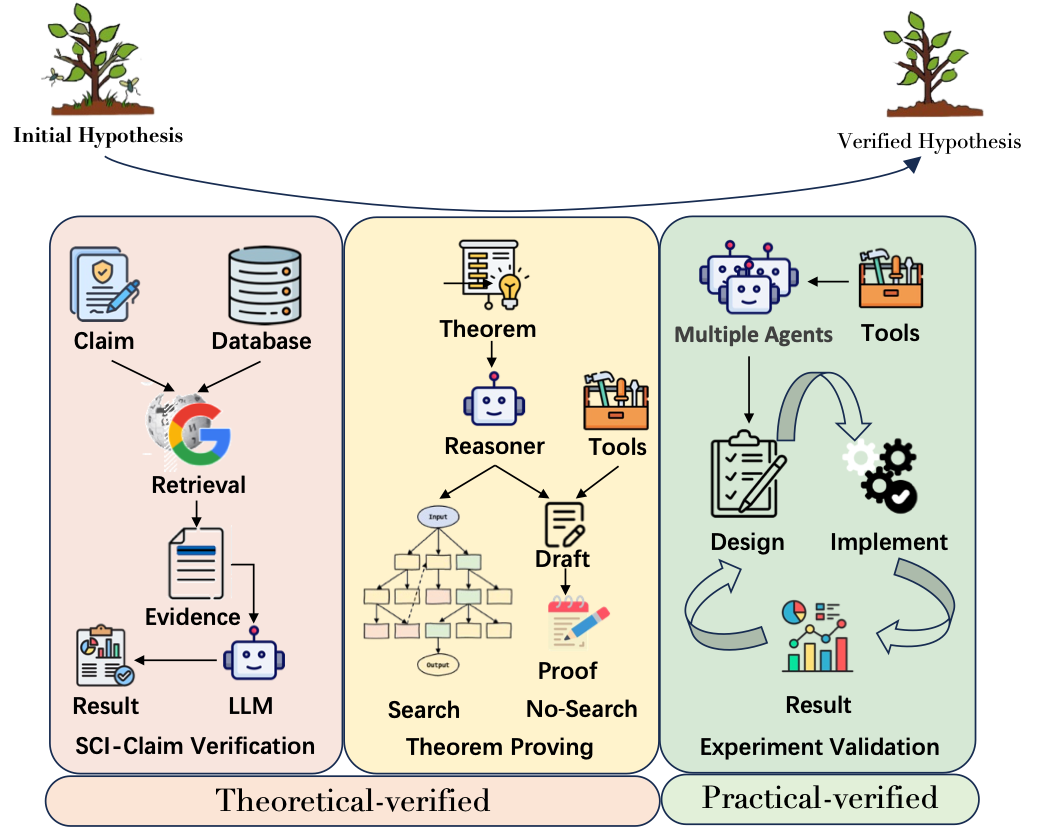
图7:假设验证的整体流程 科学声明验证的核心任务是基于可信的证据与背景知识,评估事实性科学声明的真实性。该过程主要涉及三个关键要素:科学声明本身、支撑证据以及验证方法。 * 声明处理:当缺乏支持或反驳证据时,验证用户生成内容中的科学声明会面临挑战。而特定类型的主张(如否定性主张)在证据发现上尤为困难。针对这些问题,常见策略包括:将复杂声明分解为更小的子声明,确保验证过程覆盖声明的所有关键点,或基于原始声明生成语义变体,并设计一致性约束机制进行协同验证[23]。
支撑证据获取:受限于模型固有的参数化知识容量,模型通常需要检索外部信息源。与检索增强类似,证据的来源可靠性与时效性对验证结果有显著影响。此外,证据的粒度也至关重要:使用句子级证据训练的模型往往具有更好的泛化能力,而文档级证据虽能提供更丰富的上下文、减少因孤立句子引起的歧义,但可能引入噪声[24]。
验证方法设计:获取相关证据后,需设计有效的验证方法以得出可靠结论。主流方法包括:利用知识图谱结构化组织证据,实现对声明的归因分析与解释生成,或采用模型对不同来源的证据进行融合与重建,形成新的综合证据链进行验证[25]。
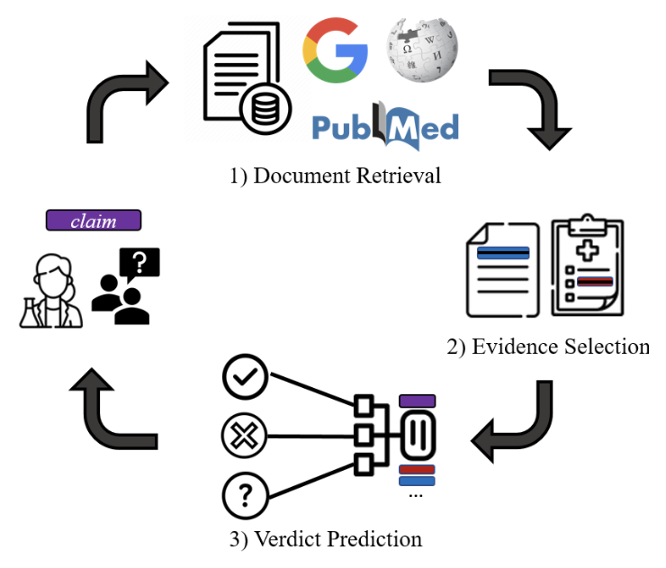
图8:科学声明验证的通用流程[26] 定理证明是逻辑推理的子任务,旨在基于给定的公理和推理规则,严格验证假设或命题在特定理论体系内的有效性。根据证明的表示方式,主要分为两类: * 非形式化定理证明:主要依赖自然语言表述,通过直观推理和解释在现有知识基础上展开证明。然而,为确保严谨性,实践中常需将非形式化证明转换为形式化证明。典型流程包括:首先基于原始定理起草非形式证明,其次将非形式证明映射为形式化证明的结构化草图,最后证明草图中的开放猜想[27]。
形式化定理证明:使用编程语言(如 Lean 4)或逻辑系统,以机器可验证的精确格式表示定理及其证明。通常会使用分层或者树搜索的方式对定理进行迭代的证明[28]。
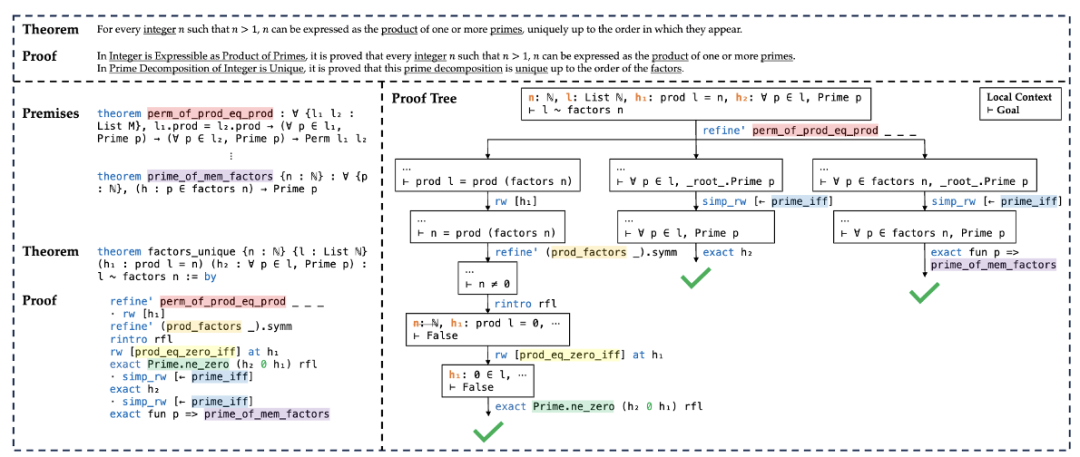
图9:常见定理证明形式[29] 实验验证是科学研究的核心环节,该环节需要依据提出的假设,设计并执行实验以检验其有效性。该过程通常耗时且资源要求高。得益于 LLM 在复杂任务规划与推理能力上的显著进步,研究者开始探索利用LLM辅助或驱动实验验证。当前研究主要聚焦于两种范式: * LLMs 辅助实验设计与执行:在化学等自然科学领域,LLMs 可作为智能代理(Agents),在给定可用工具,比如实验仪器接口、数据库等的情况下自主设计实验方案、规划执行步骤并协调实验流程[30]。
