CVPR2018 | 让AI识别语义空间关系:斯坦福大学李飞飞组提出「参考关系模型」
选自arXiv
作者:Ranjay Krishna 等
机器之心编译
参与:张倩、路雪
图像不仅仅是一组目标集合,同时每个图像还代表一个相互关联的关系网。在本文中,李飞飞等人提出了利用「参考关系」明确区分同类实体的任务。实验结果表明,该模型不仅在 CLEVR、VRD 和 Visual Genome 三个数据集上均优于现有方法,并且是可解释的,甚至能发现完全没见过的类别。
日常用语中的参考式表达可以帮助我们识别和定位周围的实体。例如,我们可以用「踢球的人」和「守门的人」将两个人区分开(图 1)。在这两个例子中,我们通过两人与其他实体的关系来明确他们的具体身份 [24]。其中一个人在踢球,而另一个人在守门。我们的最终目标是建立计算模型,以明确其他词汇与哪些实体相关 [ 36 ]。
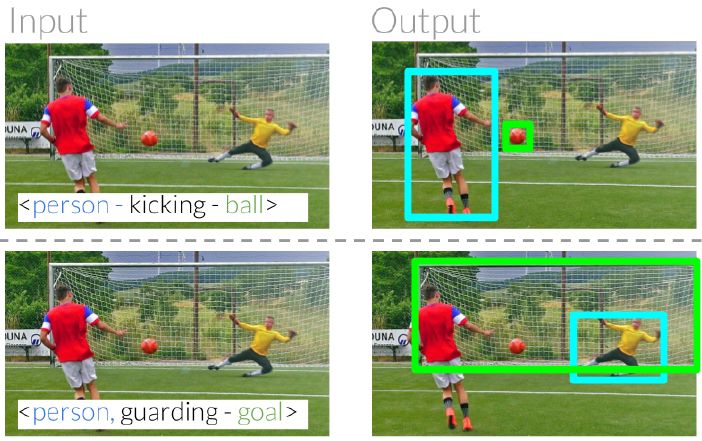
图 1:参考关系可以通过利用同一类别中的物体与其他实体之间的相对关系来明确区分这些物体。给定<person- kicking - ball>这种关系之后,我们需要模型通过理解谓词「踢」来正确识别图像中的哪个人在踢球。
为了实现这种交互,我们引入了参考关系(referring relationships),即在给定关系的情况下,模型应该清楚场景中的哪些实体在该关系中用作参考。从形式上讲,该任务需要输入带有<subject - predicate - object>关系的图像,并输出主体和客体的定位。例如,我们可以将上面的示例表示为<person -kicking - ball>和<person - guarding - goal>(图 1)。以前的研究工作已经尝试在参考式表达理解的背景下明确区分同一类别的各个实体 [ 29,25,43,44,12 ]。它们的任务需要输入自然语言,例如「a person guarding the goal」,从而产生需要自然语言和计算机视觉组件的评估。精确地指出这些模型所产生的错误是来自语言还是来自视觉模块可能有点困难。我们的任务是参考表达的一种特殊运用,通过连接结构化关系输入减少对语言建模的需要。
参考关系在前期任务的核心保留并改善算法难题。在客体定位文献中,一些实体 (如斑马和人) 差别非常明显,很容易被区分开来,而另一些客体(如玻璃和球)则较难区分 [ 30 ]。造成这些困难的原因包括某些成分尺寸小、不易区分。这种难度上的差异转化为参考关系任务。为了应对这一挑战,我们提出这样一种思路:如果我们知道另一个实体在哪里,那检测一个实体就会变得更容易。换句话说,我们可以借助踢球的人为条件来发现球,反之亦然。我们通过展开模型及通过谓词定义的运算符在主客体之间迭代传递消息来训练这种循环依赖关系。
