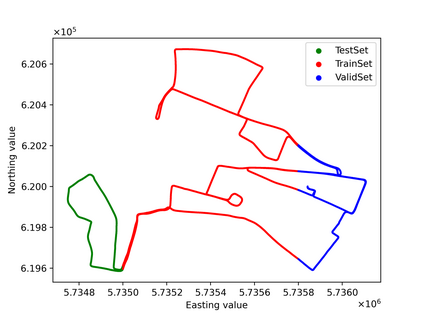
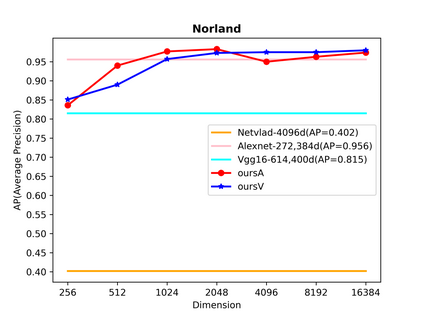
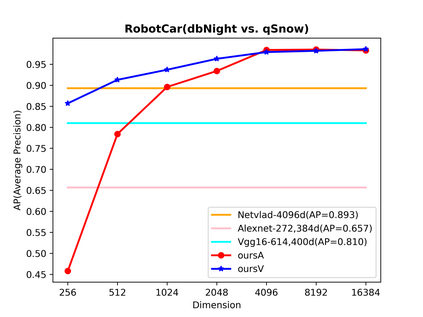
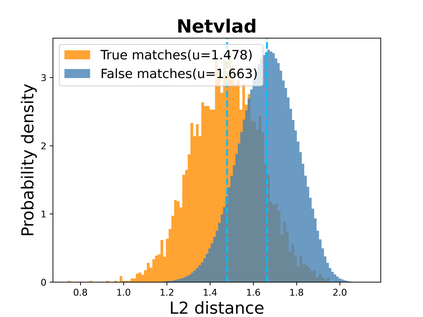
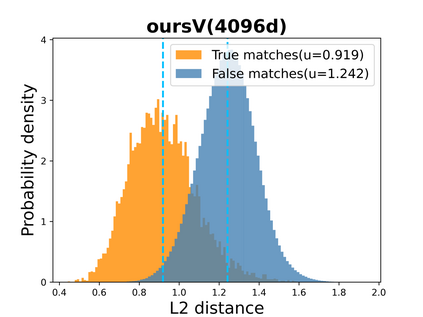
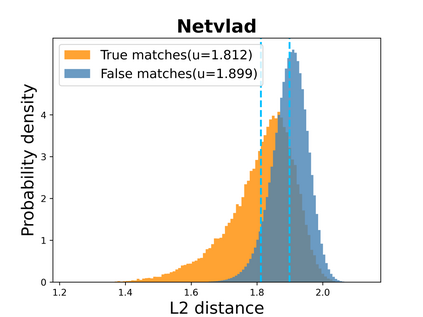
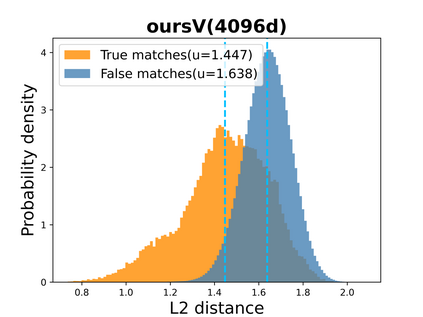
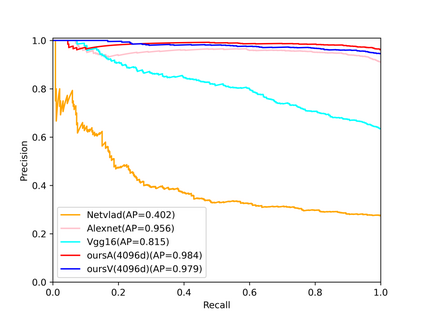
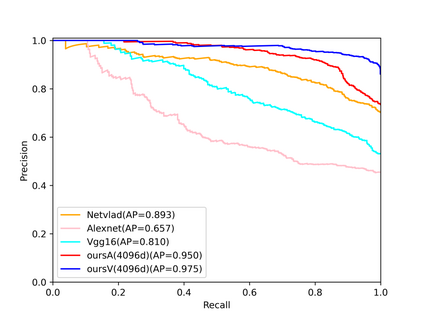
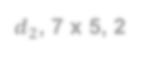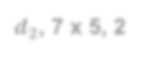Visual place recognition (VPR) in condition-varying environments is still an open problem. Popular solutions are CNN-based image descriptors, which have been shown to outperform traditional image descriptors based on hand-crafted visual features. However, there are two drawbacks of current CNN-based descriptors: a) their high dimension and b) lack of generalization, leading to low efficiency and poor performance in applications. In this paper, we propose to use a convolutional autoencoder (CAE) to tackle this problem. We employ a high-level layer of a pre-trained CNN to generate features, and train a CAE to map the features to a low-dimensional space to improve the condition invariance property of the descriptor and reduce its dimension at the same time. We verify our method in three challenging datasets involving significant illumination changes, and our method is shown to be superior to the state-of-the-art. For the benefit of the community, we make public the source code.
翻译:在条件变化环境中的视觉位置识别(VPR)仍然是一个尚未解决的问题。流行的解决方案是有线电视新闻网(CNN)的图像描述器,这些描述器已经显示在手工制作的视觉特征上优于传统的图像描述器。然而,目前有线电视新闻网(CNN)的描述器有两个缺点:(a) 其高维度和(b) 缺乏概括化,导致应用效率低和性能差。在本文中,我们提议使用一个革命自动生成器(CAE)来解决这一问题。我们使用一个经过预先训练的CNN的高层来生成特征,并培训CAE,将特征绘制到一个低维空间,以改善描述器的无弹性属性并同时减少其尺寸。我们用三个具有挑战性的数据集来验证我们的方法,这三套涉及重大的照明变化,我们的方法被证明优于最新技术。为了社区的利益,我们公布源代码。