颜水成发了个「简单到令人尴尬」的视觉模型,证明Transformer威力源自其整体架构
梦晨 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Transformer做视觉取得巨大成功,各大变体频频刷榜,其中谁是最强?
早期人们认为是其中的注意力机制贡献最大,对注意力模块做了很多改进。
后续研究又发现不用注意力换成Spatial MLP效果也很好,甚至使用傅立叶变换模块也能保留97%的性能。
争议之下,颜水成团队的最新论文给出一个不同观点:
其实这些具体模块并不重要,Transformer的成功来自其整体架构。

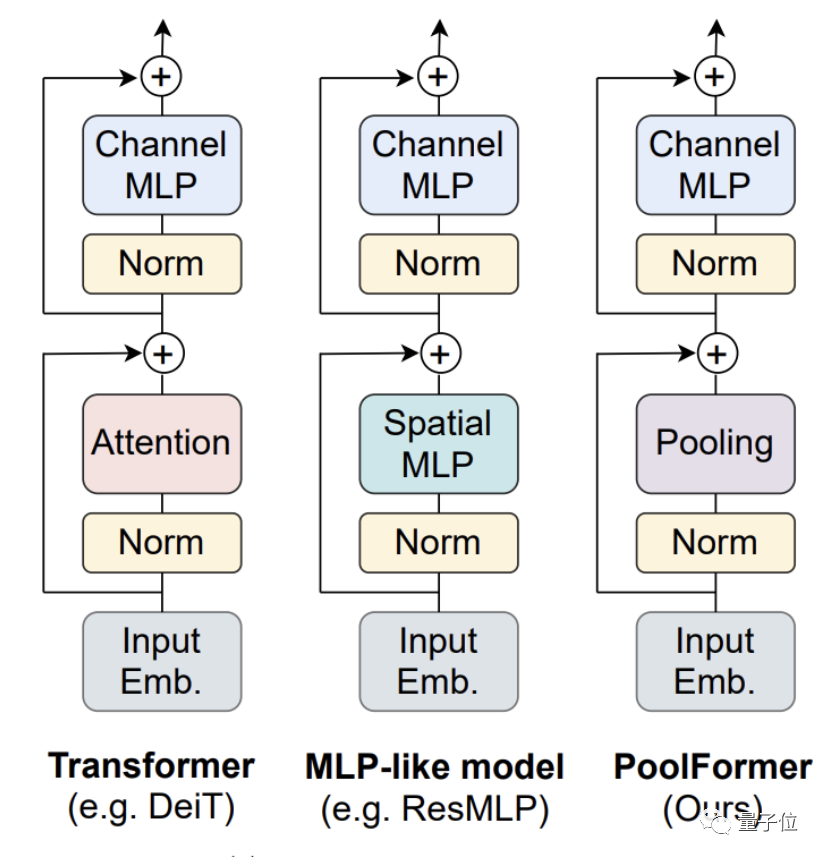
他们把Transformer中的注意力模块替换成了简单的空间池化算子,新模型命名为PoolFormer。
这里原文的说法很有意思,“简单到让人尴尬”……

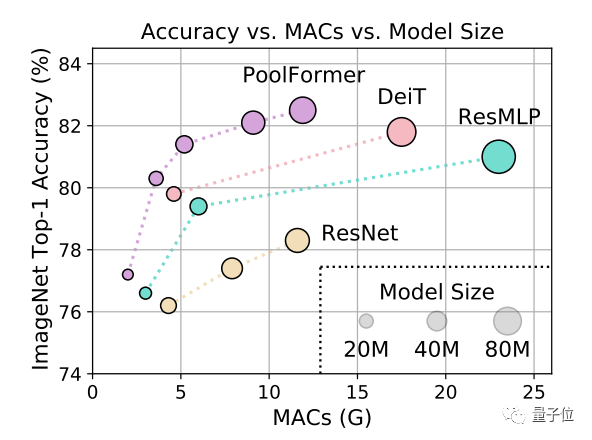
测试结果上,PoolFormer在ImageNet-1K上获得了82.1%的top-1精度。
(PyTorch版代码已随论文一起发布在GitHub上,地址可在这篇推文末尾处获取。)
同等参数规模下,简单池化模型超过了一些经过调优的使用注意力(如DeiT)或MLP模块(如ResMLP)的模型。
这个结果让一些围观的CVer直接惊掉下巴:

太好奇了,模型简单到什么样才能令人尴尬?