然而,对这个谓词运算符建模并不简单,这就引出了我们的第二个挑战。传统上,以前的视觉关系论文已经能为每个谓词训练了一个基于外观的模型 [21, 24, 27]。不幸的是,谓词语义的急剧变化(取决于所涉及的实体)增加了学习谓词模型的难度。例如,谓词 carrying 的语义在以下两种关系之间可能有很大差异:<person - carrying - phone> 和 <truck - carrying -hay>。受心理学移动焦点理论 [ 19,37 ] 的启发,我们通过使用谓词作为从一个实体到另一个实体的视觉焦点转移操作来绕过这一挑战。当一个移位操作学习将焦点从主体转移到客体时,逆谓词移位以相似的方式将焦点从客体转移回主体。经过多次迭代,我们将主体和客体之间的这些不对称焦点转移实施为每个谓词 [ 39,10 ] 的不同类型的消息操作。
总而言之,我们介绍了参考关系这一任务,它的结构化关系输入使得我们可以评估识别图片中同一类别实体的能力。我们在包含视觉关系的三个视觉数据集(CLEVR [13], VRD [24] 和 Visual Genome [18])上评估我们的模型。这些数据集中的 33 %、60.3 % 和 61 % 的关系涉及不明确的实体,即相同类别中的多个实例的实体。我们扩展我们的模型以使用属于场景图的关系来执行焦点扫视 [ 38 ]。最后,我们证明了在没有主体或客体的情况下,这一新模型仍然可以明确各个实体,同时还可以辨别来自以前从未见过的新类别实体。
我们的模型使用带有 TensorFlow 后端的 Keras 进行编写。
模型地址:https://github.com/StanfordVL/ReferringRelationships。
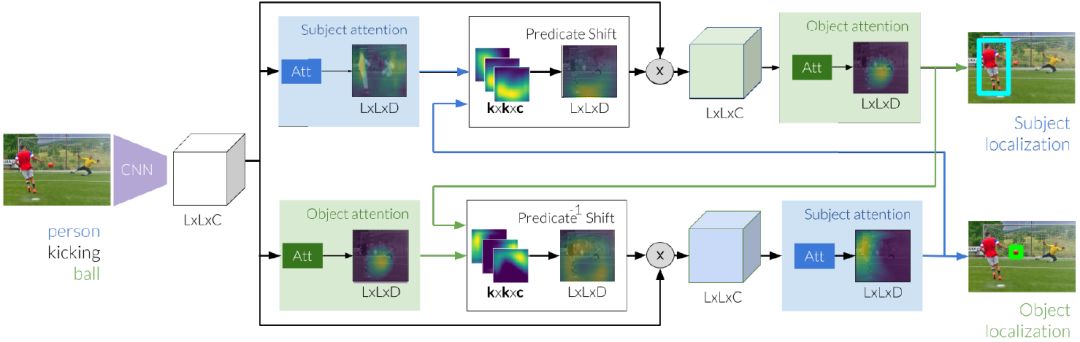
图 2:参考关系的推理过程始于图像特征提取,然后使用这些图像特征独立地生成主体和客体的初始标注。接下来,使用这些估计值将谓词的焦点从主体转移到我们期望客体的位置。在细化客体的新评估时,我们通过关注偏移区域来修改图像特征。同时,我们学习从初始客体到主体的逆向变换。我们通过两个谓词移位模块以迭代的方式在主客体之间传递消息,以最终定位这两个实体。
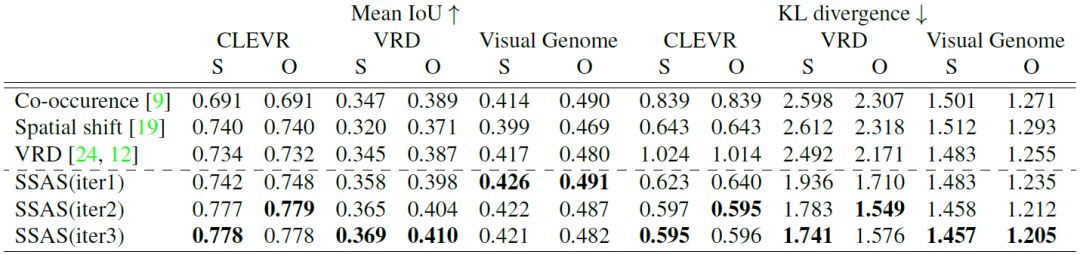
表 1:CLEVR[ 13 ]、VRD [ 24 ] 和 Visual Genome[ 18 ] 上对参考关系的测试结果。我们分别报告了主体和客体位置的 Mean IoU 和 KL 散度。
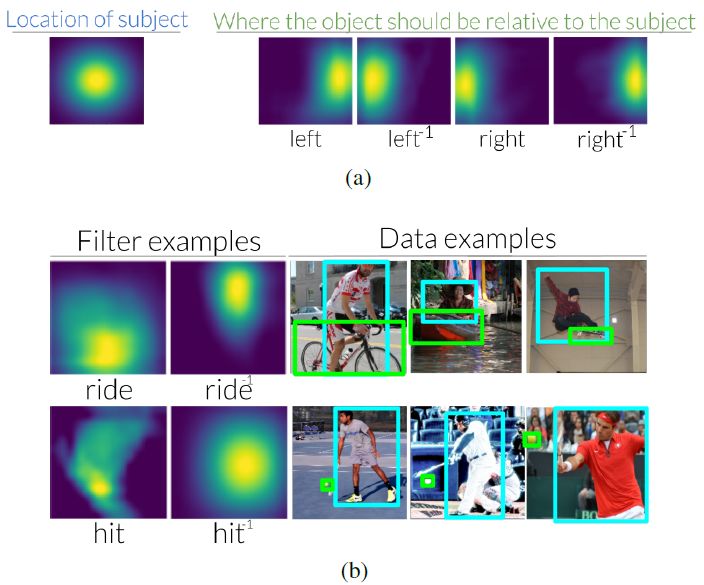
