spring-cloud 中 zuul 的两种隔离机制实验
(点击上方公众号,可快速关注)
来源:大名Dean鼎,
www.deanwangpro.com/2018/04/04/spring-cloud-zuul-threads/
ZuulException REJECTED_SEMAPHORE_EXECUTION 是一个最近在性能测试中经常遇到的异常。查询资料发现是因为zuul默认每个路由直接用信号量做隔离,并且默认值是100,也就是当一个路由请求的信号量高于100那么就拒绝服务了,返回500。
信号量隔离
既然默认值太小,那么就在gateway的配置提高各个路由的信号量再实验。
routes:
linkflow:
path: /api1/**
serviceId: lf
stripPrefix: false
semaphore:
maxSemaphores: 2000
oauth:
path: /api2/**
serviceId: lf
stripPrefix: false
semaphore:
maxSemaphores: 1000
两个路由的信号量分开提高到2000和1000。我们再用gatling测试一下。
setUp(scn.inject(rampUsers(200) over (3 seconds)).protocols(httpConf))
这是我们的模型,3s内启动200个用户,顺序访问5个API。所以会有1000个request。机器配置只有2核16G,并且是docker化的数据库。所以整体性能不高。
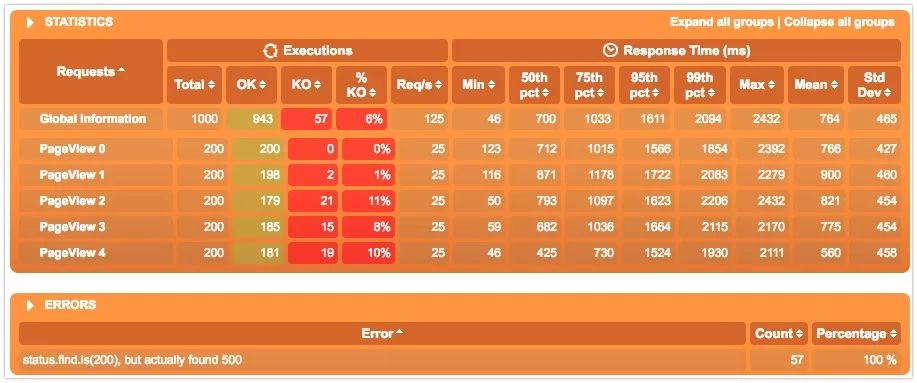
看结果仍然有57个KO,但是比之前1000个Request有900个KO的比例好很多了。
线程隔离
Edgware版本的spring cloud提供了另一种基于线程池的隔离机制。实现起来也非常简单,
zuul:
ribbon-isolation-strategy: THREAD
thread-pool:
use-separate-thread-pools: true
thread-pool-key-prefix: zuulgw
hystrix:
threadpool:
default:
coreSize: 50
maximumSize: 10000
allowMaximumSizeToDivergeFromCoreSize: true
maxQueueSize: -1
execution:
isolation:
thread:
timeoutInMilliseconds: 60000
use-separate-thread-pools的意思是每个路由都有自己的线程池,而不是共享一个。
thread-pool-key-prefix会指定一个线程池前缀方便调试。
hystrix的部分主要设置线程池的大小,这里设置了10000,其实并不是越大越好。线程池越大削峰填谷的效果越显著,也就是时间换空间。系统的整体负载会上升,导致响应时间越来越长,那么当响应时间超过某个限度,其实系统也算是不可用了。后面可以看到数据。
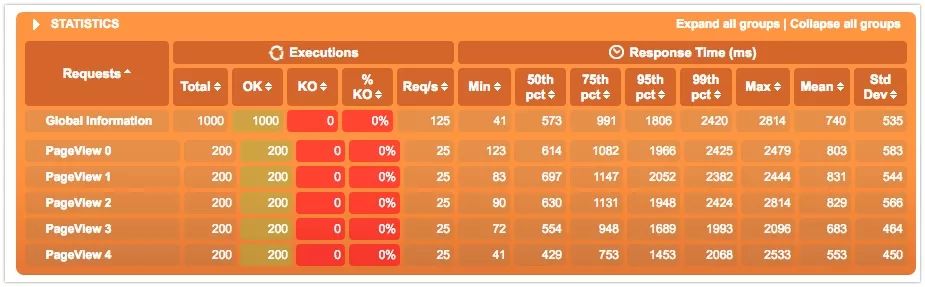
这次没有500的情况了,1000个Request都正常返回了。
