
本文主要聚焦于小模型(即轻量型模型)的自监督学习问题,作者通过实证发现:对比自监督学习方法在大模型训练方面表现出了很大进展,然这些方法在小模型上的表现并不好。
为解决上述问题,本文提出了一种新的学习框架:自监督蒸馏(SElf-SupErvised Distillation, SEED),它通过自监督方式(SSL)将老师模型的知识表达能力迁移给学生模型。不同于直接在无监督数据上的直接学习,我们训练学生模型去模拟老师模型在一组示例上的相似度得分分布。
所提SEED的简洁性与灵活性不言而喻,包含这样三点:(1) 无需任何聚类/元计算步骤生成伪标签/隐类;(2) 老师模型可以通过优秀的自监督学习(比如MoCo-V2、SimCLR、SWAV等)方法进行预训练;(3)老师模型的知识表达能力可以蒸馏到任意小模型中(比如更浅、更细,甚至可以是完全不同的架构)。
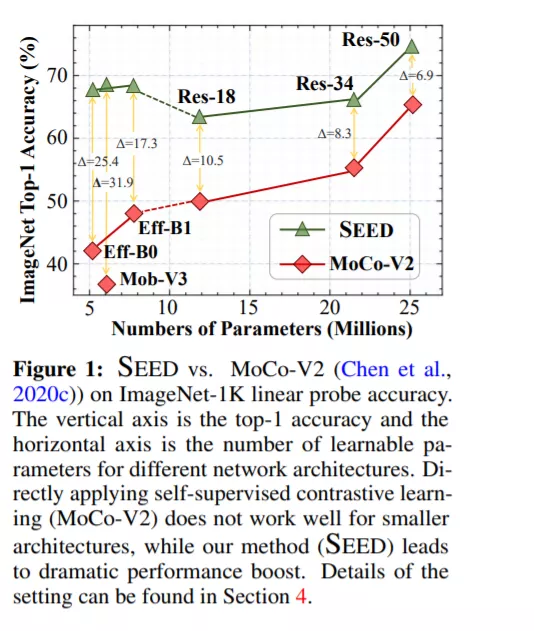
实验表明:SEED可以提升小模型在下游任务上的性能表现。相比自监督基准MoCo-V2方案,在ImageNet数据集上,SEED可以将EfficientNet-B0的精度从42.2%提升到67.6%,将MobileNetV3-Large的精度从36.3%提升到68.2%,见下图对比。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2021年6月1日
相关VIP内容
相关资讯