ECCV 2020 | 清华&旷视提出:在移动设备上进行深度Raw图像去噪
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文作者:oneTaken
https://zhuanlan.zhihu.com/p/262661328
本文已由原作者授权,不得擅自二次转载
这是篇来自旷视的论文,主要包括两个部分,提出了一种k-sigma的变换,将高斯泊松的噪声模型去掉了ISO这个变量的约束;二是提出了一种手机上性能更快的模型,某种程度上也是因为k-sigma变换降低了数据集的复杂度,因此可以使用一个性能更快的模型。
整篇论文的篇幅比较长,除去3页论文引用,有14页的内容,消融实验做得比较充分。然而与其他论文比较的部分却很少,只有两个方面的比较,一个是最终成片的效果,是与default ISP的降噪效果对比,细节多了不少,从论文中看,这里的default ISP应该是OPPO Reno 10X手机中原有的,应该也是高通的一套依据Reno 10X手机Tuning出来的一套ISP;另一个是模型FLOPS的比较,是与他们自己NTIRE 2019 raw denoise workshop中使用的模型对比。不知道是不是因为测试集是自己采集的原因,都没有使用其他的SOTA模型,如DnCNN或者RIDNet,来在他们自己相同的训练集上训练,再来进行对比。
目录
如何制作训练数据
如何设计网络模型
如何刻画数据关系
实验结果对比分析
总结
论文:Practical Deep Raw Image Denoising on Mobile Devices

https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/4571_ECCV_2020_paper.php
1. 如何制作训练数据
主要包括高斯泊松噪声模型描述、噪声参数标定、k-sigma变换的三个过程。
1.1 高斯泊松噪声模型
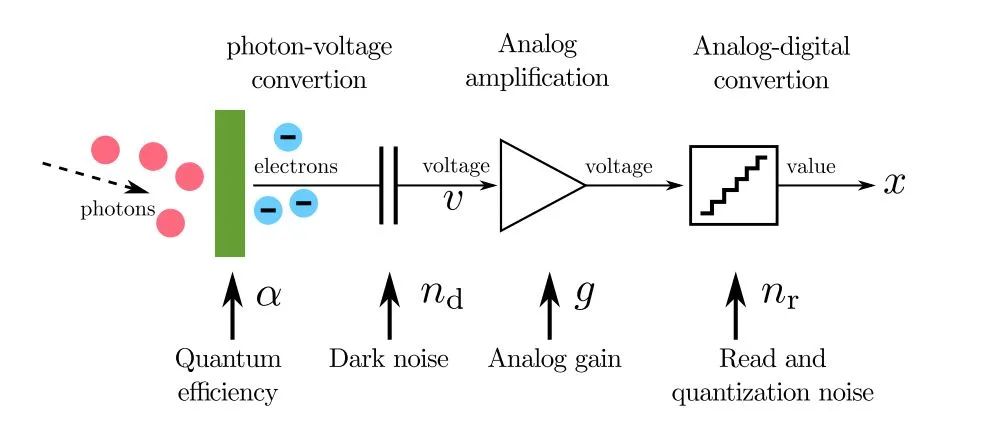
主要描述了CMOS Sensor成像过程中光子转换电子、电子转换电压、电压放大、模电转换、信号量化的几个主要步骤。

在理想情况下应该如公式(1)所示,预期打到像素区域的光子数量u*,经由转换效率alpha及模拟增益g两重作用之后,得到一个理想的像素强度值x*。然而,由于光子存在着波粒二象性,分布服从公式3,并且转换过程也会存在着噪声的影响,实际的CMOS成像过程为公式2,模拟增益g之前会存在暗电流,分布服从公式4的高斯分布,模拟增益之后的读出噪声分布服从公式5,这里将量化噪声也包含在读出噪声之中了。

联合公式(1)(3)(4)(5)代入公式(2)之后,可以得到公式(6)。

使用公式(7)、(9)对公式(6进行简化,可得到公式9。由于alpha对于一个sensor而言是固定的,g依据ISO变化,sigmad与sigma_r均与信号强度不相关,因为k与sigma均是仅与g相关的变量。
1.2 噪声参数标定
由公式(9)可以得出x的均值与方差。