LLMs 作为模拟实验主体:在社会科学研究中,LLMs 被用于模拟人类参与者的行为和决策,构建可扩展且可控的人机交互实验环境[31]。这种范式能显著降低传统实验所需的人力与时间成本,为研究社会动态、经济行为等提供高效平台。
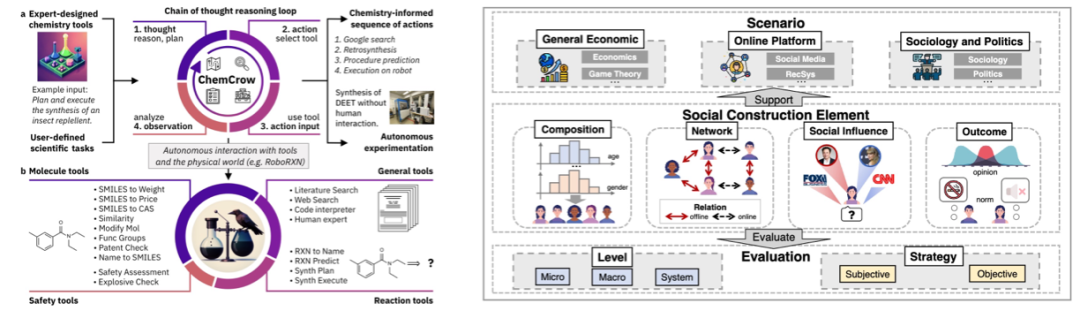
图10:两类模型参与实验验证形式[30,31]
3.3 成果发布
当一个假设成功通过了理论与实践的验证后,研究人员通常会将研究成果以论文的形式进行发表。本节针对这个过程,将论文的发表分为两个主要部分:手稿撰写和同行评审。
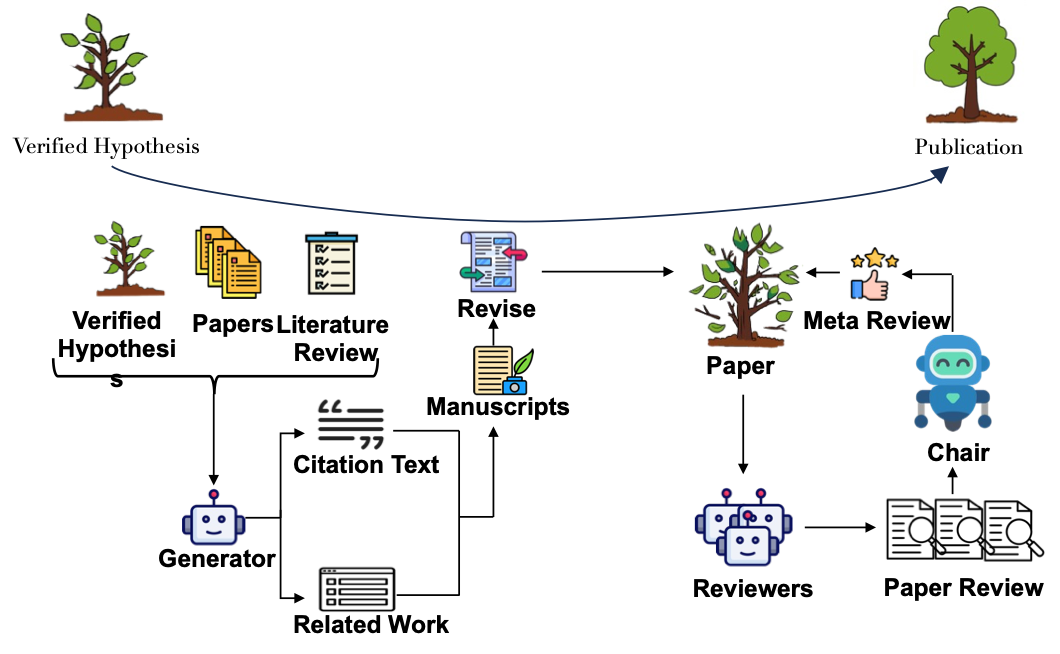
图11:成果发布的整体流程 手稿撰写阶段的任务是基于知识整合阶段的输出,包括被推荐的论文以及领域综述,以及经过验证的假设,生成结构化的论文初稿。根据生成内容的粒度,可将其分为三类: * 句子粒度:句子粒度主要聚焦于引文句的自动化生成,目标是能够在规范引入前人工作的同时,减少由于模型自主生成可能带来的事实性错误。早期方法主要是通过整合手稿内容与引文图谱构建自动化系统,但这种方法需要人为制定模版,进而导致引文表述模式化且缺乏灵活性。为克服此局限,后续研究提出将引用意图(如背景、方法对比、观点论据等)作为控制参数融入生成过程,实现对引文句特定属性的精准调控[32]。
段落粒度:段落粒度主要应用于相关工作(Related Work) 部分的撰写。与引文句生成不同,该任务更强调建模多篇被引文献间的内在关联,揭示目标手稿与现有文献网络间复杂的知识演进与互动关系[33]。
全文粒度:全文粒度涉及整合论文所有核心模块(如摘要,引言,方法,实验,结论等)以生成完整初稿。其挑战远超局部生成,需保证整体逻辑一致性与结构连贯性。主要包括引入人机协同写作以及分章节的反思与迭代机制,通过作者反馈和模型自省逐步提升稿件质量[34]。
同行评审作为科学文献出版过程中质量把控的核心机制,旨在通过专家人员的反馈,确保并提升提升学术稿件的质量,是保障研究严谨性与可信度的关键环节。现有研究主要关注两类任务: * 评审意见生成:该任务目标是模拟审稿人,提供对论文的评分和评价。现有方法依据目标反馈类型分为两种路径:
以评分为反馈:将评审视为分类(如论文质量等级:好,坏,一般)或回归(如预测具体分数)任务,直接预测论文的评审结论[35]。
以评论文本为反馈:利用 LLM 的深度语义理解能力,通过多智能体协作(模拟不同审稿角色评价论文不同部分)或多轮对话模拟(复现真实评审的迭代讨论过程),生成详尽的评审意见[36]。
元评审生成:旨在综合各审稿人意见及论文内容,形成最终决策与总结性评估。元评审生成需要克服的难题包括对不同审稿意见的识别与总结以及对审稿意见中的矛盾和偏见的识别。代表性方法通过结合LLM与结构化论证分析,将单篇评审意见建模为包含文本论据的论证单元,随后聚合多个论证单元构建多边论证框架,接着应用聚合函数量化论据强度并解析其间的支持/攻击关系,最终生成客观、全面的元评审[37]。
