CIKM 2022 | 基于文本增强和缩略-恢复策略的缩略词Transformer

©作者 | 曹恺燕
单位 | 复旦大学硕士生
来源 | 知识工场

研究背景
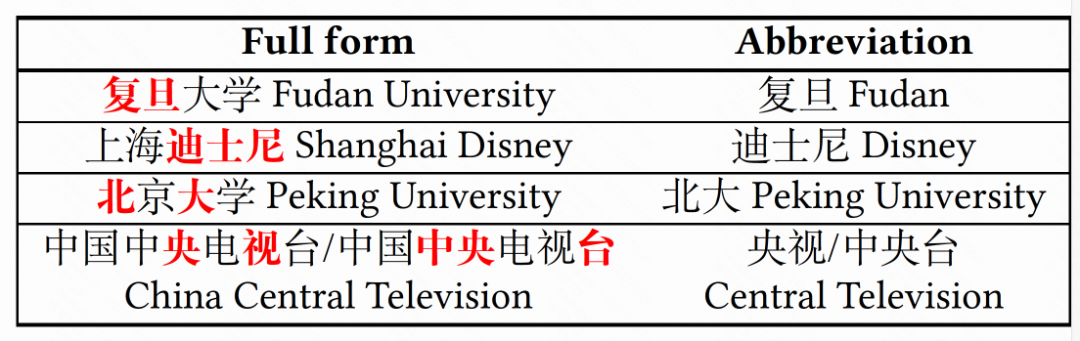
为了解决这些问题,我们将中文缩略词预测看作从全称实体序列到缩略词序列的定长机器翻译任务。贡献包括,首先,我们提出了一种用于中文缩略词预测的序列生成模型。其次,我们将实体相关上下文纳入中文缩略词预测任务,为模型提供了更多语义信息。最后,我们构建了旅游中文缩略词数据集。此外,我们在飞猪搜索系统上部署的缩略词实现了 2.03% 的转化率提升。

论文链接:
代码链接:

研究框架
模型框架:我们的模型框架由上下文增强编码器和缩略-恢复解码器组成。图 2 是 CETAR 模型架构框架图。
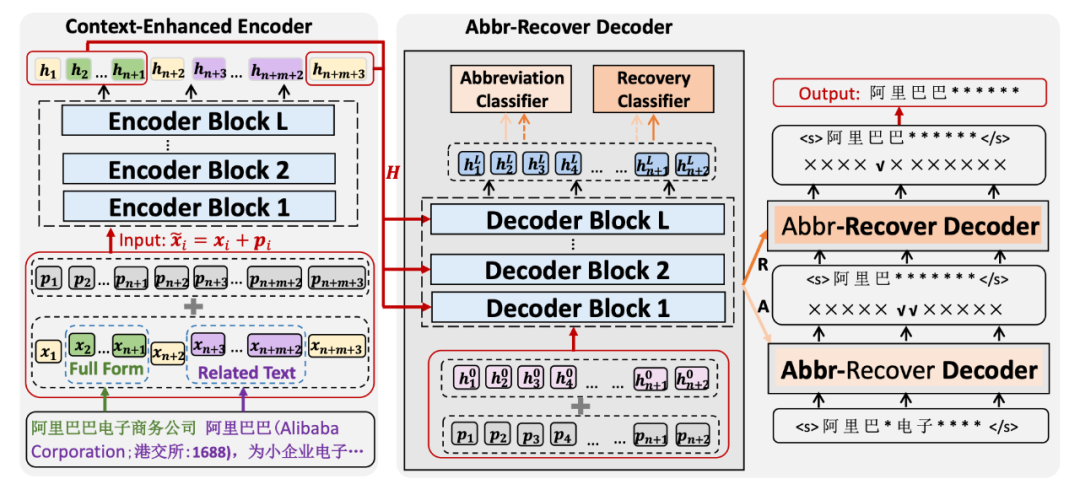
▲ 图2:基于上下文增强和缩略-恢复策略的缩略词transformer框架图
2.1 上下文增强编码器
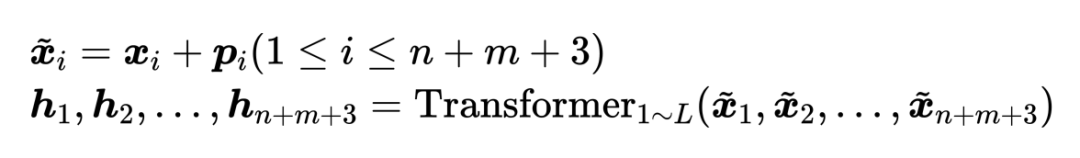
2.2 缩略-恢复解码器
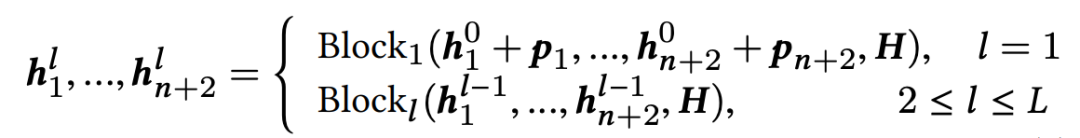
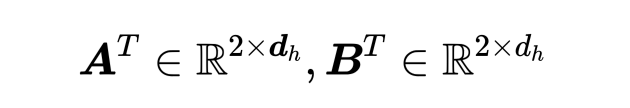
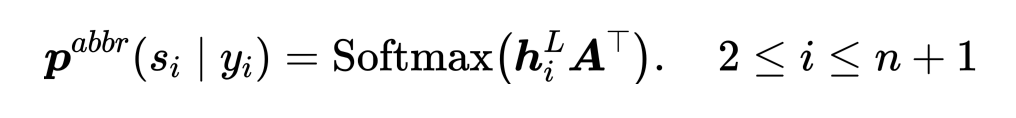
恢复分类器:
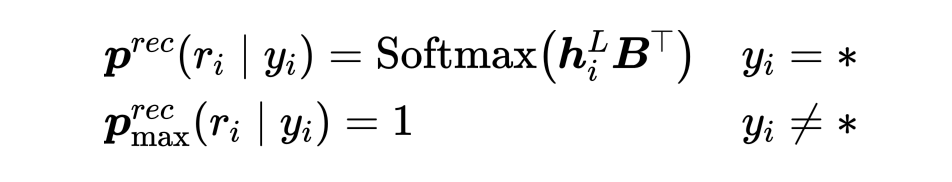