比较
从几张图对比下两种隔离的效果,上图是信号量隔离,下图是线程隔离。
响应时间分布
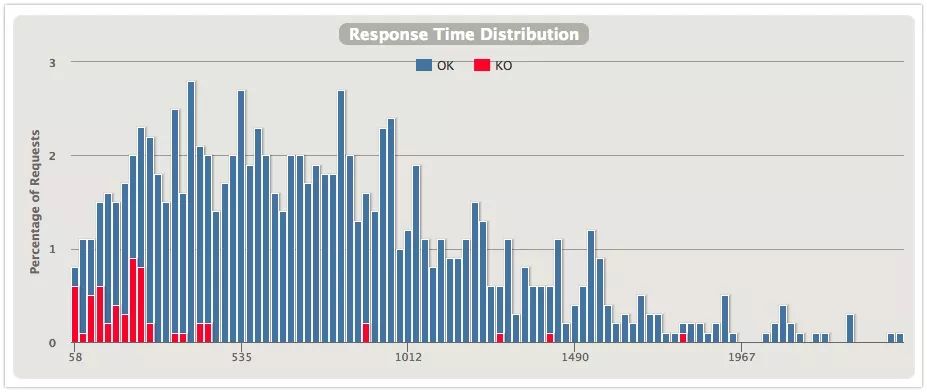
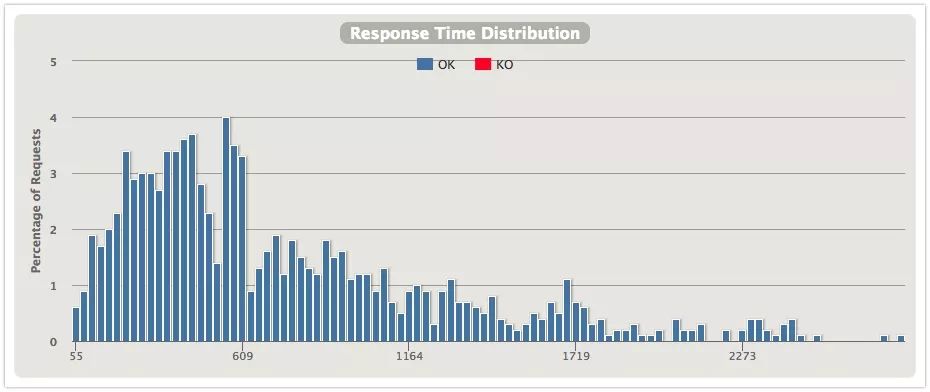
直观上能发现使用线程隔离的分布更好看一些,600ms内的响应会更多一些。
QPS
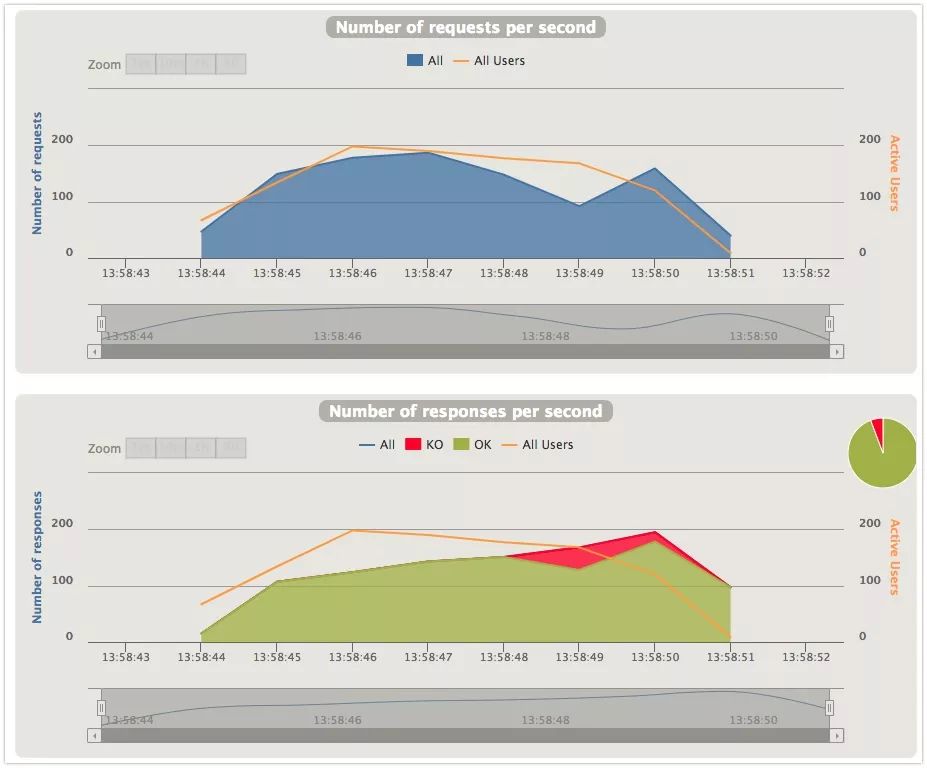
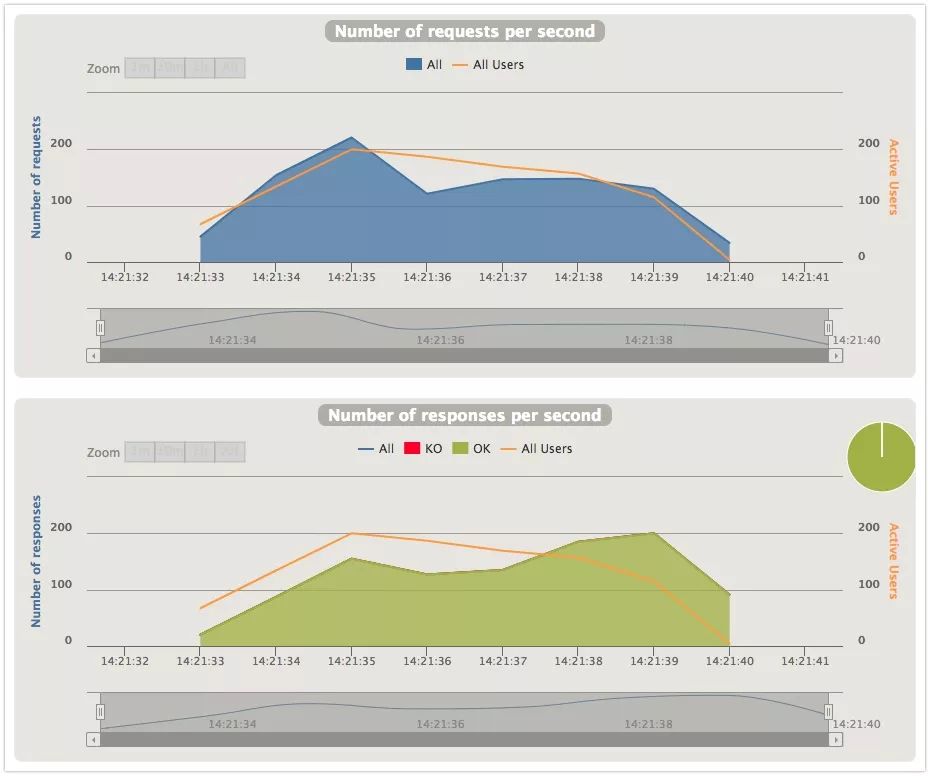
两张图展示的是同一时刻的Request和Response的数量。
先看信号量隔离的场景,Response per second是逐步提升的,但是达到一个量级后,gateway开始拒绝服务。猜测是超过了信号量的限制或是超时?
线程隔离的这张就比较有意思了,可以看到Request per second上升的速度要比上面的快,说明系统是试图接收更多的请求然后分发给线程池。再看在某个时间点Response per second反而开始下降,因为线程不断的创建消耗了大量的系统资源,响应变慢。之后因为请求少了,负载降低,Response又开始抬升。所以线程池也并非越大越好,需要不断调试寻找一个平衡点。
小结
线程池提供了比信号量更好的隔离机制,并且从实际测试发现高吞吐场景下可以完成更多的请求。但是信号量隔离的开销更小,对于本身就是10ms以内的系统,显然信号量更合适。
看完本文有收获?请转发分享给更多人
关注「ImportNew」,提升Java技能