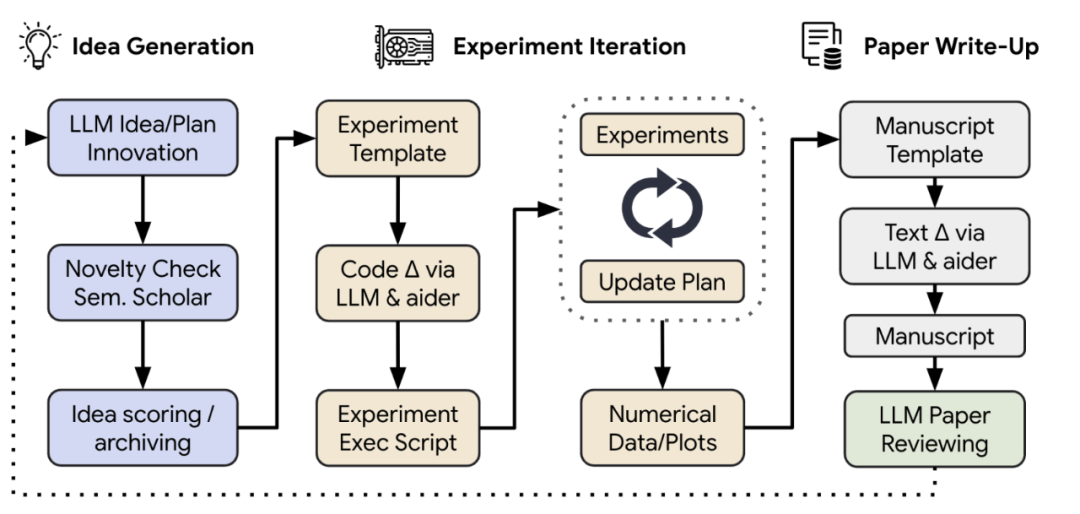
图12:AI Scientist的整体流程[34]
4. 延伸讨论
4.1 现有挑战
知识整合:基于论文元数据的论文推荐工具在提供个性化服务方面容易导致推荐结果针对性不足以及信息深度不够,影响用户的理解。而在文献综述中,现有工具(尤其是在大纲生成环节)常面临结果冗余与层次结构薄弱的问题。此外,全文生成过程中普遍存在的“幻觉”现象,例如生成内容与引用文献无法对应或者引用文献不存在。 * 假设生成:现有假设生成方法主要通过设计提示词或构建框架来实现,非常依赖预训练模型能力,而且在平衡假设的新颖性、可行性和有效性方面仍有不足。此外我们发现,当前评估指标(如新颖性、可行性等)随机性较高且缺乏统一标准,不同研究采用不同的提示词,导致结果难以直接比较。 * 假设验证:目前的科学主张验证技术多针对于特定领域,泛化能力较差,实际应用能力不好。定理证明领域面临的核心挑战包括高质量训练数据稀缺以及标准化评估基准的缺失。此外,该领域多数研究仍处于探索阶段,缺乏能够与研究者交互的实用工具。在实验验证环节,自动生成的实验方案常在方法的严谨性、实际可行性与研究目标一致性方面存在缺陷。 * 论文发表:类似于系统性文献综述,手稿撰写也受到幻觉问题的不利影响。即使采用强制引用生成方法,仍可能引入错误的参考文献。此外,由AI 生成的论文评审提供的建议往往比较模糊,并且容易受到偏见的影响。而在元评审生成过程中,模型可能会被论文审查过程中产生的错误信息误导。为了应对这些问题, 行业可能需要建立适当的法规或采用基于 AI 的方法来检测 AI 生成的文章和评论。
4.2 伦理问题
虽然 AI 在克服人类局限性、提高生产力方面展现出了巨大的潜力,但将其整合到科学研究流程中还是引发了一系列伦理问题,包括算法偏见、数据隐私问题、抄袭风险等。 在假设形成阶段,论文推荐与文献综述工具虽有益处,却存在局限,比如它们可能会强化“信息茧房”,限制研究者接触多元观点。此外,这些系统倾向于推荐知名学者的工作,加剧知名学者与新兴研究者间的差距,并潜在地助长错误信息的传播。 相比之下,AI驱动的假设生成提出了更严峻的伦理挑战。首先,对于AI生成的假设所涉及的知识产权和作者身份归属仍然存在模糊性。此外,大量低质内容的传播可能会损害学术社区的氛围,而且这些技术可能被用于非法目的。解决这些问题需要整个社区建立健全的责任框架、明确研究人员对人工智能输出内容的责任,并建立适当的法律和监管机制。 在假设验证阶段,科学事实核查的自动化系统仍然不够完备,可能会被利用来创建能够绕过现有事实核查工具的高级错误信息生成器。同样,在实验验证环节,模型存在被要求设计不合乎法律与道德要求的实验的风险。 在论文发表阶段,由人工智能模型生成的文本可能带有抄袭风险,而人工智能辅助的同行评审通常提供模糊的反馈并表现出固有偏见。为解决这些问题,开发强大的检测方法至关重要。然而目前的检测工具仍处于发展的早期阶段。
