

**1 引言 **
基础模型(FMs)的崛起在视觉识别[131, 211, 218]、语言理解[24, 59, 193, 194]和知识发现[21, 201]等领域引发了一系列突破。在计算医疗[3, 72]领域,FMs能够处理各种临床数据,其在逻辑推理和语义理解方面的吸引力不言而喻。例子涵盖了医疗对话[241, 316]、患者健康档案[48]和治疗规划[192]等领域。此外,鉴于其在大规模数据处理方面的优势,FMs提供了一种快速有效评估实际临床数据的新范式,从而改善医疗工作流程[208, 261]。 FMs研究重点放在以数据为中心的视角[318]。首先,FMs展示了规模的力量,其中扩大的模型和数据规模使FMs能够捕获大量信息,因此增加了对训练数据量的迫切需求[272]。其次,FMs鼓励同质化[21],这一点通过它们广泛适应下游任务的能力得到了证明。因此,高质量的FM训练数据变得至关重要,因为它会影响预训练FM和下游模型的性能。因此,解决关键的数据挑战被逐渐认为是研究的重点。在医疗系统中,收集高质量的记录可以实现对患者特征(影像、基因组和实验室检测数据)的全面了解[6, 121, 244]。正如所示,以数据为中心的策略有望重塑临床工作流程[122, 219],实现精确诊断[111],并揭示治疗方面的见解[40]。 医疗数据挑战在过去几十年一直是持续的障碍,包括多模态数据融合(第4节)、有限的数据量(第5节)、标注负担(第6节)以及患者隐私保护的关键问题(第7节)[38, 94, 108, 215]。为了应对,FM时代开启了推进以数据为中心的AI分析的视角。例如,多模态FMs可以提供针对不同数据格式的可扩展数据融合策略[63, 146]。同时,FM生成高质量数据的吸引力可以大大帮助解决医疗和医疗保健社区中的数据数量、稀缺性和隐私问题[33, 63, 168, 257, 269, 331]。为了构建负责任的医疗AI解决方案,AI与人类一致性的不断发展视角[77, 191]变得越来越重要。