PoolFormer
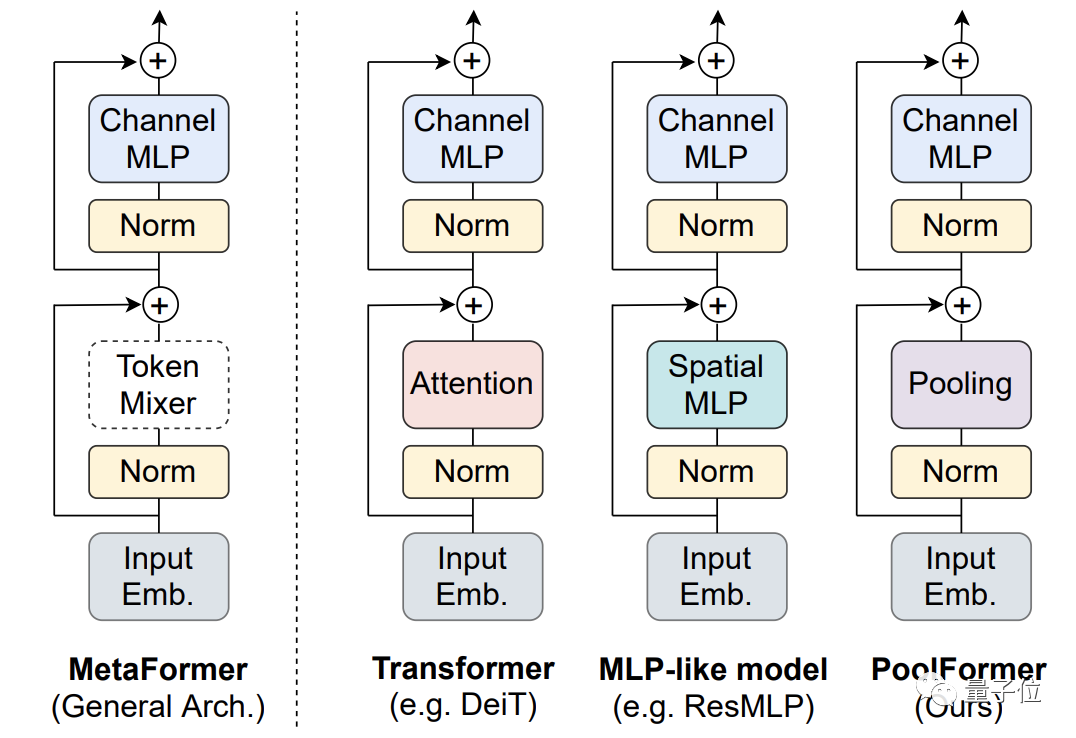
整体结构与其他模型类似,PoolFormer只是把token mixer部分换了一下。
因为主要验证视觉任务,所以假设输入数据的格式为通道优先,池化算子描述如下:
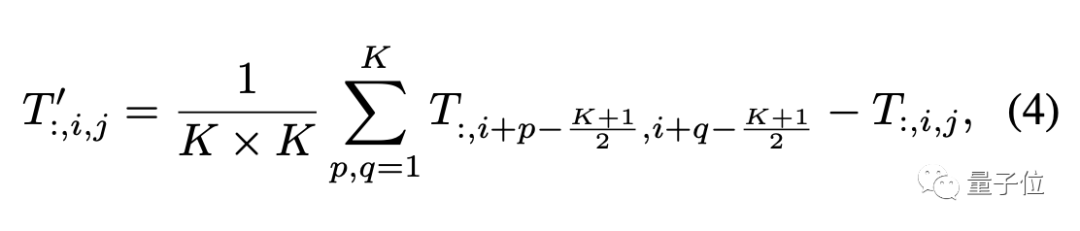
PyTorch风格的伪代码大概是这样:

池化算子的复杂度比自注意力和Spatial MLP要小,与要处理的序列长度呈线性关系。
