图数据天然存在不均衡现象,即存在某些部分拥有丰富数据而其他部分数据稀缺,如何处理这一问题?来自新加坡国立大学的学者最新《不均衡图学习》综述,详述不均衡图学习技术,值得关注!

A Survey of Imbalanced Learning on Graphs: Problems, Techniques, and Future Directions Zemin Liu, Yuan Li, Nan Chen, Qian Wang, Bryan Hooi, Bingsheng He
Graphs,表示在多种实际场景中普遍存在的互连结构。有效的图分析(graph analytics),如图学习方法,能使用户从图数据中获取有效的知识,以便赋能诸如节点分类和链接预测等的下游任务。 然而,这些方法通常会受到数据不均衡问题的困扰:在图数据中,存在某些部分拥有丰富数据而其他部分数据稀缺,从而导致偏倚的预测结果。这就促使了不均衡图学习这一研究领域的出现,其旨在纠正这些数据分布偏倚,以获取更加均衡准确的模型性能。
在本survey中,我们全面回顾了图上的不均衡学习文献。我们首先提供了相关概念和术语,以便为读者的理解建立坚实的基础。然后,我们提出了两个综合性的分类方法:(1)问题分类法,描述了我们考虑的不均衡形式、相关任务、及潜在的解决方案;(2)技术分类法,介绍了解决这些不均衡问题的关键策略,以便帮助读者进行方法选择。最后,我们提出了关于不均衡图学习领域problems和techniques的未来发展方向,以便促进这一关键领域的进一步创新和发展。
arXiv预印本:https://arxiv.org/abs/2308.13821 https://www.zhuanzhi.ai/paper/96b8424b9caca9059bf560129c5a17fc GitHub文献整理:https://github.com/Xtra-Computing/Awesome-Literature-ILoGs
1.概述
图(Graphs),是指常见于现实场景中的实体间互连的结构。其在多个领域中是普遍存在的,如在Facebook等社交网络、DBLP等引用网络、及Amazon等电子商务网络中。图结构的广泛分布促进了图分析任务的快速发展,其旨在挖掘和利用图中的潜在信息,以便服务于下游任务,如节点分类、链接预测和图分类等。 早期的图分析常常依赖于传统技术,如特征工程(feature engineering)等,其往往具有较高的计算复杂度。