4.3 关于统一框架和特定领域框架的讨论
本文采用统一框架综述了AI加速科研流程的工作。 不可否认,不同科研领域的流程存在差异,一些学者会认为聚焦特定领域的解决方案更加的符合实际。目前既有研究致力于构建支持跨领域发现的通用框架[34],也有工作专注于应对特定学科的核心挑战[38]。虽然鉴于当前AI能力的限制,通用系统尚未能完全取代领域专用方案,然而,从长远视角看,通用系统展现出更广阔的前景,其核心潜力在于整合跨学科知识,促进科学范式的迁移与融合,从而拓展科学理解的边界。
5. 相关工具
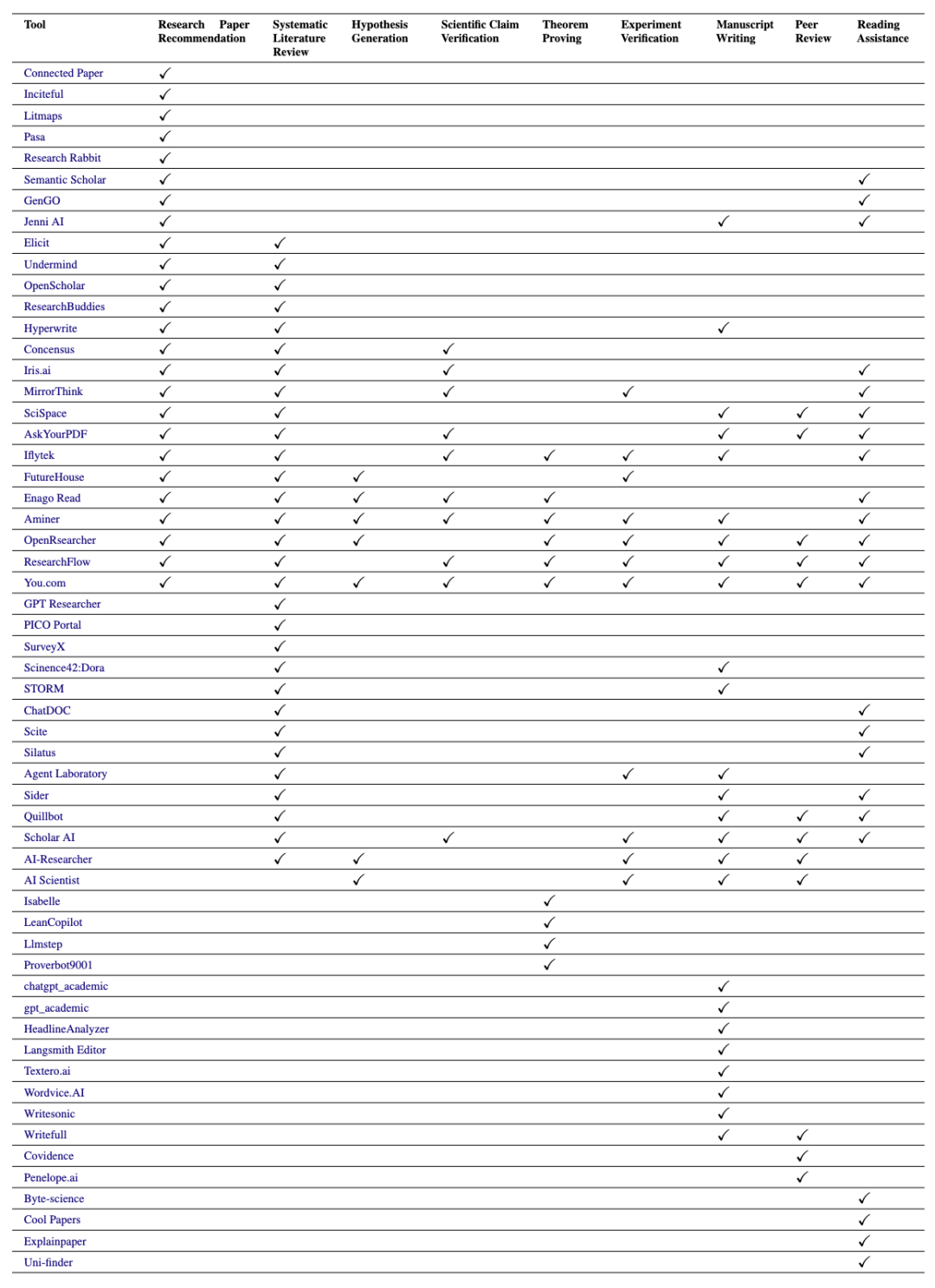
此外,我们汇总整理了现有可直接应用(开箱即用)的工具资源,并简单概括了其功能。具体工具列表及链接可以访问: https://github.com/zkzhou126/AI-for-Research
6. 参考文献
[1] Eurostat. The Measurement of Scientific, Technological and Innovation Activities Oslo Manual 2018 Guidelines for Collecting, Reporting and Using Data on Innovation[M]. OECD publishing, 2018. [2] Boyko J, Cohen J, Fox N, et al. An interdisciplinary outlook on large language models for scientific research[J]. arXiv preprint arXiv:2311.04929, 2023. [3] Blaxter L, Hughes C, Tight M. How to research[M]. McGraw-Hill Education (UK), 2010. [4] Guo D, Yang D, Zhang H, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning[J]. arXiv preprint arXiv:2501.12948, 2025. [5] Van Noorden R. Scientists may be reaching a peak in reading habits[J]. Nature, 2014: 15-17. [6] AJE Team. Peer Review: How We Found 15 Million Hours of Lost Time[EB/OL].