其中也没有可学习的参数,所以可以采用类似传统CNN的分阶段方法来充分发挥性能,这次的模型分了4个阶段。
假设总共有L个PoolFormer块,那么4个阶段分配成L/6、L/6、L/2、L/6个。
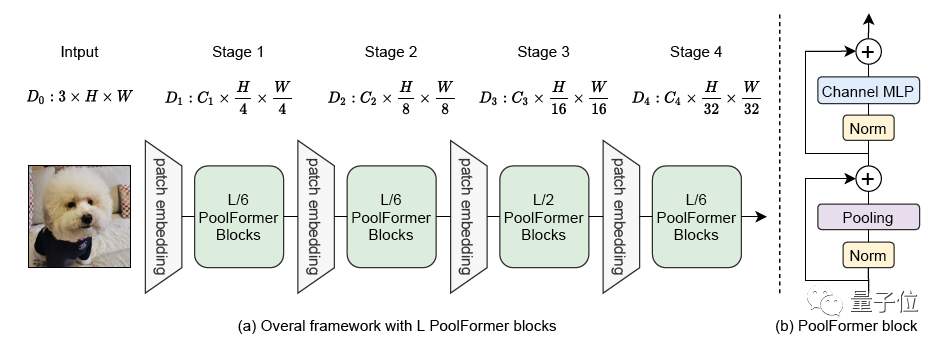
每个阶段的具体参数如下:
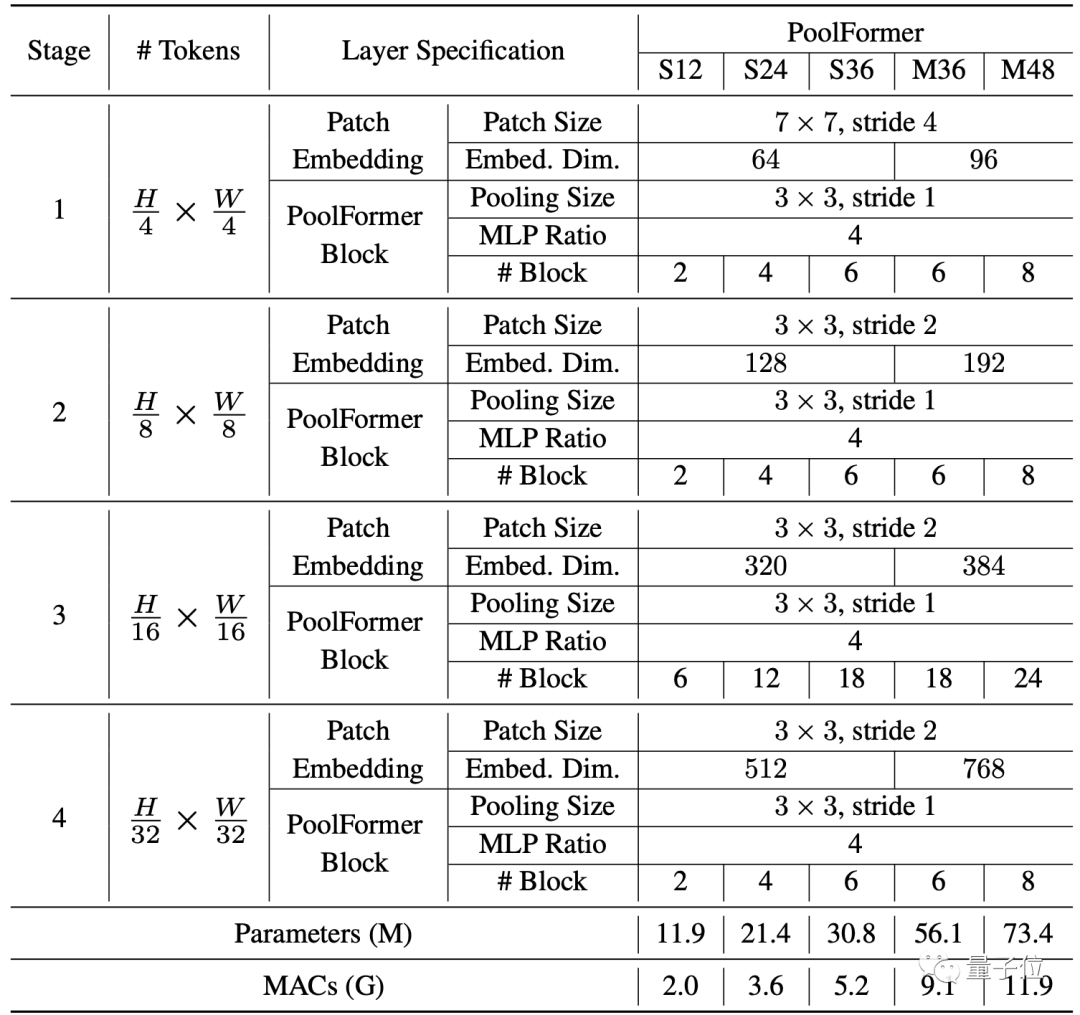
PoolFormer基本情况介绍完毕,下面开始与其他模型做性能对比。
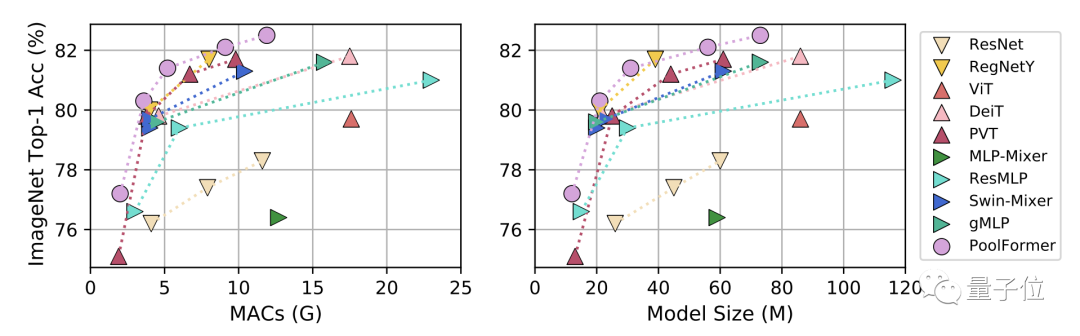
首先是图像分类任务,对比模型分为三类:
