
南京大学最新《基于模型的强化学习》综述论文,值得关注!
强化学习(RL)通过与环境交互的试错过程来解决顺序决策问题。虽然RL在允许大量试错的复杂电子游戏中取得了杰出的成功,但在现实世界中犯错总是不希望的。为了提高样本效率从而减少误差,基于模型的强化学习(MBRL)被认为是一个有前途的方向,它建立的环境模型中可以进行试错,而不需要实际成本。本文对MBRL的研究现状进行了综述,并着重介绍了近年来研究的进展。对于非表格环境,学习到的环境模型与实际环境之间存在泛化误差。因此,分析环境模型中策略训练与实际环境中策略训练的差异,对算法设计、模型使用和策略训练具有重要的指导意义。此外,我们还讨论了离线在线学习、目标条件在线学习、多智能体在线学习和元在线学习等基于模型的在线学习技术的最新进展。此外,我们还讨论了MBRL在实际任务中的适用性和优势。最后,我们讨论了MBRL未来的发展前景。我们认为MBRL在实际应用中具有巨大的潜力和优势,但这些优势往往被忽视,希望本文的综述能够吸引更多关于MBRL的研究。
强化学习(Reinforcement learning, RL)研究了提高自主智能体序列决策性能的方法[Sutton and Barto, 2018]。由于深度RL在围棋和电子游戏中的成功展示了超越人类的决策能力,因此将其应用范围扩展到现实任务中是非常有意义的。通常,深度RL算法需要大量的训练样本,导致样本复杂度很高。在一般的RL任务中,特定算法的样本复杂度是指学习一个近似最优策略所需的样本量。特别地,与监督学习范式从历史标记数据中学习不同,典型的RL算法需要通过在环境中运行最新的策略来获得交互数据。一旦策略更新,基础数据分布(正式的入住率测量[Syed et al., 2008])就会发生变化,必须通过运行策略再次收集数据。因此,具有高样本复杂度的RL算法很难直接应用于现实世界的任务中,因为在这些任务中,试错代价很高。
因此,近年来深度强化学习(deep reinforcement learning, DRL)研究的一个主要重点是提高样本效率[Yu, 2018]。在不同的研究分支中,基于模型的强化学习(MBRL)是最重要的方向之一,人们普遍认为它具有极大的潜力使RL算法显著提高样本效率[Wang et al., 2019]。这种信念直观地来自于对人类智慧的类比。人类能够在头脑中拥有一个想象的世界,在这个世界中,随着不同的行动,事情会如何发生可以被预测。通过这种方式,可以根据想象选择适当的行动,这样就可以降低反复试验的成本。MBRL中的短语模型是期望扮演与想象相同角色的环境模型。
在MBRL中,环境模型(或简称为模型)指的是学习智能体与之交互的环境动态的抽象。RL中的动态环境通常被表述为一个马尔可夫决策过程(MDP),用元组(S, A, M, R, γ)表示,其中S, A和γ分别表示状态空间、行动空间和未来奖励的折扣因子,M: S × A→S表示状态转移动力学,R: S × A→R表示奖励函数。通常情况下,给定状态和行为空间以及折扣因子,环境模型的关键组成部分是状态转移动力学和奖励函数。因此,学习模型对应于恢复状态转移动力学M和奖励函数r。在许多情况下,奖励函数也被明确定义,因此模型学习的主要任务是学习状态转移动力学[Luo et al., 2018, Janner et al., 2019]。