(2019) [7] Liao Z, Antoniak M, Cheong I, et al. LLMs as Research Tools: A Large Scale Survey of Researchers' Usage and Perceptions[J]. arXiv preprint arXiv:2411.05025, 2024. [8] Liang W, Zhang Y, Wu Z, et al. Mapping the increasing use of LLMs in scientific papers[J]. arXiv preprint arXiv:2404.01268, 2024. [9] Liang W, Izzo Z, Zhang Y, et al. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews[J]. arXiv preprint arXiv:2403.07183, 2024. [10] Webster J, Watson R T. Analyzing the past to prepare for the future: Writing a literature review[J]. MIS quarterly, 2002: xiii-xxiii. [11] Swanson D R. Undiscovered public knowledge[J]. The Library Quarterly, 1986, 56(2): 103-118. [12] Popper K. The logic of scientific discovery[M]. Routledge, 2005. [13] Colyar J. Becoming writing, becoming writers[J]. Qualitative Inquiry, 2009, 15(2): 421-436. [14] Bai X, Wang M, Lee I, et al. Scientific paper recommendation: A survey[J]. Ieee Access, 2019, 7: 9324-9339. [15] Kang H B, Soliman N, Latzke M, et al. Comlittee: Literature discovery with personal elected author committees[C]//Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. 