然而,图表示学习(graph representation learning)的出现为图分析带来了新的发展机遇。图表示学习旨在将图的结构(如节点、边或子图等)嵌入到低维向量空间中,同时保留它们的结构信息。早期的图嵌入方法(graph embedding approaches),如Deepwalk、LINE和node2vec等,依赖于节点之间的上下文连接特征以捕捉节点间的相关性,用于节点表示学习。
最近,越来越多的研究焦点转向了图神经网络(Graph Neural Networks, GNNs),这是一类基于邻域聚合的图表示学习方法。它们通过端到端的邻域聚合在边上递归式地传递和接收消息,从而有效地编码图的结构。因此,在许多下游任务中,GNNs基本上取得了最好的性能。
**不均衡现象。**尽管这些图表示学习方法是有效的,但与许多机器学习模型一样,它们通常需要大量的标记数据进行训练。然而,现实世界的数据经常呈现出不均衡的分布:其中一些分组拥有大量数据信息,而其他一些分组则数据稀缺。例如,在分类任务中,标记数据(如图像或文档)的分布可能集中于某些大类中,导致标签分布不均衡。这种数据不均衡可能显著影响训练过程。具体而言,模型往往在具有充足数据的“高资源”(high-resource)分组上训练较好,而在数据有限的“低资源”(low-resource)分组上表现不佳,从而导致类别边界不清晰。因此,不均衡学习(imbalanced learning)这一挑战性问题在当前引起了极大的关注,有效解决这些问题是当务之急。
不均衡图学习。为了解决不均衡问题,视觉(Computer Vision,CV)和语言(Natural Language Processing,NLP)等领域已经提出了切实可行的相关方法。然而,与之不同的是,图数据在本质上并不服从独立同分布(non-iid),并且具有多方面的结构特征(如节点度数等)。直接将这些方法应用于解决图上的不均衡问题可能并不可行。因此,图学习面临着与这些场景不同的新型的不均衡问题的挑战。

近期,不均衡问题对图任务性能的显著影响已吸引了大量的相关研究,如上图Fig.1所示。其逐年增加的文献数量反映了在图学习领域解决不均衡挑战的强烈需求。这些研究内容主要集中于解决图上的各种不均衡任务。每个任务,由于其独特的问题特征,需要研究专门的技术以有效解决其特定场景下的不均衡问题。然而,其问题(problems)和技术(techniques)的多样性导致了不均衡图学习这一研究领域的松散格局,缺乏一个全面的框架来总结它们的共性和差异。