我们讨论了FMs在现实世界中与人类伦理、公平和社会规范保持一致的必要性,以减少在性能评估、伦理合规性和患者安全方面的潜在风险[94, 154, 163, 198]。在FM时代,实现AI与人类的一致性进一步强调了数据焦点的重要性,激励我们优先考虑计算医疗领域中的以数据为中心的挑战。 在这篇综述中,我们提供了一个关于开发、分析和评估针对医疗的FM为中心的方法的广泛视角。从图1所示的以数据为中心的视角来看,我们强调了患者、医疗数据和基础模型之间的相互作用。我们收集并讨论了分析FMs所需的基本概念、模型、数据集和工具(图2)。最后,我们强调了在医疗和医学中应用FMs时出现的新风险,包括隐私保护和伦理使用方面。我们提出了基于FM的分析技术的有希望的方向,以提高患者结果的预测性能并简化临床数据工作流程,最终将构建更好的、与AI人类相一致的、以数据为中心的工具、方法和系统,用于医疗和医学。
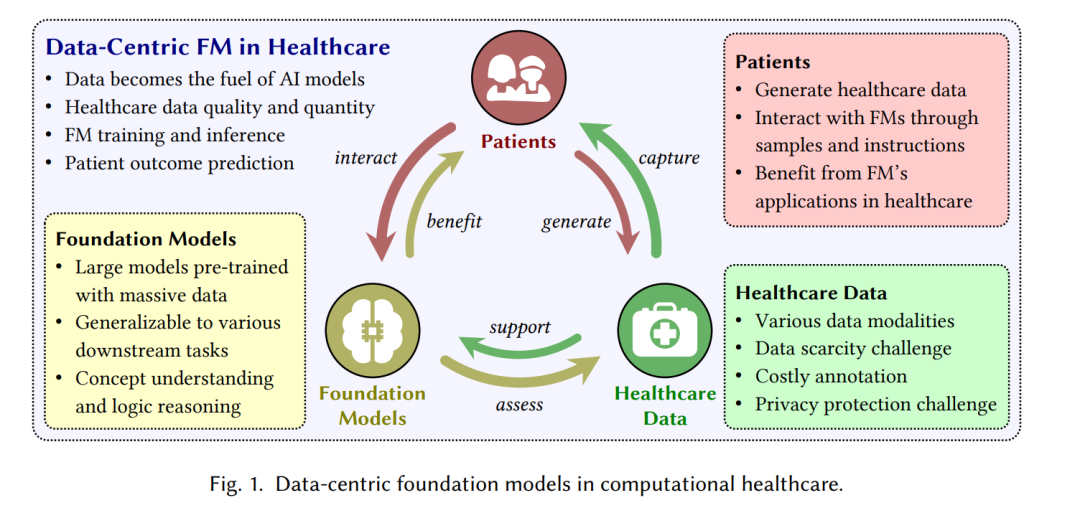
基础模型(FM)分析的增长为医疗应用提供了洞见[208, 295, 321]。我们回顾了解决医疗领域中FM多个方面的关键技术、工具和应用。我们展示了如何将通用目的的FMs应用于医疗领域(第3.1节)。我们介绍了专注于医疗的FMs,并展示了从通用FMs中获得的预训练优势(第3.2节)。
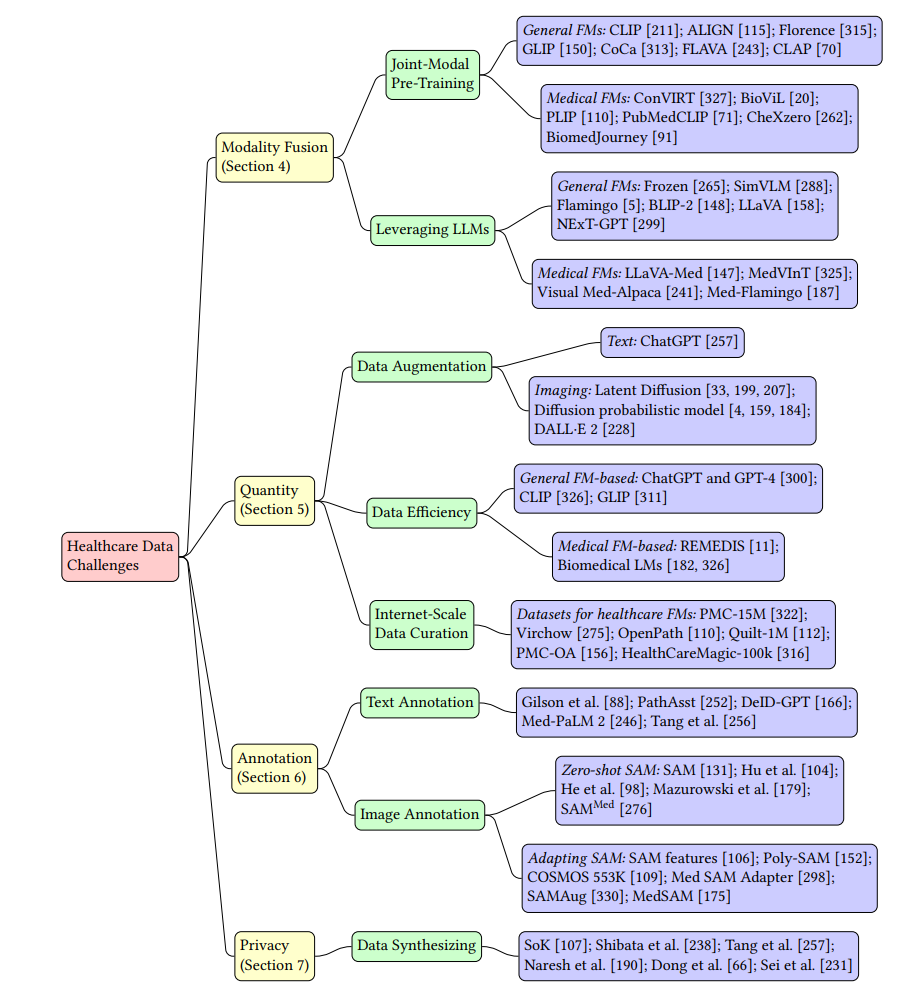
基础模型与医疗健康
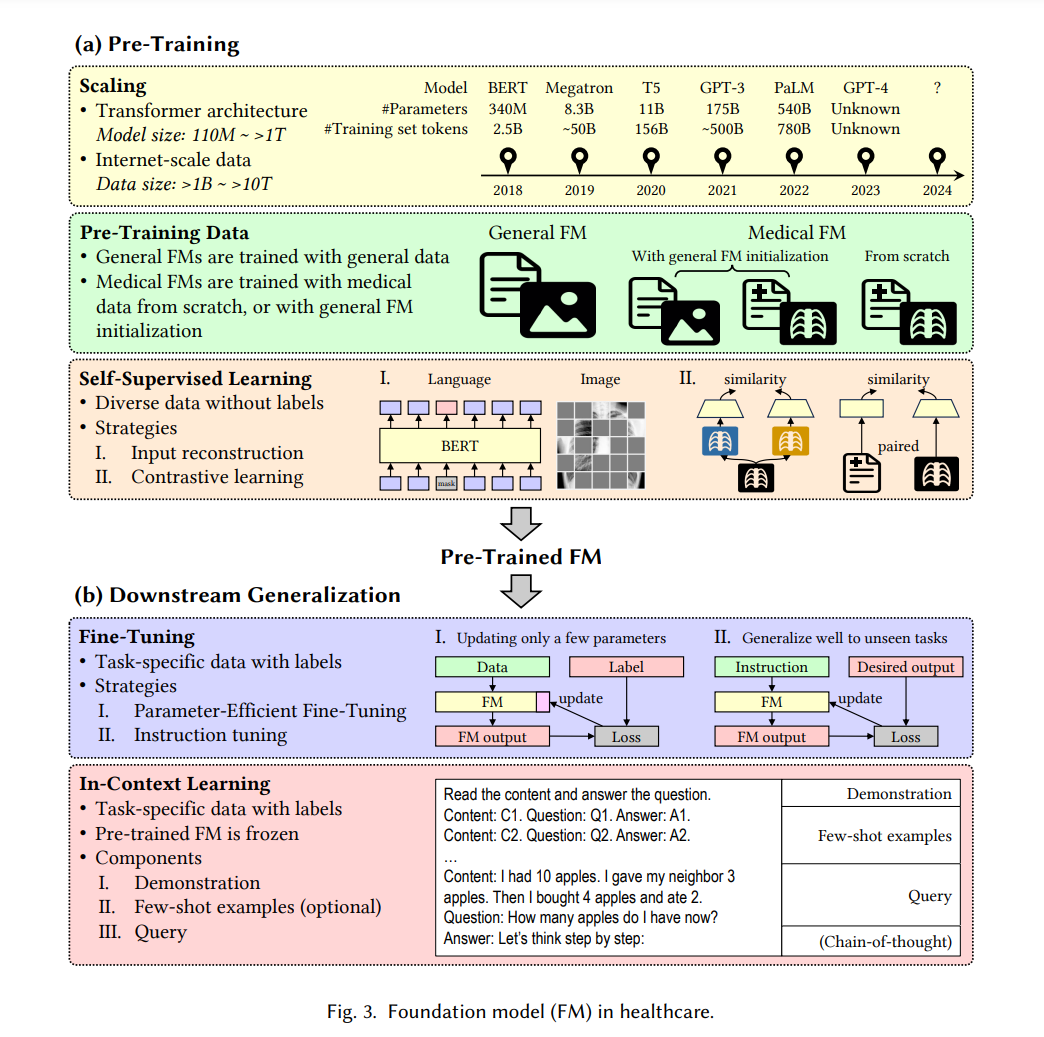
在医疗和医疗保健中适应通用基础模型 研究工作已经开始评估FM在医学领域的卓越能力[85, 192, 227]。在这些研究中,我们确定了两个核心技术:参数高效微调(PEFT)和情境中学习(ICL)。
** 通过参数高效微调(PEFT)进行适应。**
PEFT方法已被应用于将FMs适配到医学任务。例如,Dutt等人[68]展示了PEFT方法在医学图像分类和文本到图像生成任务的数据有限场景中显著优于FMs的完全微调。Gema等人[85]提出了一个两阶段PEFT框架,将LLaMA[263]适应到一系列临床任务。