Java8 Lambda实现源码解析

前言
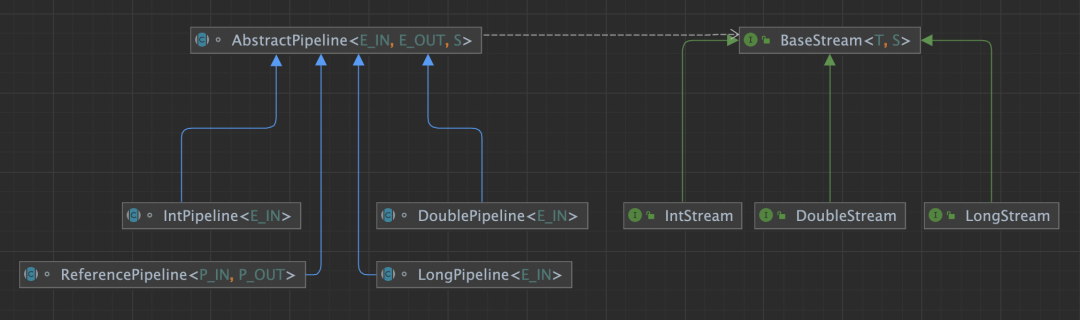
基础示例与解析
static class A {private String a;private Integer b;public A(String a, Integer b) {this.a = a;this.b = b;}}public static void main(String[] args) {List<Integer> ret = Lists.newArrayList(new A("a", 1), new A("b", 2), new A("c", 3)).stream().map(A::getB).filter(b -> b >= 2).collect(Collectors.toList());System.out.println(ret);}
ArrayList.stream
.map
.filter
.collect
default Stream<E> stream() {return StreamSupport.stream(spliterator(), false);}
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {Objects.requireNonNull(spliterator);return new ReferencePipeline.Head<>(spliterator,StreamOpFlag.fromCharacteristics(spliterator),parallel);}
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {Objects.requireNonNull(mapper);return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {return new Sink.ChainedReference<P_OUT, R>(sink) {public void accept(P_OUT u) {downstream.accept(mapper.apply(u));}};}};}
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) { Objects.requireNonNull(predicate); return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE, StreamOpFlag.NOT_SIZED) { Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) { return new Sink.ChainedReference<P_OUT, P_OUT>(sink) { public void begin(long size) { downstream.begin(-1); }
public void accept(P_OUT u) { if (predicate.test(u)) downstream.accept(u); } }; } }; }
public final <R, A> R collect(Collector<? super P_OUT, A, R> collector) { A container; if (isParallel() && (collector.characteristics().contains(Collector.Characteristics.CONCURRENT)) && (!isOrdered() || collector.characteristics().contains(Collector.Characteristics.UNORDERED))) { container = collector.supplier().get(); BiConsumer<A, ? super P_OUT> accumulator = collector.accumulator(); forEach(u -> accumulator.accept(container, u)); } else { container = evaluate(ReduceOps.makeRef(collector)); } return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH) ? (R) container : collector.finisher().apply(container); }
A container = evaluate(ReduceOps.makeRef(collector));return collector.characteristics().contains(Collector.Characteristics.IDENTITY_FINISH)? (R) container: collector.finisher().apply(container);}
public static <T, I> TerminalOp<T, I> makeRef(Collector<? super T, I, ?> collector) { Supplier<I> supplier = Objects.requireNonNull(collector).supplier(); BiConsumer<I, ? super T> accumulator = collector.accumulator(); BinaryOperator<I> combiner = collector.combiner(); class ReducingSink extends Box<I> implements AccumulatingSink<T, I, ReducingSink> { public void begin(long size) { state = supplier.get(); }
public void accept(T t) { accumulator.accept(state, t); }
public void combine(ReducingSink other) { state = combiner.apply(state, other.state); } } return new ReduceOp<T, I, ReducingSink>(StreamShape.REFERENCE) { public ReducingSink makeSink() { return new ReducingSink(); }
public int getOpFlags() { return collector.characteristics().contains(Collector.Characteristics.UNORDERED) ? StreamOpFlag.NOT_ORDERED : 0; } }; }
terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));public <P_IN> R evaluateSequential(PipelineHelper<T> helper,Spliterator<P_IN> spliterator) {return helper.wrapAndCopyInto(makeSink(), spliterator).get();}
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator); return sink;
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) { Objects.requireNonNull(sink);
for ( AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) { sink = p.opWrapSink(p.previousStage.combinedFlags, sink); } return (Sink<P_IN>) sink; }
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) { Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) { wrappedSink.begin(spliterator.getExactSizeIfKnown()); spliterator.forEachRemaining(wrappedSink); wrappedSink.end(); } else { copyIntoWithCancel(wrappedSink, spliterator); } }