我们将 CETAR 与基线模型在三个中文缩写数据集上进行了比较,其中两个属于通用领域,一个属于特定的景点领域。后者是基于阿里飞猪景点 POI 实体及其别名构建的中文缩略词数据集。对于通用领域的数据集中的实体,我们选取了其百度百科描述性文本的第一句话作为相关文本;而对于飞猪中文缩略词数据集中的景点 POI 实体,我们则是以其最相关的评论文本及 query 文本作为相关文本。
至于评价指标,首先,我们使用 Hit 作为指标来比较模型的性能。测试样本被视为命中样本如果它的预测缩写和它 ground-truth 缩写一模一样。而 Hit score 是命中样本占所有测试样本的比例。此外,考虑到一些实体有多个缩写,我们进一步考虑了以下指标,这些指标是基于对从测试集中随机选择的 500 个样本的人工评估计算得出的,包括正确样本、NA、NW 和 WOM 在所有人类评估样本中的比例。
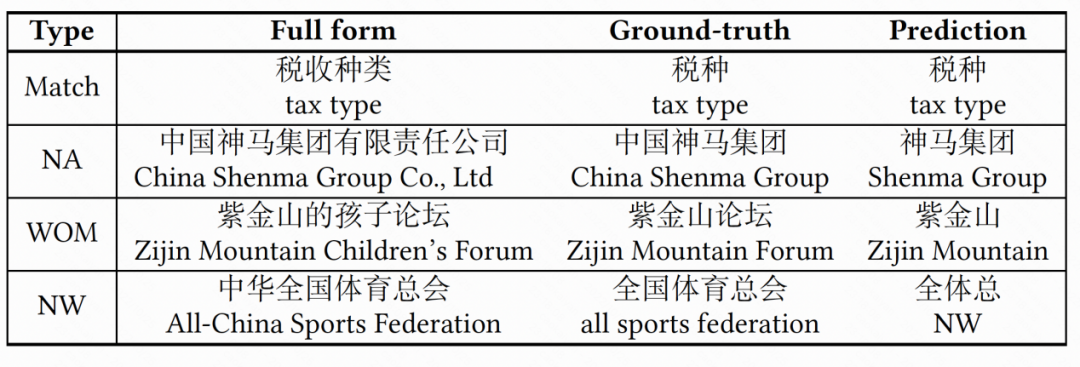
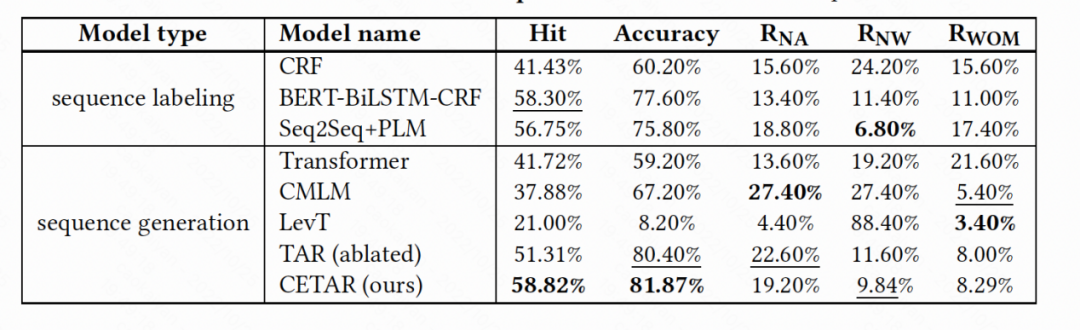
▲ 表3: 数据集一各模型表现
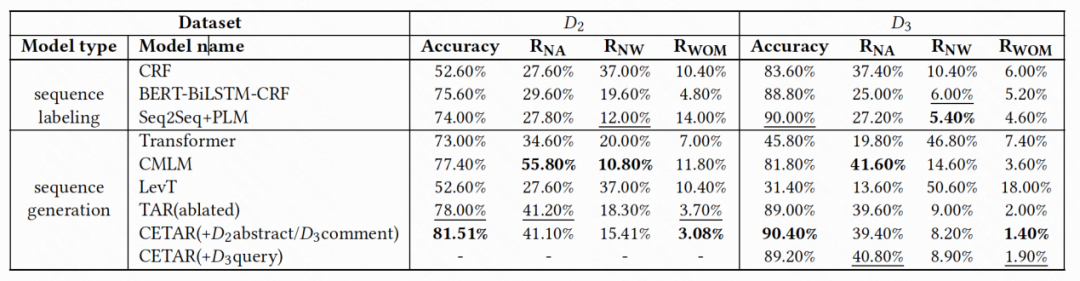
▲ 表4: 数据集二和数据集三各模型表现
从表 3 和表 4,我们得到以下结论:
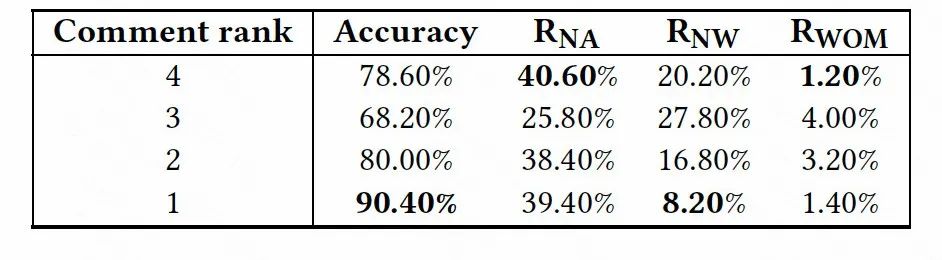
3.1 消融实验
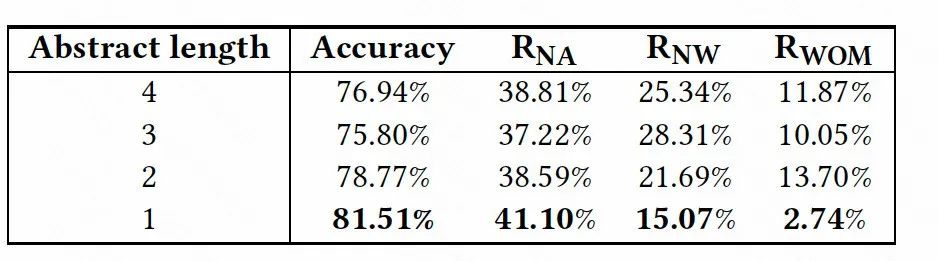
