【CMU-zhanghao博士论文】机器学习并行化:自适应、可组合与自动化,附229页pdf与答辩视频
来自卡内基梅隆大学机器人研究所Zhanghao博士论文,他师从著名的邢波教授!博士题目是机器学习并行可以是自适应的、可组合的和自动化的,不可错过!


Zhang hao, 卡内基梅隆大学机器人研究所博士,导师是Eric Xing教授。毕业后将加入加州大学伯克利分校的RISE实验室,做博士后。
https://www.cs.cmu.edu/~hzhang2/
Machine Learning Parallelism Could Be Adaptive, Composable and Automated
答辩视频

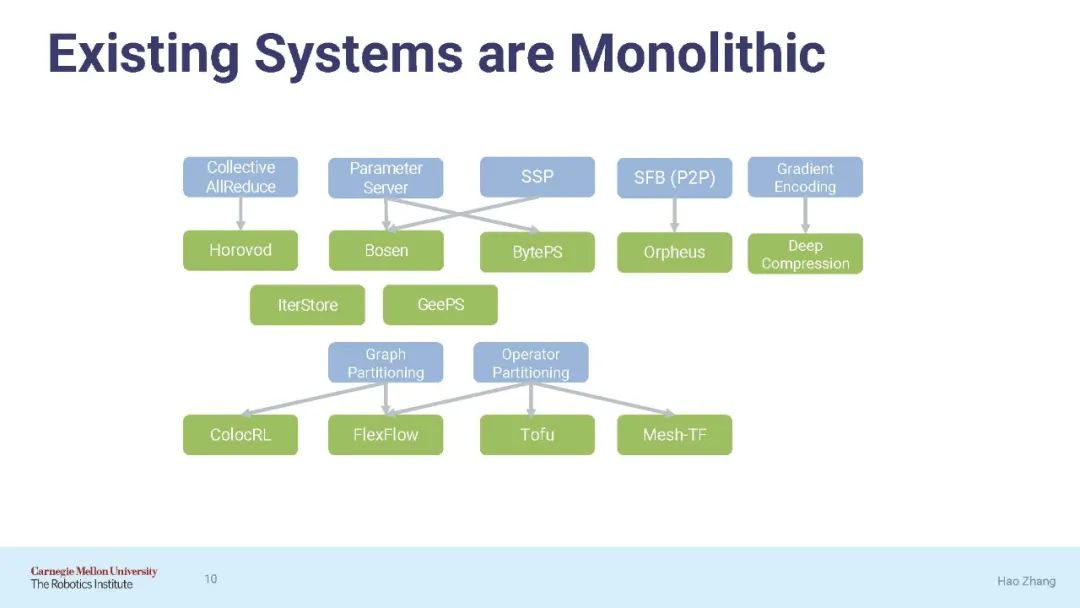