2023: 1-20. [16] Lee Y, Kang H B, Latzke M, et al. Paperweaver: Enriching topical paper alerts by contextualizing recommended papers with user-collected papers[C]//Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems. 2024: 1-19. [17] Zhu K, Feng X, Feng X, et al. Hierarchical catalogue generation for literature review: A benchmark[J]. arXiv preprint arXiv:2304.03512, 2023. [18] Asai A, He J, Shao R, et al. Openscholar: Synthesizing scientific literature with retrieval-augmented lms[J]. arXiv preprint arXiv:2411.14199, 2024. [19] Henry S, McInnes B T. Literature based discovery: models, methods, and trends[J]. Journal of biomedical informatics, 2017, 74: 20-32. [20] Wang Q, Downey D, Ji H, et al. Scimon: Scientific inspiration machines optimized for novelty[C]//Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024: 279-299. [21] Yuan J, Yan X, Feng S, et al. Dolphin: Moving Towards Closed-loop Auto-research through Thinking, Practice, and Feedback[J]. arXiv preprint arXiv:2501.03916, 2025. [22] Liu Z, Liu K, Zhu Y, et al. Aigs: Generating science from ai-powered automated falsification[J]. arXiv preprint arXiv:2411.11910, 2024. [23] Zeng F, Gao W. Prompt to be consistent is better than self-consistent? few-shot and zero-shot fact verification with pre-trained language models[J]. arXiv