图 3:( a ) 相对于图像中间的主体,谓词 left 在使用关系查找对象时将焦点转移到右边。相反,当用客体来寻找主体时,逆谓词 left 会把焦点转移到左边。我们在附录中将所有 70 个 VRD、6 个 CLEVR 和 70 个 Visual Genome 谓词和逆谓词移位进行可视化。( b ) 我们还发现,在查看用于学习这些变化的数据集时,这些变化是直观的。例如,我们发现骑行通常对应于主体在客体的下方。

图 4:焦点如何从 CLEVR 和 Visual Genome 数据集进行多次迭代转移的可视化示例。在第一次迭代中,模型仅接收关于它试图查找的实体信息,因此试图定位这些类别的所有实例。在后面的迭代中,我们看到谓词转移了焦点,它允许我们的模型明确区分同一类别中的不同实例。
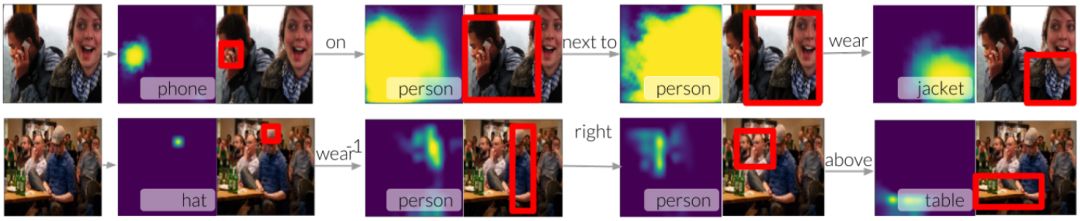
图 5:我们可以将新模型分解为焦点和移位模块,并将其堆叠起来,以覆盖场景图的节点。本图展示了如何使用我们的模型从一个节点(电话)开始根据关系遍历场景图,以连接它们并定位短语 <phone on the person next to another person wearing a jacket> 中的所有实体。第二个示例涉及 <hat worn by person to the right of another person above the table> 中的实体。
论文:Referring Relationships

论文链接:https://arxiv.org/abs/1803.10362
摘要:图像不仅仅是一组目标集合,同时每个图像还代表一个相互关联的关系网。实体之间的这些关系承载着语义功能,帮助观察者区分一个实体中的实例。例如,一张足球比赛的图片中可能不止一人,但每个人都处在不同的关系中:其中一人在踢球,另一人则在防守。在本文中,我们提出了利用这些「参考关系」明确区分同类实体的任务。我们引入了一个迭代模型,利用该模型区分参考关系中的两个实体,二者互为条件。我们通过谓词建模来描述以上关系中实体之间的循环条件,这些谓词将实体连接为从一个实体到另一个实体的焦点移位。实验结果表明,该模型不仅在 CLEVR、VRD 和 Visual Genome 三个数据集上均优于现有方法,而且能作为可解释神经网络的一个实例。此外,它还能产生可视的有意义的谓词移位。最后,我们提出,通过将谓词建模为注意转移,我们甚至可以区分模型没见过的类别中的实体,从而使我们的模型发现完全没见过的类别。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com