wrappedSink.begin(spliterator.getExactSizeIfKnown());spliterator.forEachRemaining(wrappedSink);wrappedSink.end();
public void forEachRemaining(Consumer<? super E> action) { // ... if ((i = index) >= 0 && (index = hi) <= a.length) { for (; i < hi; ++i) { ("unchecked") E e = (E) a[i]; action.accept(e); } if (lst.modCount == mc) return; } // ...
而这里调用action.accept,就会通过责任链来一层层调用每个算子的accept,我们从map的accept开始:
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {return new Sink.ChainedReference<P_OUT, R>(sink) {public void accept(P_OUT u) {downstream.accept(mapper.apply(u));}};}
public interface BaseStream<T, S extends BaseStream<T, S>> extends AutoCloseable { /** * 返回stream中元素的迭代器 */ Iterator<T> iterator();
/** * 返回stream中元素的spliterator,用于并行执行 */ Spliterator<T> spliterator();
/** * 是否并行 */ boolean isParallel();
/** * 返回串行的stream,即强制parallel=false */ S sequential();
/** * 返回并行的stream,即强制parallel=true */ S parallel();
// ...}
/*** 最顶上的pipeline,即Head*/private final AbstractPipeline sourceStage;/*** 直接上游pipeline*/private final AbstractPipeline previousStage;/*** 直接下游pipeline*/@SuppressWarnings("rawtypes")private AbstractPipeline nextStage;/*** pipeline深度*/private int depth;/*** head的spliterator*/private Spliterator> sourceSpliterator;// ...
双流concat的场景示例及解析
static class Mapper1 implements IntUnaryOperator {
public int applyAsInt(int operand) { return operand * operand; } } static class Filter1 implements IntPredicate {
public boolean test(int value) { return value >= 2; } }
static class Mapper2 implements IntUnaryOperator {
public int applyAsInt(int operand) { return operand + operand; } }
static class Filter2 implements IntPredicate {
public boolean test(int value) { return value >= 10; } } static class Mapper3 implements IntUnaryOperator {
public int applyAsInt(int operand) { return operand * operand; } }
static class Filter3 implements IntPredicate {
public boolean test(int value) { return value >= 10; } }
public static void main(String[] args) { IntStream s1 = Arrays.stream(new int[] {1, 2, 3}) .map(new Mapper1()) .filter(new Filter1());
IntStream s2 = Arrays.stream(new int[] {4, 5, 6}) .map(new Mapper2()) .filter(new Filter2());
IntStream s3 = IntStream.concat(s1, s2) .map(new Mapper3()) .filter(new Filter3()); int sum = s3.sum(); }
terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);return sink;}
Head(concated s1 + s2 stream) -> Mapper3 -> Filter3 -> ReduceOp(sum)
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {Objects.requireNonNull(wrappedSink);if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {wrappedSink.begin(spliterator.getExactSizeIfKnown());spliterator.forEachRemaining(wrappedSink);wrappedSink.end();// ...
public void forEachRemaining(Consumer<? super T> consumer) {if (beforeSplit)aSpliterator.forEachRemaining(consumer);bSpliterator.forEachRemaining(consumer);}
// 包装的原始pipeline final PipelineHelper<P_OUT> ph;
// 原始pipeline的spliterator Spliterator<P_IN> spliterator;
public void forEachRemaining(IntConsumer consumer) {if (buffer == null && !finished) {Objects.requireNonNull(consumer);init();ph.wrapAndCopyInto((Sink.OfInt) consumer::accept, spliterator);finished = true;}// ...
可以看到,又调用了原始pipeline的wrapAndCopyInto方法中,而这里的consumer即为上面s3的逻辑。这样又递归回到了:
AbstractPipeline.wrapAndCopyInto -> AbstractPipeline.wrapSink-> AbstractPipeline.copyInto
方法中,而在这时的wrapSink中,现在的pipeline就是s1/s2了,这时就会对s1/s2下面的所有算子,调用AbstractPipeline.opWrapSink串联起来,以s1为例就变成:
「我是技术人」1024技术创作挑战赛——相信分享的价值
阿里云开发者社区&阿里开发者微信公众号联合推出的创作挑战赛进入征稿倒计时!活动截止11月30日,我们邀请你,前往社区分享你的技术思考,让创作创造价值!
点击阅读原文查看详情。
登录查看更多
相关内容

Arxiv
10+阅读 · 2021年12月13日
Arxiv
16+阅读 · 2017年11月20日


相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2021年12月13日
Arxiv
16+阅读 · 2017年11月20日