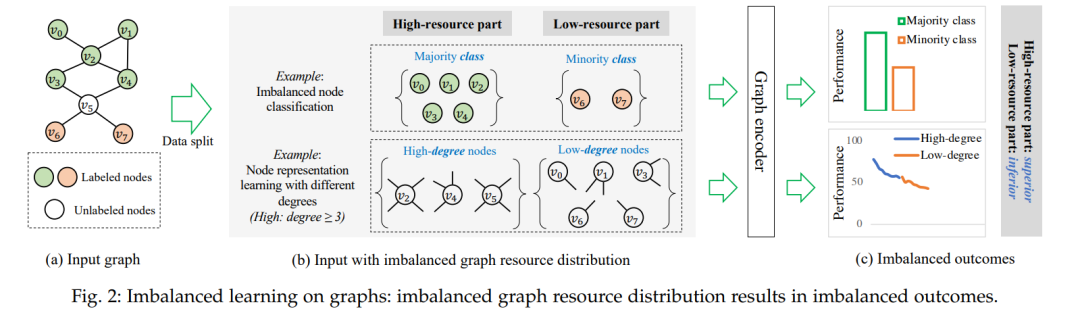
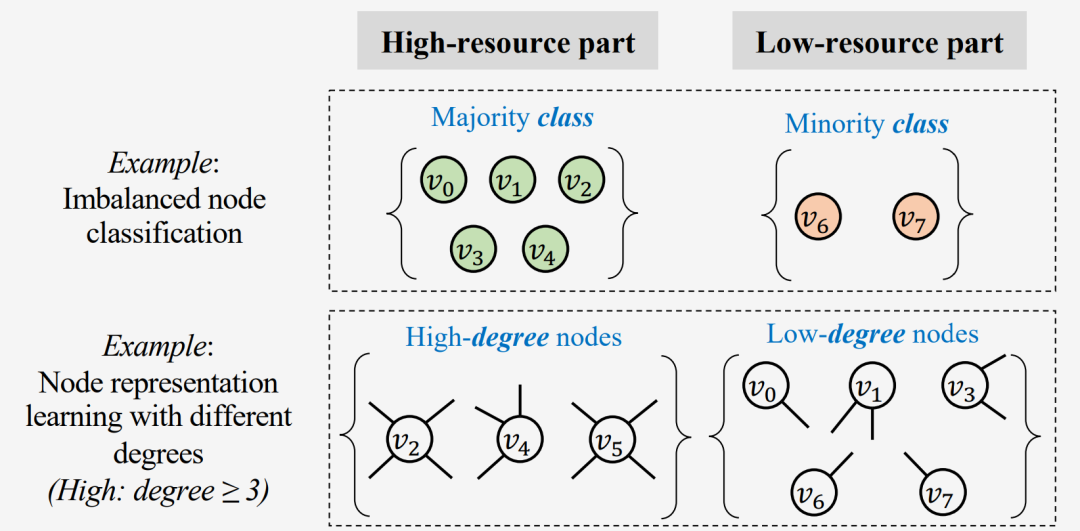
因此,在本survey中,我们重点研究不均衡图学习任务(Imbalanced Learning on Graphs,ILoGs),通过回顾和总结在解决图上的不均衡问题的背景下所涉及的相关问题和主要技术,以填补这一空白。ILoGs的本质在于,具有不均衡输入的图学习模型通常在具有不同丰富程度的图资源分组之间表现出不同的性能。更确切地说,如上图Fig.2所示,在给定输入图的情况下,图数据通常被分成多个组成部分,形成了不均衡的图资源分布。此现象可以在多种任务中提现,如不均衡节点分类(imbalanced node classification)和具有不同度数的节点表示学习(node representation learning considering different degrees),如上图Fig.2(b)所示。这种不均衡的分布往往导致不均衡的性能表现:图模型通常在高资源部分表现良好,而将低资源部分边缘化,最终导致性能不均衡,如上图Fig.2(c)所示。
2. 分类方法
然而,不均衡图学习的多面性特点使其研究具有一定程度的复杂性。一方面,图结构的多样性推动了多种类型的不均衡研究工作的发展,其中包含了多种形式的不均衡、多种形式的任务、及多种形式的解决方案。这种多样性的特点使得在梳理总结这些研究内容时具有一定的挑战性。因此,构建一个合理的分类方法以对不均衡图学习任务的问题(problems)进行有效地分类是一项重要任务。此外,详细的分类也可以促使发现尚未研究的相关问题,有利于此领域的更为全面的发展。另一方面,图上众多的不均衡问题引出了多样化的解决方案,并且一些任务由于其独特属性需要设计特定的技术加以解决。这使得解决方案变得纷繁复杂,阻碍了这个领域的进一步发展。因此,从技术(techniques)的角度对文献进行分类整理是至关重要的。此外,这种分类方法还可以帮助读者选择适当的技术来处理他们特定的图不均衡问题。
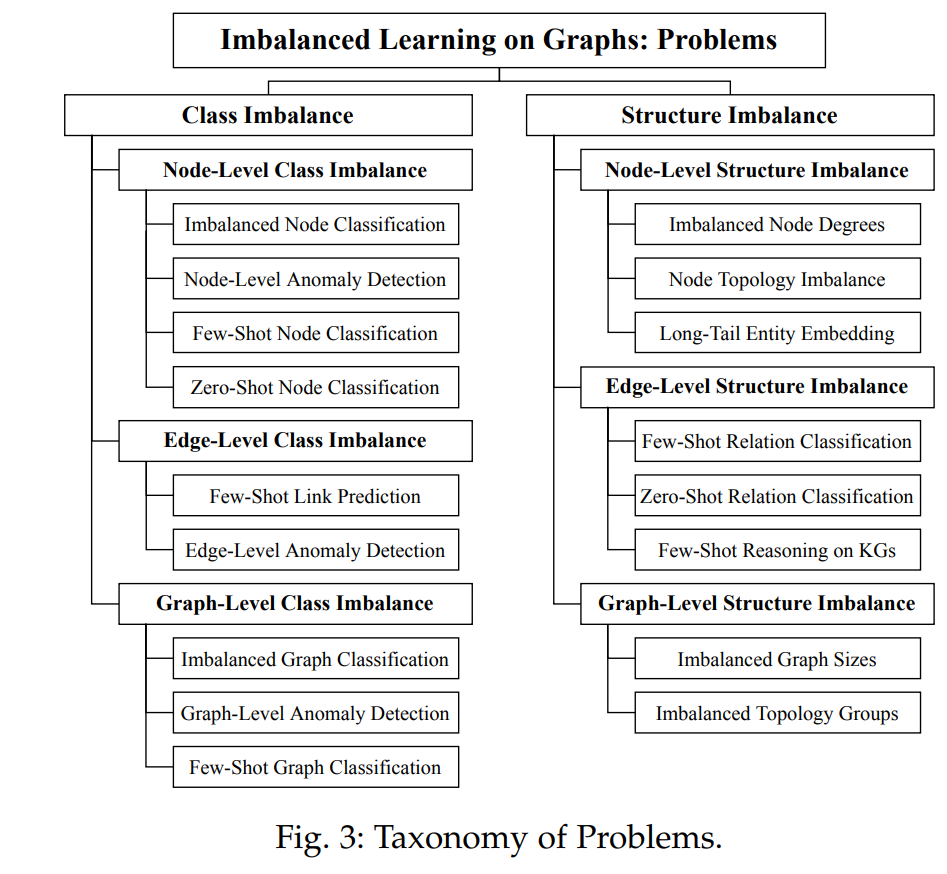
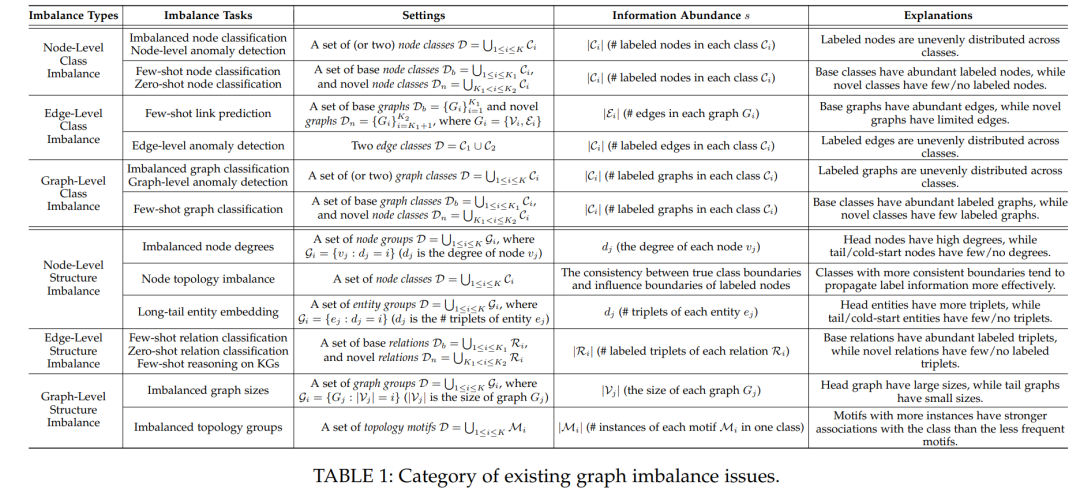