近年来,机器学习(ML)领域的创新步伐加快,SysML的研究人员已经创建了在多个设备或计算节点上并行化ML训练的算法和系统。随着ML模型在结构上变得越来越复杂,许多系统都努力在各种模型上提供全面的性能。一般来说,根据从适当的分布策略映射到模型所需的知识数量和时间,ML的规模通常被低估了。将并行训练系统应用到复杂的模型中,除了模型原型之外,还增加了重要的开发开销,并且经常导致低于预期的性能。本文识别并解决并行ML技术和系统实现在可用性和性能方面的研究挑战。
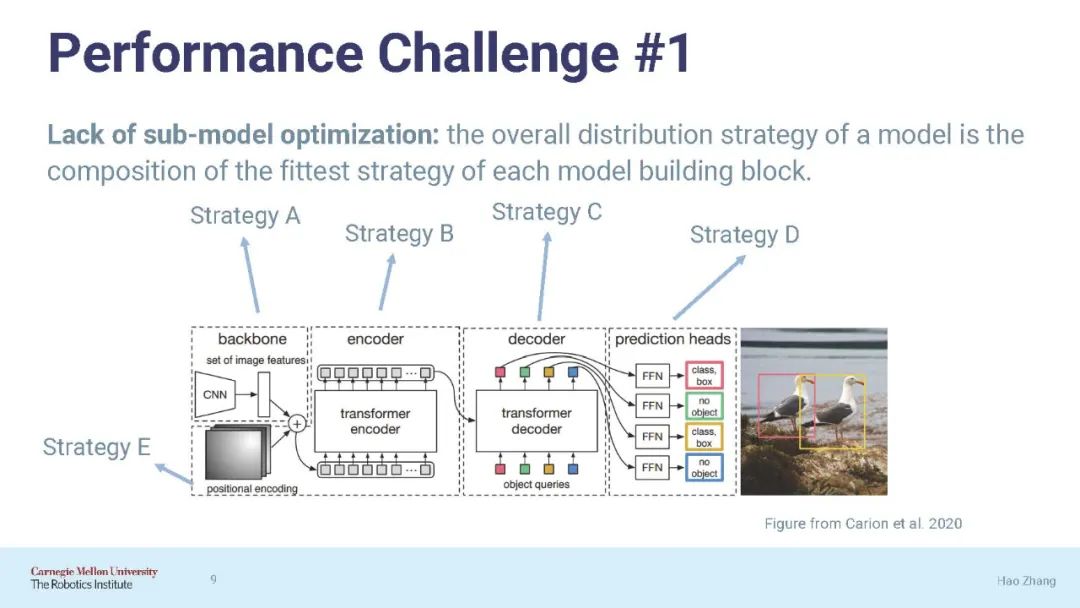
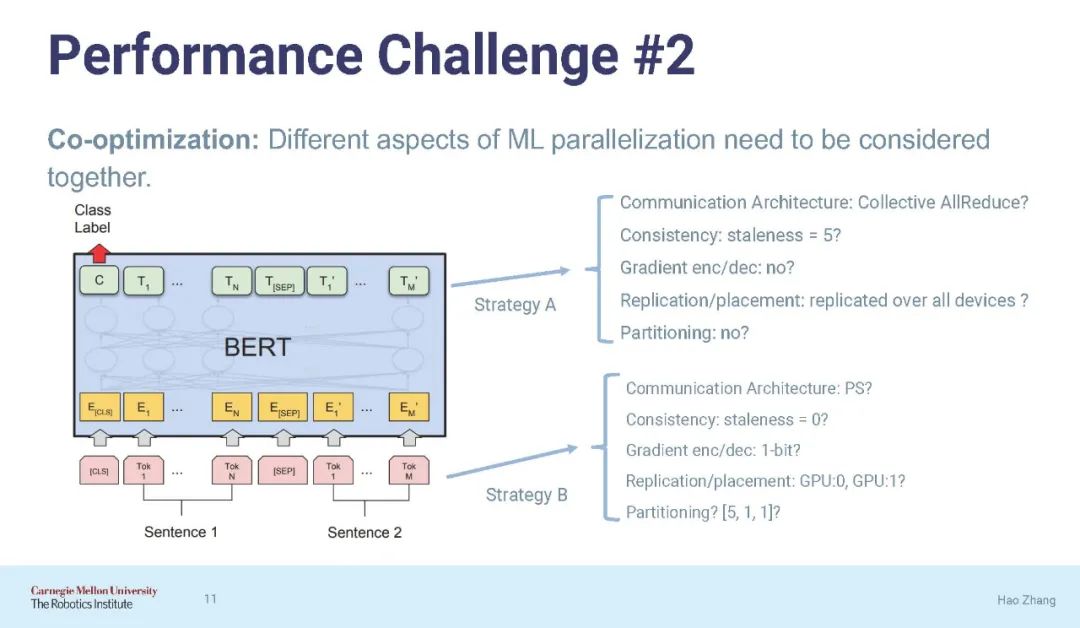
本文的第一部分提出了一个简单的设计原则,自适应并行化,它根据特定的ML属性将适当的并行化技术应用于模型构建块(如层)。接下来,我们导出了一系列优化ML并行化不同方面的优化和实现。我们对它们进行了研究,并表明它们显著提高了ML训练在适用场景下对集群进行2-10倍的效率或可伸缩性。