事实上,输入过多的文本可能会产生过多的噪音,也会消耗更多的计算资源。为了寻求输入文本的最佳长度,我们比较了 CETAR 在 D2 上输入百度百科实体摘要的前 1∼4 个句子时的性能。
表 5 表明,输入摘要的第一句表现最好。通过对从数据集中随机抽取的 300 个样本的调查,我们发现大约 75.33% 的第一句话提到了源实体的类型。这也证明了实体类型是促使 CETAR 生成正确缩略词序列的关键信息。
▲ 表6: CETAR 针对数据集三中输入实体不同长度的文本(评论)预测结果
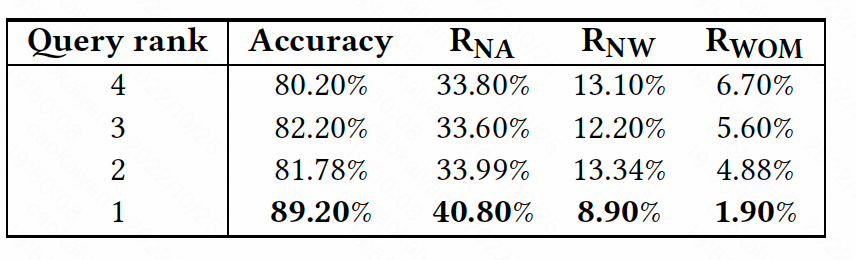
同样,作为数据集三(表 6 & 表 7),CETAR 在将语义最相关(第一个)的评论或查询集作为相关文本时取得了最佳性能。通过深入调查,我们发现热门评论(查询)更有可能包含目标实体的缩略词,帮助 CETAR 实现更准确的预测。
3.2 应用
为了验证缩略词在搜索系统中提高召回率和准确捕捉用户搜索意图的有效性,我们将 CETAR 预测的 56,190 个 POI 实体的缩略词部署到飞猪的搜索系统中。然后,我们进行了持续 4 天的大规模 A/B 测试,发现处理桶与对照桶相比,获得了 2.03% 的 CVR 提升。那为什么有意义呢?例如,基于精确关键字匹配的搜索系统不会为查询“迪士尼乐园”返回酒店“上海迪士尼乐园酒店”,因为酒店的名称与查询不完全匹配。但是,如果预先将“迪士尼”识别为“迪士尼度假区”的缩略词,则可以更轻松地将酒店与查询相关联。

总结
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧




