开放领域生成系统在会话人工智能领域(例如生成式搜索引擎)引起了广泛关注。本文对这些系统,特别是大型语言模型所采用的归因机制进行了全面回顾。尽管归因或引用可以提高事实性和可验证性,但模糊的知识库、固有偏见以及过度归因的缺点等问题可能会妨碍这些系统的有效性。本综述的目标是为研究人员提供有价值的见解,帮助改进归因方法,以增强开放领域生成系统生成的响应的可靠性和真实性。我们认为这个领域仍处于初级阶段,因此我们维护了一个仓库,以跟踪正在进行的研究,网址为
https://github.com/HITsz-TMG/awesome-llm-attributions。
自从由大型语言模型(LLMs)驱动的开放领域生成系统出现以来(Anil等人,2023;OpenAI,2022,2023),解决潜在不准确或虚构内容的连贯生成一直是一个持续存在的挑战(Rawte等人,2023;叶等人,2023;张等人,2023b)。社区通常将这种问题称为“幻觉”问题,其中生成的内容呈现出扭曲或虚构的事实,缺乏可信的信息来源(Peskoff和Stewart,2023)。这在信息搜索和知识问答场景中尤为明显,用户依赖大型语言模型获取专业知识(Malaviya等人,2023)。
幻觉问题的实质可能源于事先训练的模型是从广泛、未经过滤的现实世界文本中获取的(Penedo等人,2023)。这些人类生成的文本固有地包含不一致性和虚假信息。事先训练的目标仅仅是预测下一个单词,而不是明确建模生成内容的真实性。即使在利用人类反馈的强化学习之后(Ouyang等人,2022),模型仍然可能出现外部幻觉(Bai等人,2022)。为了解决外部幻觉的问题,研究人员已经开始采用外部参考文献等措施来增强聊天机器人的真实性和可靠性(Thoppilan等人,2022;Menick等人,2022;Nakano等人,2021)。显式归因和强化学习之间的区别不仅在于需要人工验证和遵从,还在于认识到生成的内容可能随着时间变化而变得过时或无效。归因可以利用实时信息来确保相关性和准确性。然而,归因的基本挑战围绕着两个基本要求(Liu等人,2023):
考虑到这些要求,我们可以将模型处理归因的主要方式分为三种类型:
- 直接模型驱动的归因:大型模型本身为其回答提供归因。然而,这种类型经常面临挑战,因为回答可能不仅是虚构的,而且归因本身也可能是虚构的(Agrawal等人,2023)。虽然ChatGPT在大约50.6%的时间里提供正确或部分正确的答案,但建议的参考文献仅在14%的时间内存在(Zuccon等人,2023)。
- 检索后回答:这种方法根植于明确检索信息然后让模型基于这些检索到的数据进行回答的思想。但检索并不本质上等同于归因(Gao等人,2023b)。当模型的内部知识和外部检索的信息之间的边界变得模糊时,可能会出现潜在的知识冲突问题(Xie等人,2023)。检索也可以被用作一种专门的工具,允许模型独立触发它,类似于ChatGPT 1中的“使用必应进行浏览”。
- 生成后归因:系统首先提供答案,然后使用问题和答案进行归因搜索。如果需要,答案然后会进行修改并得到适当的归因。现代搜索引擎,如Bing Chat 2,已经包含了这种归因方式。然而,研究显示,从四个生成式搜索引擎生成的内容中,只有51.5%完全得到了引用文献的支持(Liu等人,2023)。这种归因方式在高风险专业领域,如医学和法律中尤其缺乏,研究发现有大量不完整的归因(分别为35%和31%);而且,许多归因来自不可靠的来源,51%的归因被专家评估为不可靠(Malaviya等人,2023)。

超越对文本幻觉的一般讨论(Zhang等人,2023b;叶等人,2023;Rawte等人,2023),我们的研究深入探讨了大型语言模型的归因问题。我们探讨了它的起源、支撑技术以及评估标准。此外,我们也涉及了诸如偏见和过度引用的挑战。我们相信,通过关注这些归因问题,我们可以使模型更加可信赖和容易理解。我们这项研究的目标是以一种更加清晰的方式来阐述归因问题,鼓励对这一主题进行更深入的思考。
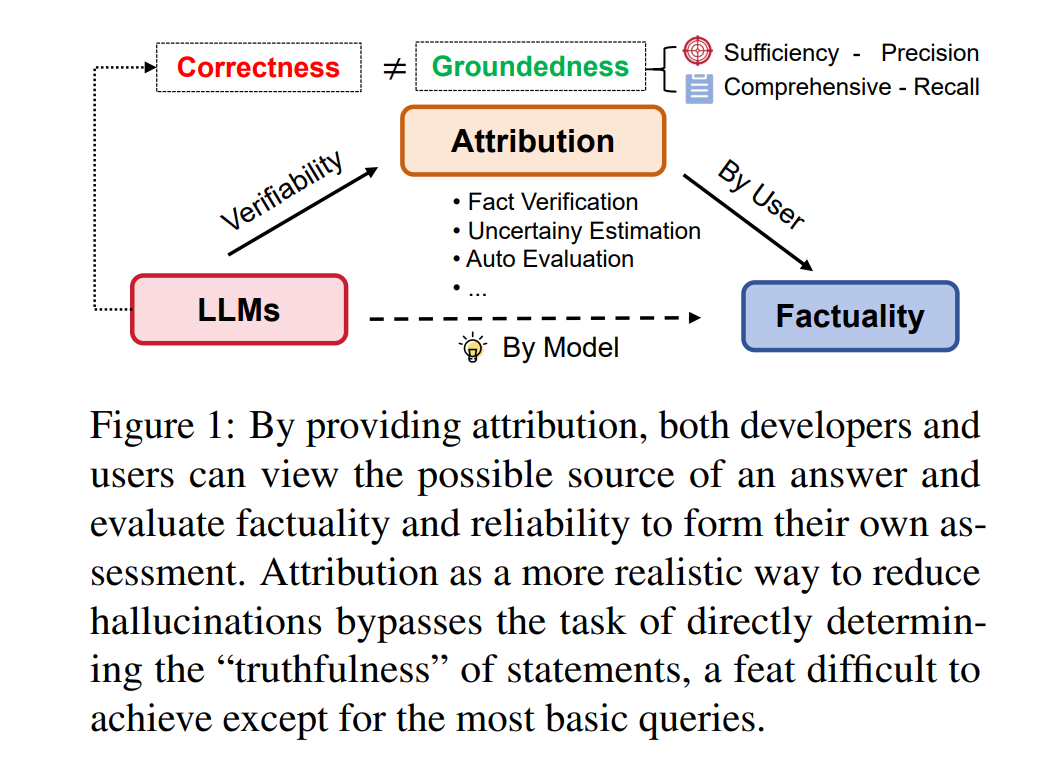
归因是指一个实体(如文本模型)生成并提供证据的能力,这些证据通常以引用或参考文献的形式出现,用以支撑它所产生的声明或陈述。这些证据来源于可识别的源头,确保这些声明可以从一个基础语料库中逻辑推断出来,使得它们对于普通受众而言是可以理解和验证的。归因本身与搜索任务相关(Brin 和 Page, 1998;Page 等人, 1999;Tay 等人, 2022),在这种任务中只有几个网页会被返回。然而,归因的主要目的包括使用户能够验证模型所做的声明,促进生成与引用源高度一致的文本以提高准确性和减少错误信息或幻觉,以及建立一个结构化的框架来评估支持证据的完整性和相关性,与所提出的声明相比较。归因的准确性核心在于所产生的陈述是否完全由引用源支持。Rashkin 等人(2021)还提出了归因于已识别来源(AIS)的评估框架,以评估特定陈述是否由所提供的证据支持。Bohnet 等人(2022)提出了归因问答,模型在这里接受一个问题,并产生一对配对的回答,即答案字符串及其从特定语料库,如段落中得到的支持证据。