为了解决上述复杂性,我们分别从问题和技术两个角度对文献进行了分类整理,以提供更加全面的概述。首先,对于问题分类,我们分别基于类别不均衡和结构不均衡对文献进行了整理,这两者均源于不均衡的数据输入。我们进一步将其细分为了更具体的类别:节点级、边级和图级,为图不均衡问题提供了更加全面细致的总结,如上图Fig.3所示。此外,为了更清楚地展现这些不均衡问题,我们在下表Table 1中详述和对比了这些不均衡任务的Imbalance types、settings、及information abundance等特征信息。
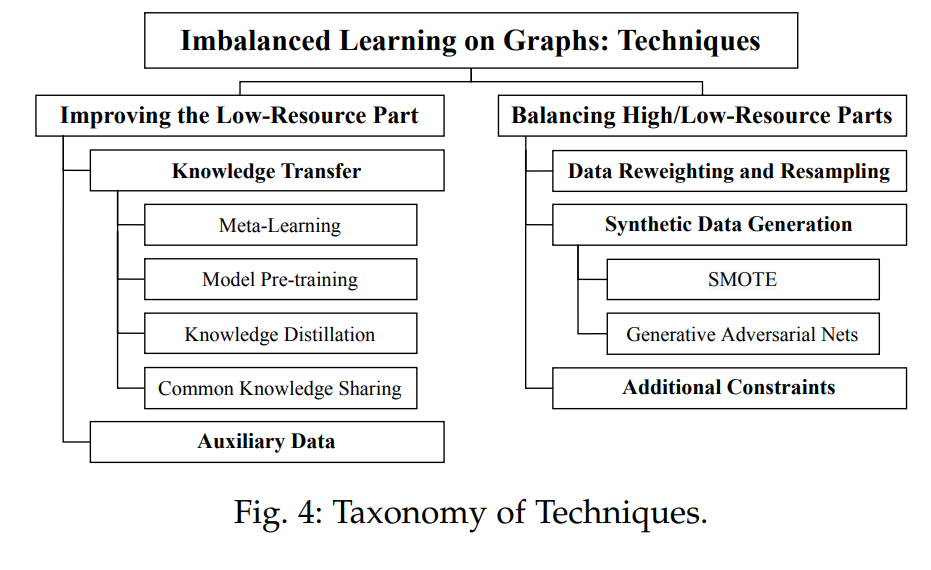
** 其次,对于技术分类,我们根据不均衡的类型及对该问题的应对策略将文献进行了分类整理**,如下图Fig.4所示。这是因为特定类型的不均衡任务可能需要特定的技术来加以有效解决,而所采用的技术可能因不同的不均衡类型而具有较大差异。首先,我们根据information abundance将数据划分为高资源(high-resource)和低资源(low-resource)两个部分(如图Fig.2(b)所示),这导致了基于预测目标的两个任务分支:improving the low-resource part和balancing high/low-resource parts。前者旨在改善低资源部分的性能,而不考虑其他部分;而后者由于需要基于两个部分同时进行结果预测,则致力于在两个部分之间实现性能的均衡。
基于上述的问题和技术的分类方法,我们进一步展望了未来在不均衡图学习领域的潜在研究方向。具体来说,对于问题这一角度的未来探索方向,我们分别从类别不均衡和结构不均衡的视角分析了潜在的挑战。对于技术这一角度的未来发展方向,我们考虑了可能的创新解决方案,以推动该领域的进一步发展。
3.主要贡献
我们的survey主要有以下几个贡献点: 1.我们提供了第一份全面涵盖不均衡图学习任务研究内容的survey工作。鉴于此研究领域的重要性及快速增长的相关研究工作,我们的survey将为研究及工程人员提供宝贵的参考资料。
2.为实现该领域的全面性和结构化的概述,我们引入了两个创新分类方法:问题分类和技术分类。这些分类方法旨在实现对现有文献的全面总结和整理,并通过结构化的分类对现有文献资料相同点和不同点进行了对比和总结。
3.我们探索了不均衡图学习领域未来的潜在研究方向,为有兴趣推动这个快速发展领域的研究人员提供了一定的方向和指导。
更多细节请参照: arXiv预印本:https://arxiv.org/abs/2308.13821 GitHub文献整理:https://github.com/Xtra-Computing/Awesome-Literature-ILoGs