

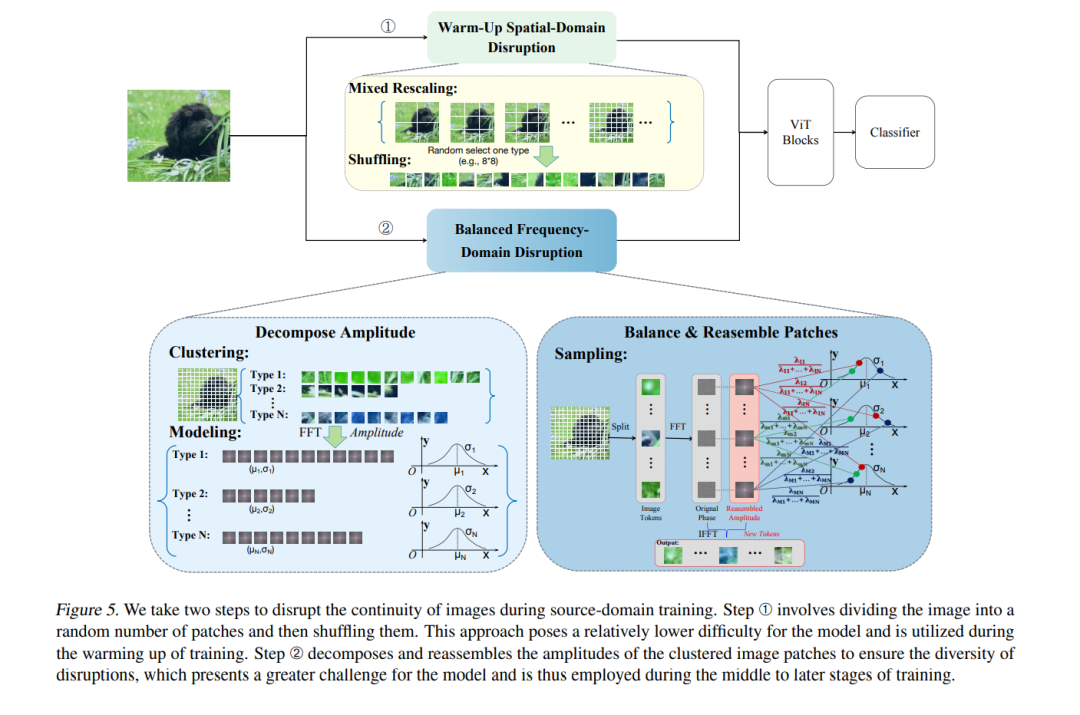
视觉变换器(ViT)由于在通用领域的大规模预训练,已经取得了显著的成功,但在应用于仅有稀缺训练数据的下游远程领域时,仍然面临挑战,这就产生了跨领域少样本学习(CDFSL)任务。受到自注意力对标记顺序不敏感的启发,我们发现了当前研究中被忽视的一个有趣现象:在ViT中破坏图像标记的连续性(即,使像素在各个块之间不平滑过渡)会导致在通用(源)领域的性能显著下降,但在下游目标领域的性能仅有轻微下降。这质疑了图像标记连续性在ViT在大领域差异下的泛化能力中的作用。本文深入探讨这一现象,并给出了解释。我们发现,连续性有助于ViT学习较大的空间模式,而这些模式比小的模式更难以迁移,从而增加了领域间的距离。同时,这也意味着在极端领域差异下,仅有每个块内的小模式可以被迁移。基于这一解释,我们进一步提出了一种简单而有效的CDFSL方法,能够更好地破坏图像标记的连续性,鼓励模型减少对大模式的依赖,更多地依赖于小模式。大量实验表明,我们的方法在缩小领域差距和超越现有最先进方法方面是有效的。代码和模型可通过以下链接获取:https://github.com/shuaiyi308/ReCIT。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
152+阅读 · 2023年3月29日