为了推广这种方法,本论文的第二部分将ML并行化为端到端优化问题,并寻求自动解决它,用于ML并行任务的两种广泛范例:单节点动态批处理和分布式ML并行。我们提出了有原则的表示来表示两类ML并行性,以及可组合的系统架构,分别是Cavs和AutoDist。它们支持为不可见的模型快速组合并行化策略,提高并行化性能,并简化并行ML编程。
在此基础上,本文的第三部分提出了自动并行化框架AutoSync,用于自动优化数据并行分布训练中的同步策略。AutoSync实现了“开框即用”的高性能——它在提议的表现方式所覆盖的范围内导航,并自动识别同步策略,这些同步策略的速度比现有手动优化的系统快1.2 - 1.6倍,降低了分布式ML的技术障碍,并帮助更大的用户社区访问它。本文所开发的技术和系统为分布式环境下大规模ML训练的端到端编译器系统的概念和原型实现提供了理论依据。
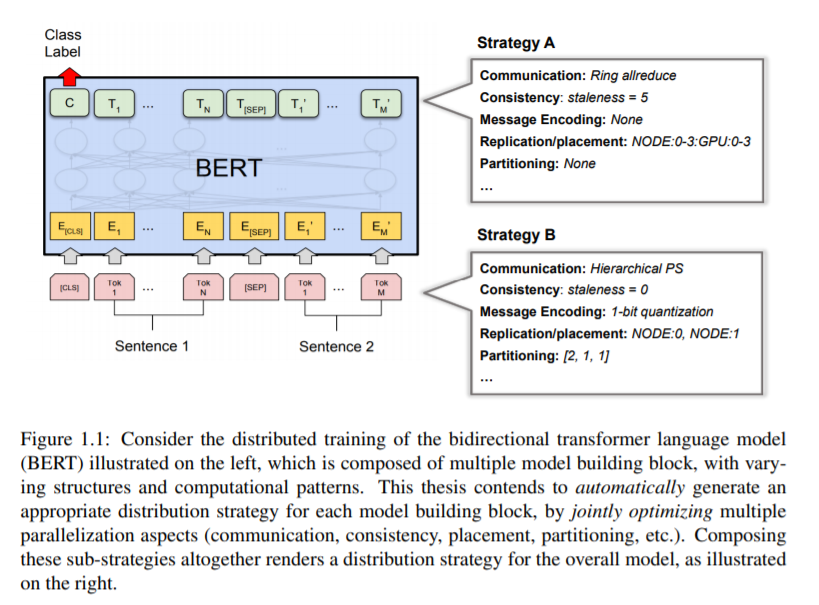