CNN模型ResNet和RegNetY
使用注意力模块的ViT、DeiT和PVT
使用Spatial MLP的MLP-Mixer、ResMLP、Swin-Mixer和gMLP
在ImageNet-1K上,无论是按累计乘加操作数(MACs)还是按参数规模为标准,PoolFormer性能都超过了同等规模的其他模型。
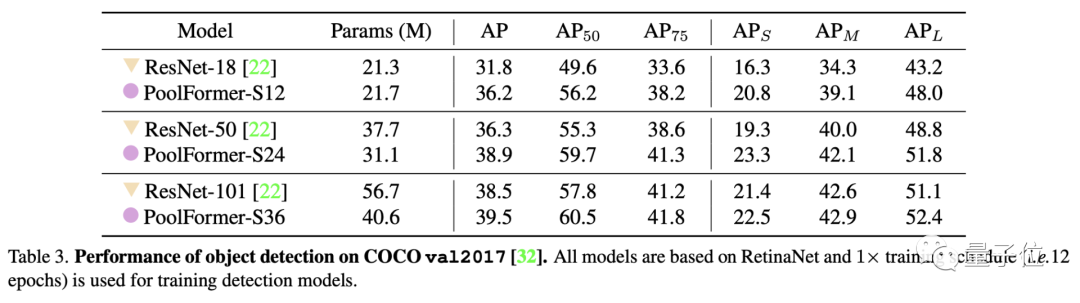
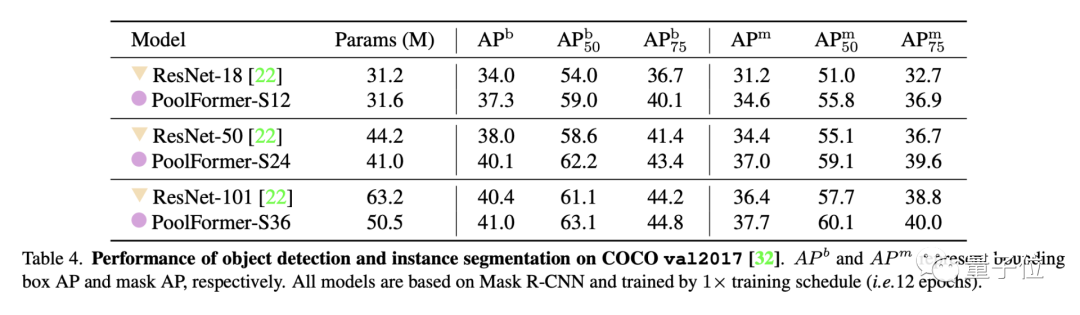