preprint arXiv:2306.02569, 2023. [24] Wadden D, Lo K, Wang L L, et al. MultiVerS: Improving scientific claim verification with weak supervision and full-document context[J]. arXiv preprint arXiv:2112.01640, 2021. [25] Kao W Y, Yen A Z. Magic: Multi-argument generation with self-refinement for domain generalization in automatic fact-checking[C]//Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). 2024: 10891-10902. [26] Vladika J, Matthes F. Scientific fact-checking: A survey of resources and approaches[J]. arXiv preprint arXiv:2305.16859, 2023. [27] Jiang A Q, Welleck S, Zhou J P, et al. Draft, sketch, and prove: Guiding formal theorem provers with informal proofs[J]. arXiv preprint arXiv:2210.12283, 2022. [28] Lample G, Lacroix T, Lachaux M A, et al. Hypertree proof search for neural theorem proving[J]. Advances in neural information processing systems, 2022, 35: 26337-26349. [29] Li Z, Sun J, Murphy L, et al. A survey on deep learning for theorem proving[J]. arXiv preprint arXiv:2404.09939, 2024. [30] M. Bran A, Cox S, Schilter O, et al. Augmenting large language models with chemistry tools[J]. Nature Machine Intelligence, 2024, 6(5): 525-535. [31] Mou X, Ding X, He Q, et al. From