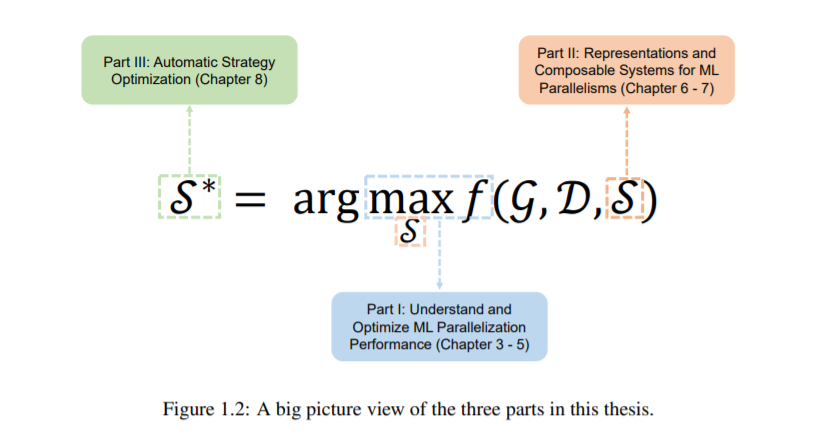
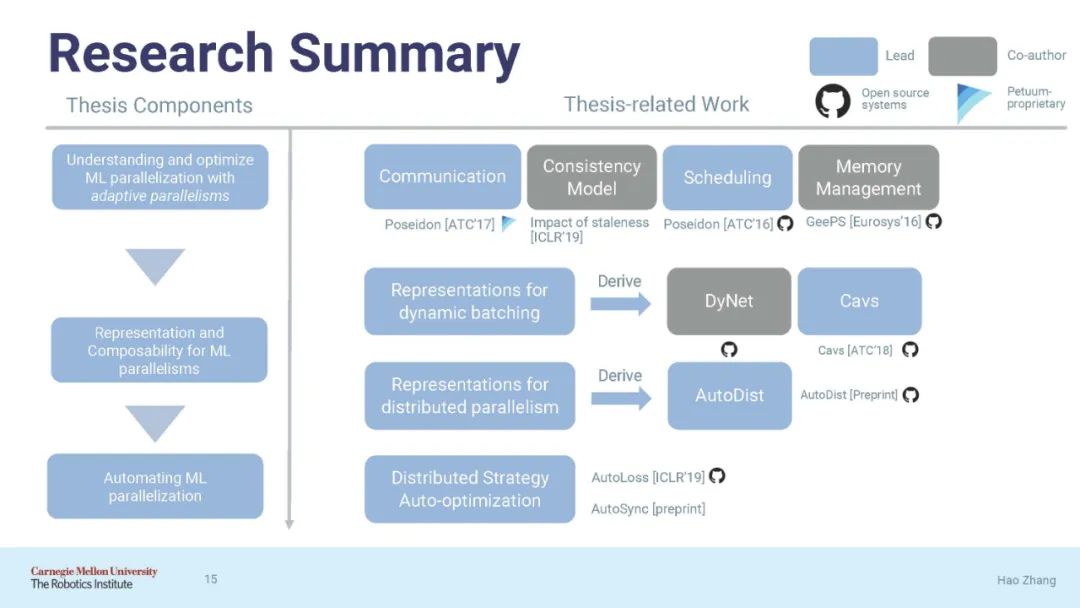
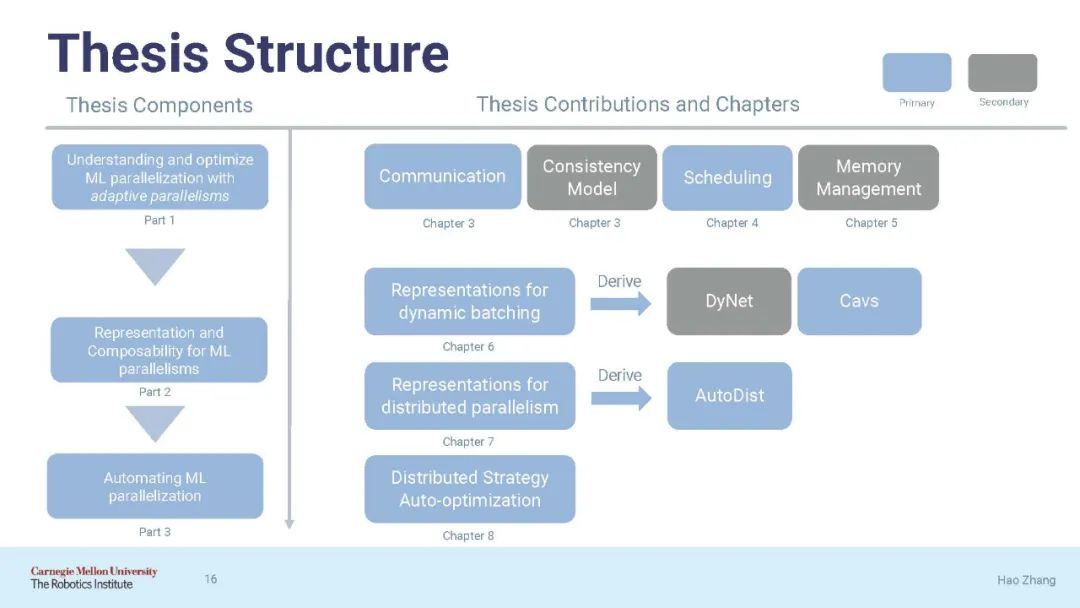
论文结构:
第一部分(第三章-第五章):通过自适应并行来理解和优化并行ML在各个方面的性能;
第二部分(第六章-第七章):开发ML并行的统一表示和可组合系统;
第三部分(第八章):自动化ML并行化
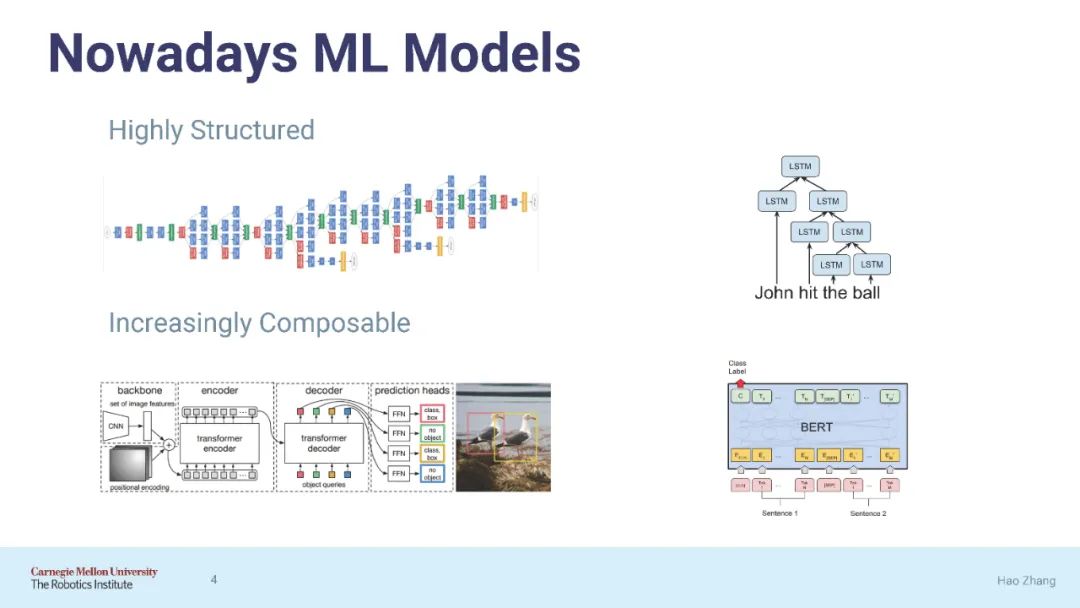

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PML229” 可以获取《【CMU-zhanghao博士论文】并行机器学习:自适应、可组合与自动化,附229页pdf与答辩视频》专知下载链接索引