有了环境模型,智能体就有了想象的能力。它可以与模型进行交互,以便对交互数据进行采样,也称为仿真数据。理想情况下,如果模型足够准确,可以在模型中学习到一个好的策略。与无模型强化学习(model-free reinforcement learning, MFRL)方法相比,智能体只能使用从与真实环境的交互中采样的数据,称为经验数据,MBRL方法使智能体能够充分利用学习模型中的经验数据。值得注意的是,除了MBRL,还有其他一些方法试图更好地利用经验数据,如off-policy算法(使用重放缓冲区记录旧数据)和actor-critic算法(通过学习评论家来促进策略更新)。图1描述了不同类型的RL结构。图1(a)是最简单的on-policy RL,其中智能体使用最新的数据来更新策略。在off-policy中,如图1(b)所示,代理在重放缓冲区中收集历史数据,在重放缓冲区中学习策略。在行动者-评论者RL中,如1(c)所示,智能体学习评论者,其是长期回报的价值函数,然后学习批评者辅助的策略(行动者)。如图1(d)所示,MBRL显式地学习一个模型。与策略外RL相比,MBRL重构了状态转移的动态过程,而策略外RL只是简单地使用重放缓冲区来更稳健地估计值。虽然价值函数或批评的计算涉及到转移动力学的信息,但MBRL中的学习模型与策略解耦,因此可以用于评估其他策略,而价值函数与抽样策略绑定。此外,请注意,非策略、演员-评论者和基于模型是三个并行的结构,图1(e)显示了它们的可能组合。
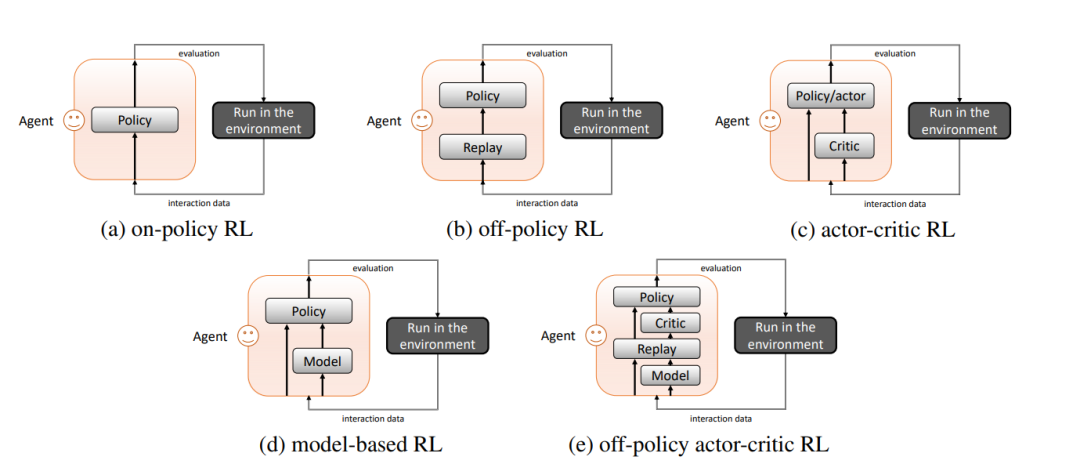
RL算法的体系结构。图中显示了RL的训练迭代,重点是如何利用交互数据。
通过足够准确的模型,可以直观地看到MBRL比MFRL产生更高的样本效率,这一点在最近的理论研究[Sun el.,2019年]和经验研究[Janner et al.,2019年,Wang et al.,2019年]的视角都表明了这一点。然而,在大量具有相对复杂环境的DRL任务中,要学习一个理想的模型并非易事。因此,我们需要仔细考虑模型学习和模型使用的方法。
在这一综述中,我们对基于模型的强化学习方法进行了全面的综述。首先,我们关注模型是如何在基本设置中学习和使用的,如第3节的模型学习和第4节的模型使用。对于模型学习,我们从经典的表格表示模型开始,然后使用神经网络等近似模型,我们回顾了在面对复杂环境时的理论和关键挑战,以及减少模型误差的进展。对于模型的使用,我们将文献分为两部分,即用于轨迹采样的黑箱模型rollout和用于梯度传播的白箱模型。将模型使用作为模型学习的后续任务,我们还讨论了在模型学习和模型使用之间建立桥梁的尝试,即价值感知模型学习和策略感知模型学习。此外,我们简要回顾了基于模型的方法在其他形式的强化学习中的组合,包括离线强化学习、目标条件强化学习、多智能体强化学习和元强化学习。我们还讨论了MBRL在现实任务中的适用性和优势。最后,我们对MBRL的研究前景和未来发展趋势进行了展望。