在这项工作中,第一阶段应用LoRA[105]对LLaMA进行微调,构建了针对临床笔记的Clinical LLaMA-LoRA;第二阶段再次应用LoRA将临床FM适配到下游任务。他们还展示了LoRA作为PEFT方法的主要选择之一,非常适合临床领域适配。同样,Van Veen等人[271]应用LoRA对T5模型[143, 214]进行微调,用于放射科报告摘要。他们还将LoRA与情境中学习结合应用于临床文本摘要任务,表现出比人类专家更好的性能[273]。
通过情境中学习(ICL)进行适应。
ICL已证明在适应FMs,特别是大型语言模型(LLMs),到各种医疗任务中是有效的。通过精心设计的特定任务输入上下文(即提示),FM可以在不修改任何模型参数的情况下很好地完成医疗任务。例如,Nori等人[192]评估了GPT-4[194]在美国医学执照考试(USMLE)上的表现,而没有特别设计的提示。GPT-4展示了其令人期待的零样本性能,即使没有添加相关医疗背景数据。Lyu等人[174]利用ChatGPT[193]将放射学报告翻译成通俗语言,以便于报告理解和翻译。实验表明,通过使用更清晰、更结构化的提示,整体翻译质量可以提高。Roy等人[227]展示了SAM[131]在腹部CT器官分割中的出色泛化能力,通过其点/边框提示。Deng等人[58]评估了SAM在肿瘤分割、非肿瘤组织分割和整个幻灯片图像(WSI)上的细胞核分割的零样本性能,证明了SAM在病理扫描中大型连通物体上表现良好。Chen等人提出了“思维诊断”(DoT)提示[43],以协助专业人士检测认知扭曲。DoT通过提示LLMs依次进行主观性评估、对比推理和模式分析来诊断精神疾病。
预训练医疗基础模型
研究人员努力基于大规模未标记的医疗数据预训练FMs,用于健康记录检查[7, 90, 245]、医学影像诊断[11, 287]和蛋白质序列分析[45, 157]。原则上,预训练过程可以概括为两个主要方面:预训练策略和模型初始化。
预训练策略。