直接生成的归因 来自参数化知识的直接生成归因可以帮助减少幻觉现象并提高生成文本的真实性。通过要求模型进行自我检测和自我归因,一些研究发现生成的文本更加基于事实,并且在下游任务中的表现也有所提升。最近,研究人员发现,大型语言模型在回答特定领域的知识性问题时,不能清楚地提供知识来源或证据(Peskoff 和 Stewart, 2023; Zuccon 等人, 2023)。在大多数情况下,模型只能提供一个与问题中的关键词松散相关或与当前主题无关的知识来源。即使模型正确回答了问题,它提供的证据仍然可能存在错误。Weller 等人(2023)尝试通过提出根据提示方法,将模型生成的文本基于其预训练数据,发现这种方法可以影响模型的根据性,从而影响信息寻求任务的表现。Anonymous(2023)引入了一个中间规划模块,要求模型生成一系列问题作为当前问题的蓝图。模型首先提出一个蓝图,然后结合基于蓝图问题生成的文本作为最终答案。蓝图模型允许在每个回答问题的步骤中采用不同形式的归因,可以期望更具解释性。
**检索后回答 **
多篇研究论文已经调查了归因的检索后回答方法(Chen 等人,2017年;Lee 等人,2019年;Khattab 和 Zaharia,2020年)。SmartBook 框架(Reddy 等人,2023年)提出了一种方法,该方法利用大量新闻数据自动生成结构化的情况报告。SmartBook 确定了情况分析的关键问题,并从新闻文章中检索相关信息。报告按时间线组织,每个时间线包括重大事件、战略问题和由事实证据支持的概括性总结。为了解决用户查询和存储知识之间的不一致问题,MixAlign(张等人,2023a)提出了一个框架,该框架结合了自动问题知识对齐和用户澄清,增强了检索增强生成模型的性能,并减轻了语言模型的幻觉。此外,SearChain(徐等人,2023年)引入了一个新颖的框架,它将大型语言模型(LLMs)与信息检索(IR)结合起来,提高了复杂知识密集型任务的准确性、可信度和可追溯性。SearChain 采用检索然后回答的方法,通过生成全球推理链(CoQ)并利用 IR 来验证答案和提供缺失的知识。
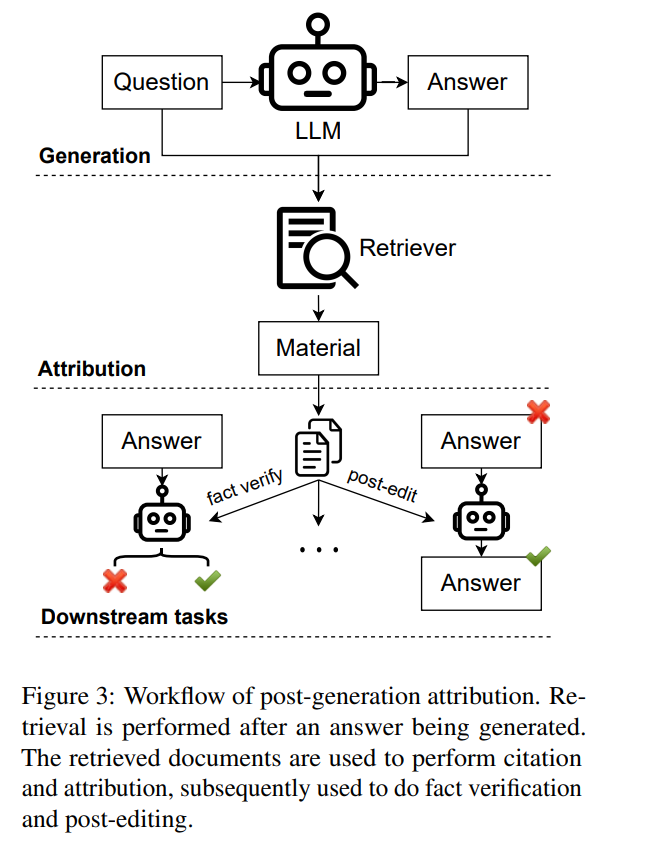
生成后归因
为了在不损害最新一代模型所提供的强大优势的情况下促进准确的归因,一些研究致力于生成后的归因,这些研究使用搜索引擎或文档检索系统,基于输入问题和生成的答案来搜索证据。这种方法允许研究人员评估或提高答案的事实性,而无需直接访问模型的参数。生成后归因的工作流程如图3所示。RARR(高等,2023a)自主识别任何文本生成模型输出的归因,并执行后期编辑以纠正不支持的内容,同时努力在最大程度上保留原始输出。在霍等人(2023)的工作中,材料是基于粗粒度的句子或细粒度的事实陈述从语料库中检索的。然后利用这些检索到的材料提示LLM,以验证生成的回应与检索到的材料之间的一致性,并进行必要的编辑以减少幻觉。陈等人(2023b)介绍了一个全自动化的管道,旨在验证复杂的政治声明,这是通过从网上检索原始证据、生成聚焦声明的摘要并利用它们进行声明验证来实现的。