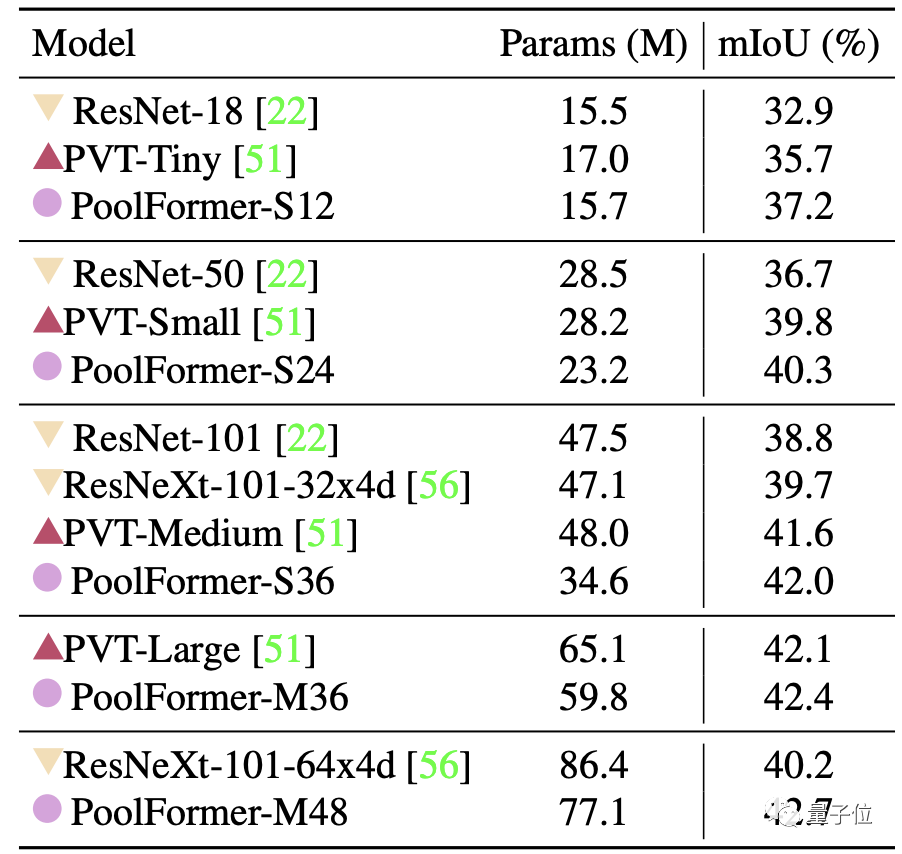
目标检测和实例分割任务上用了COCO数据集,两项任务中PoolFormer都以更少的参数取得比ResNet更高的性能。
最后是ADE20K语义分割任务,PoolFormer的表现也超过了ResNet、ResNeXt和PVT。
消融实验
上面可以看出,几大视觉任务上PoolFormer都取得了有竞争力的成绩。
不过这还不足以支撑这篇论文开头提出的那个观点。
到底是整体架构重要?还是说PoolFormer中的池化模块刚好是一种简单却有效的Token Mixer?
