

时间序列推理将时间视为一等公民维度,并将中间证据直接融入答案之中。本综述对该问题进行了定义,并按照推理拓扑结构对现有文献进行了组织,分为三类:一步到位的直接推理、带有显式中间步骤的线性链式推理,以及包含探索、修正与聚合的分支结构推理。我们将这些拓扑结构与该领域的主要目标交叉对应,包括传统的时间序列分析、解释与理解、因果推断与决策、以及时间序列生成。同时,我们提出了一套紧凑的标签体系来覆盖这些维度,并捕捉分解与验证、集成、工具使用、知识访问、多模态、智能体循环以及大语言模型对齐机制等要素。
方法与系统在跨领域的回顾中展示了不同拓扑所能实现的能力及其在真实性(faithfulness)或鲁棒性方面的局限性,同时提供了经策划的数据集、基准和相关资源来支持研究与部署(配套仓库见 https://github.com/blacksnail789521/Time-Series-Reasoning-Survey)。我们强调了保持证据可见且时间对齐的评估实践,并提炼出关于如何将推理拓扑与不确定性相匹配、如何通过可观测的工件实现扎根、如何规划应对分布漂移与流式数据,以及如何将成本与延迟作为设计预算的指导原则。 我们特别强调,推理结构必须在扎根与自我纠错的能力与计算成本和可复现性之间取得平衡;而未来的进展可能取决于能够将推理质量与效用挂钩的基准,以及能够在感知分布变化、流式与长时间跨度设定下权衡成本与风险的闭环测试平台。综合来看,这些方向标志着研究正从狭义的准确性转向大规模的可靠性,推动系统不仅能分析,还能以可追溯的证据和可信的结果来理解、解释并作用于动态世界。
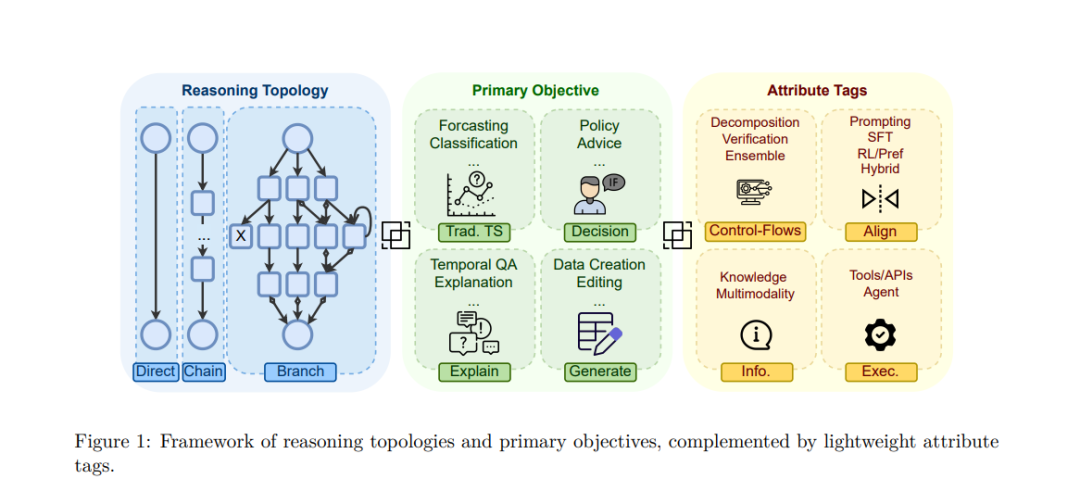
时间序列数据在日常生活中极为常见,它们记录了变量随时间的演化与交互,涉及金融、医疗、能源、气候、交通和制造流程等领域 (Chang et al., 2025c; Ou et al., 2024; Chang et al., 2025b; 2024c; Zhao et al., 2020; Cao et al., 2024b; Niu et al., 2024; Cao et al., 2022; Li et al., 2025c)。经过数十年的发展,时间序列分析已经成为监测、预测、诊断与决策的核心方法之一,并广泛应用于风险建模、患者监护、需求预测以及预测性维护等领域 (Chang et al., 2024a; Lin et al., 2024; Chang et al., 2024b; Lo et al., 2024; Cao et al., 2020)。现有的时间序列综述大多聚焦于建模与算法方法,包括深度学习预测方法 (Lim & Zohren, 2021; Torres et al., 2021; Mahalakshmi et al., 2016; Liu et al., 2021; Benidis et al., 2022)、基于 Transformer 的架构 (Wen et al., 2023)、异常检测 (Zamanzadeh Darban et al., 2024)、分类 (Ismail Fawaz et al., 2019)、聚类 (Liao, 2005)、模式发现 (Torkamani & Lohweg, 2017)、变点检测 (Aminikhanghahi & Cook, 2017)、序列分段 (Keogh et al., 2004)、压缩 (Chiarot & Silvestri, 2023) 以及数据增强 (Victor & Ali, 2024; Wen et al., 2021)。这些工作主要关注如何在处理序列化时间数据时提升预测精度、表示能力与效率。 然而,许多新兴应用的需求远超预测本身。诸如个性化医疗、自适应风险管理以及自主系统等领域,需要模型不仅能够解释输出、进行反事实推理,还要能在多种备选行动方案中作出决策。这些需求凸显了一个事实:推进时间序列分析的发展,必须依赖结构化且可靠的推理。