医疗FM的预训练通常利用一系列从通用领域FMs衍生的预训练策略,因为它们具有潜在的泛化能力。第一个预训练策略是遮蔽语言/图像建模,遵循BERT[59]和遮蔽自动编码器(MAE)[96]。例如,SciBERT[14]和PubMedBERT[90]分别基于BERT策略在多领域科学出版物和生物医学领域特定语料库上进行预训练。BioLinkBERT[309]利用生物医学文档之间的链接,并基于遮蔽语言建模和文档关系预测任务进行预训练。BioGPT[172]基于GPT-2[213]在PubMed1摘要上进行预训练,用于生成语言任务。RETFound[334]是一个用于视网膜图像疾病检测的FM,基于MAE在大量未标记的视网膜图像上进行预训练,以重构具有75%遮蔽区域的输入图像。同样,General Expression Transformer (GET)[74]是一个用于建模213种人类细胞类型的转录调节的FM。GET被预训练以预测输入中遮蔽调节元素的基序结合分数,以学习调节模式。 对比学习是另一种重要的医疗FM预训练策略。例如,REMEDIS[11]是一个通过对比学习预训练的医学视觉模型,用于提取医学图像的代表性视觉特征。例如MedCLIP[287]、MI-Zero[171]和PLIP[110]等视觉-语言模型是通过对比学习在特定领域的图像-文本对上进行预训练的。它们在放射学和病理学中的零样本图像分类任务上取得了积极的表现。
结论
基础模型(FMs)及其在医疗保健领域的应用所取得的显著进展,为更好的患者管理和高效的临床工作流程打开了新的可能性。在这些努力中,收集、处理和分析可扩展的医疗数据对于基础模型研究变得越来越关键。在这篇综述中,我们提供了从数据中心视角出发对基础模型挑战的概述。基础模型具有巨大潜力,可以缓解医疗保健中的数据挑战,包括数据不平衡和偏见、数据稀缺以及高昂的注释成本。由于基础模型强大的内容生成能力,对数据隐私、数据偏见以及对生成的医疗知识的伦理考虑需要更加警惕。只有充分可靠地解决数据中心的挑战,我们才能更好地利用基础模型在医学和医疗保健的更广泛范围内的力量。