团队的验证方法是把池化模块直接替换成恒等映射(Identity Mapping)。
结果令人惊讶,替换后在ImageNet-1K上也保留了74.3%的Top-1精度。
在此基础上无论是改变池化核尺寸、归一化方法、激活函数影响都不大。
最重要的是,在4个阶段中把注意力和空间全连接层等机制混合起来用性能也不会下降。
其中特别观察到,前两阶段用池化后两阶段用注意力这种组合表现突出。
这样的配置下稍微增加一下规模精度就可达到81%,作为对比的ResMLP-B24模型达到相同性能需要7倍的参数规模和8.5倍的累计乘加操作。
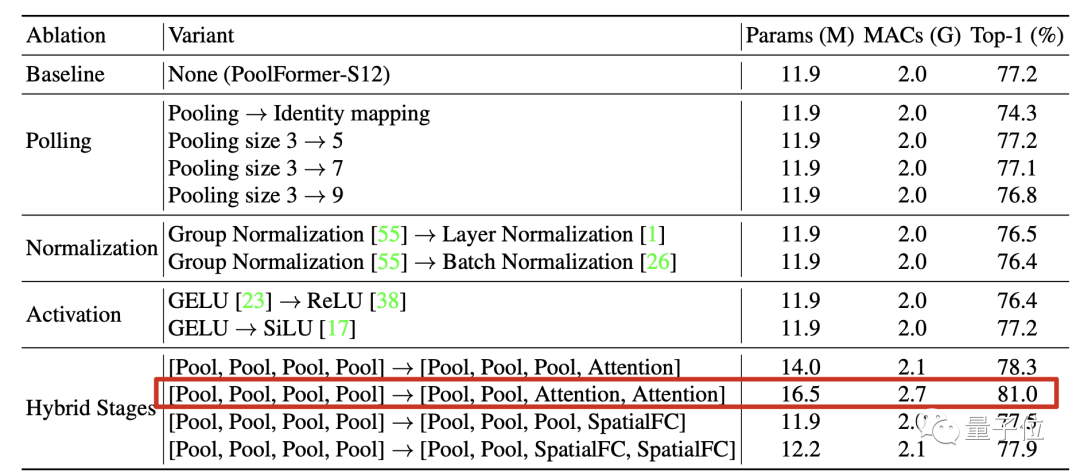
最终,消融实验结果说明Transformer中具体到token mixer这个部分,具体用了哪种方法并不关键。
不增加模型规模的情况下,网络的整体结构才是对性能提升最重要的。
这样的整体结构被团队提炼出来,命名为MetaFormer。
NLP上还会成立吗?
这项研究由颜水成领导的Sea AI Lab和来自新加坡国立大学的成员共同完成。

△颜水成
论文的最后,团队表示下一步研究方向是在更多场景下继续验证,如自监督学习和迁移学习。
除了视觉任务,也要看看在NLP任务上结论是否也成立。
另外发这篇论文还有一个目的:
呼吁大家把研究的重点放在优化模型的基础结构,而不是在具体模块上花太多精力去打磨。

论文地址:
https://arxiv.org/abs/2111.11418
GitHub仓库:
https://github.com/sail-sg/poolformer
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
直播免费报名!
与AI大咖一起预见智能科技新未来
量子位「MEET2022智能未来大会」将于11.30日全程直播,李开复博士、张亚勤教授、IBM大中华区CTO谢东、百度集团副总裁吴甜、京东集团副总裁何晓冬、商汤科技联创杨帆、小冰公司CEO李笛 等嘉宾邀你参会、一起预见智能科技新未来!
扫码可预约直播or加入大会交流群↓↓ 入群还可抽取惊喜礼品&现金红包哦





<< 左右滑动查看更多 >>

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」「点赞」和「在看」
科技前沿进展日日相见 ~