尽管应用广泛,现有文献几乎未涉及时间序列中的推理、解释或基于智能体的决策。就我们所知,目前尚无工作系统性地探讨如何在时间序列方法中实现高层次推理或面向政策的行动。 大语言模型(LLMs)的兴起为该领域带来了另一个关键转折点。LLMs 不仅能够进行模式拟合,还能够展现逐步推理过程 (Ke et al., 2025; Zhang et al., 2024b; Huang & Chang, 2023; Chu et al., 2024; Zhang et al., 2025e; Yang & Thomason, 2025; Xiao et al., 2024),提出因果假设 (Li et al., 2025d; Liu et al., 2025f; Kiciman et al., 2023; Zhang et al., 2022; Cao et al., 2023),并与外部工具和环境交互 (Shen, 2024; Ferrag et al., 2025; Yang et al., 2025a; Chen et al., 2025b)。当 LLM 被纳入智能体系统后,它们获得了规划 (Huang et al., 2024; Wei et al., 2025)、反思 (Renze & Guven, 2024; Ji et al., 2023) 与持续适应 (Fujii et al., 2024; Shi et al., 2025) 的能力,从而将时间序列建模从静态预测转变为交互式与可解释的过程 (Ye et al., 2024)。这一转变拓展了下游任务的空间:模型不仅要做预测或异常检测,还需要支持因果分析、自然语言推理、时间信号的模拟与编辑,以及政策驱动的决策。 基于这一转型,本综述以三大交叉趋势为基础,来描绘未来的发展格局。首先,时间序列数据日益普及并愈发重要,推动实际系统在不确定性下对清晰性、通用性与强决策能力提出更高要求。其次,LLM 与多模态 LLM 已展现出前所未有的推理与泛化能力,使得时间序列问题能够以自然语言与符号形式重新表述。第三,基于 LLM 的自主智能体兴起,使得模型不仅能够分析时间序列,还能通过模拟、干预或迭代决策循环直接作用于时间序列。受这些发展驱动,我们定义并研究时间序列推理(Time Series Reasoning, TSR):即大语言模型在时间索引数据上显式执行结构化推理过程的方法,该过程可结合多模态上下文与智能体系统加以丰富。本综述提出了该领域的首个系统性分类法,围绕不同的推理拓扑与主要目标展开,并辅以轻量级属性标签来捕捉控制流操作符(如分解、验证与集成)、执行者(包括工具使用与智能体循环)、模态与知识访问,以及特定于 LLM 的对齐机制,如图 1 所示。 本综述的主要贡献如下: (i) 我们首次提出了时间序列推理的系统化分类框架,沿两条互补轴展开:推理拓扑(执行结构)与主要目标(任务意图),并进一步结合轻量级属性标签,涵盖控制流操作符、执行者(工具与智能体循环)、模态与知识访问以及 LLM 对齐机制。 (ii) 我们提供了一个综合性回顾,不仅分析了研究论文中跨越推理拓扑与目标的模式,还对补充性工作进行归类,如数据集、基准、综述、教程、立场与愿景论文,凸显这些工作如何支持并塑造时间序列推理的发展。 (iii) 我们指出了若干开放问题,包括:评估与基准构建、多模态融合与对齐、检索与知识扎根、长上下文推理、记忆与效率、智能体控制与工具使用,以及因果推理与决策支持——并据此制定了未来时间序列推理的研究议程。 本文的其余部分组织如下:第 2 节形式化了时间序列推理的概念,并介绍了我们的分类体系、决策框架和系统化标注流程,用以将每篇论文注释为推理拓扑、主要目标与属性标签。第 3–5 节深入分析三类推理拓扑;第 6 节综述了数据集、基准、评估协议与辅助资源;第 7 节总结开放问题与未来研究方向。整体而言,本文确立了一个统一的分类体系,对一百余篇论文进行了可复现的标注,并综合了方法学趋势与挑战,旨在为开发新型时间序列推理系统的研究者和寻求结构化指南的实践者提供参考。 



