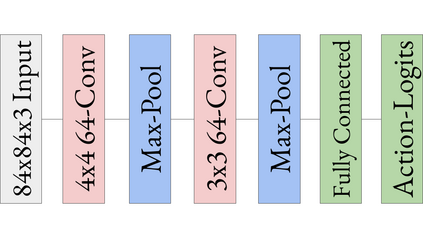
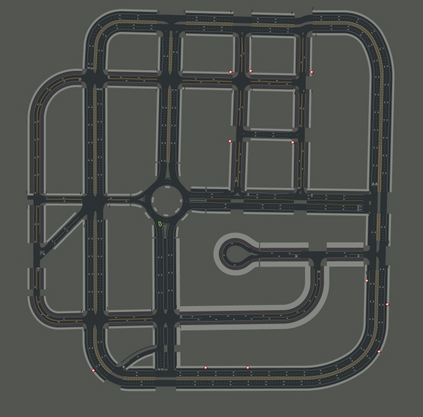
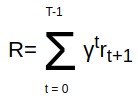Deep reinforcement learning is actively used for training autonomous car policies in a simulated driving environment. Due to the large availability of various reinforcement learning algorithms and the lack of their systematic comparison across different driving scenarios, we are unsure of which ones are more effective for training autonomous car software in single-agent as well as multi-agent driving environments. A benchmarking framework for the comparison of deep reinforcement learning in a vision-based autonomous driving will open up the possibilities for training better autonomous car driving policies. To address these challenges, we provide an open and reusable benchmarking framework for systematic evaluation and comparative analysis of deep reinforcement learning algorithms for autonomous driving in a single- and multi-agent environment. Using the framework, we perform a comparative study of discrete and continuous action space deep reinforcement learning algorithms. We also propose a comprehensive multi-objective reward function designed for the evaluation of deep reinforcement learning-based autonomous driving agents. We run the experiments in a vision-only high-fidelity urban driving simulated environments. The results indicate that only some of the deep reinforcement learning algorithms perform consistently better across single and multi-agent scenarios when trained in various multi-agent-only environment settings. For example, A3C- and TD3-based autonomous cars perform comparatively better in terms of more robust actions and minimal driving errors in both single and multi-agent scenarios. We conclude that different deep reinforcement learning algorithms exhibit different driving and testing performance in different scenarios, which underlines the need for their systematic comparative analysis. The benchmarking framework proposed in this paper facilitates such a comparison.
翻译:深度强化学习正在积极用于在模拟驾驶环境中训练自动驾驶策略。由于各种强化学习算法的大量可用性以及在不同驾驶场景中缺乏其系统比较,我们不确定哪些算法更有效地训练单智能体和多智能体驾驶软件的策略。一个用于比较深度强化学习在基于视觉的自主驾驶中的基准框架将为训练更好的自动驾驶汽车驾驶策略开辟可能性。为应对这些挑战,我们提供了一个开放且可重复使用的基准框架,用于系统评估和比较分析单个和多个驾驶环境下深度强化学习算法的自主驾驶。使用该框架,我们进行了离散和连续行动空间深度强化学习算法的比较研究,并提出了一个全面的多目标回报函数,用于评估基于深度强化学习的自主驾驶代理。我们在仅基于视觉的高保真度城市驾驶模拟环境中运行实验。结果表明,只有部分深度强化学习算法在各种多智能体环境设置下的训练中在单智能体和多智能体场景中表现更加稳健。例如,在单个和多个驾驶场景中,基于A3C和TD3的自动驾驶汽车的表现相对更好,具有更稳健的行动和最小的驾驶误差。我们得出结论,不同的深度强化学习算法在不同的场景中表现出不同的驾驶和测试性能,这强调了对它们进行系统比较分析的需求。本文提出的基准框架有助于进行这样的比较。