individual to society: A survey on social simulation driven by large language model-based agents[J]. arXiv preprint arXiv:2412.03563, 2024. [32] Gu N, Hahnloser R H R. Controllable citation sentence generation with language models[J]. arXiv preprint arXiv:2211.07066, 2022. [33] Yu L, Zhang Q, Shi C, et al. Reinforced Subject-Aware Graph Neural Network for Related Work Generation[C]//International Conference on Knowledge Science, Engineering and Management. Singapore: Springer Nature Singapore, 2024: 201-213. [34] Lu C, Lu C, Lange R T, et al. The ai scientist: Towards fully automated open-ended scientific discovery[J]. arXiv preprint arXiv:2408.06292, 2024. [35] D'Arcy M, Hope T, Birnbaum L, et al. Marg: Multi-agent review generation for scientific papers[J]. arXiv preprint arXiv:2401.04259, 2024. [36] Tan C, Lyu D, Li S, et al. Peer review as a multi-turn and long-context dialogue with role-based interactions[J]. arXiv preprint arXiv:2406.05688, 2024. [37] Sukpanichnant P, Rapberger A, Toni F. Peerarg: Argumentative peer review with llms[J]. arXiv preprint arXiv:2409.16813, 2024. [38] Irons J, Cooper P, McGrath M, et al. AI for scientists: Using cognitive task analysis to guide scientific AI[J]. 2024.