因此只需要测出x的均值其方差的线性关系图,即可依据其斜率k和截距sigma。实际上这里的k是一个关于g的常量,g乘以100即为ISO,也可以直接算出k。
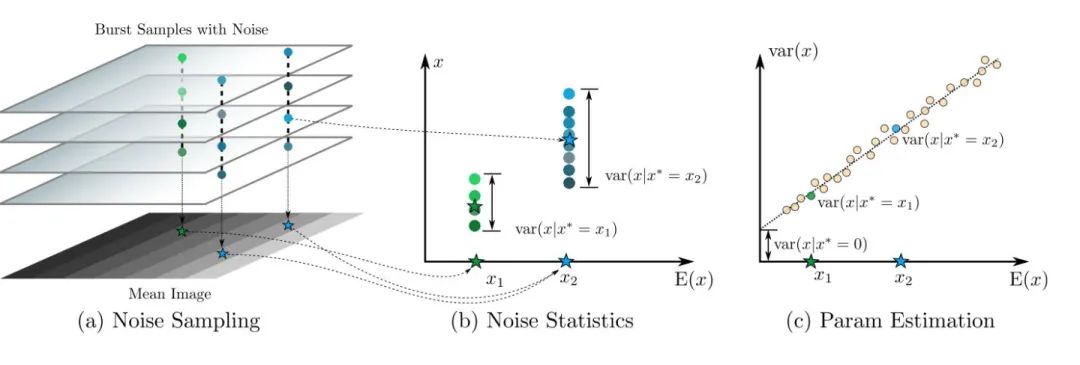
这里还是通过拍多帧灰阶图卡的方式来标定,灰阶图卡的像素强度值尽可能的覆盖0~255之间,如上图(a)所示;计算出每一个像素点在多帧上的均值与方差,形成数据对,如上图(b)所示;画出不同像素强度的均值-方差点对,即可使用线性回归拟合出直线图,得到斜率k与截距sigma,如上图(c)所示。
1.3 k-sigma变换
在实际场景中的ISO变换范围比较广,为了覆盖这种场景,需要在训练过程中使用不同ISO的数据来进行训练,ISO越高,噪声越强,降噪难度也越强。在同时使用不同的ISO来进行训练时,可能会遇到难易样本的问题,导致部分噪声强度下的降噪力度不够好。
这里借鉴VST(variance stabilizing transformations )的思想,使用k-sigma变换,去掉数据的噪声强度对于ISO的依赖,某种程度上算是降低了训练数据的难度。

将实际得到的像素强度x,依据标注得到的k与sigma进行上图(7)的变换之后,可以得到一个只依赖于x*分布的数据。x对应于实际得到的、带有噪声的noisy的数据,x*对应于理想的、没有噪声的clean的数据,这样可以通过模型来对x进行降噪之后,再进行k-sigma逆变换得到干净的数据。
2. 如何设计网络模型
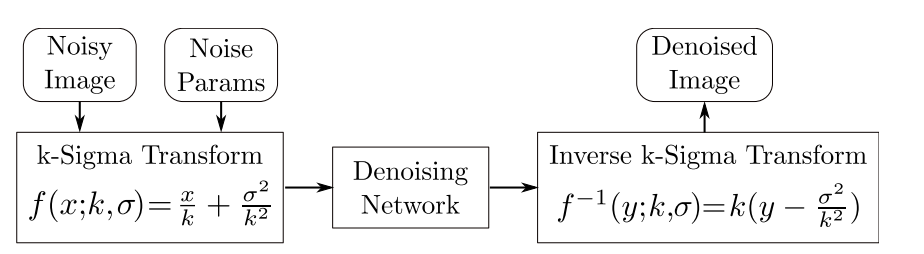
模型降噪是属于k-sigma变换及降噪后结果的k-sigma逆变换的中间部分。
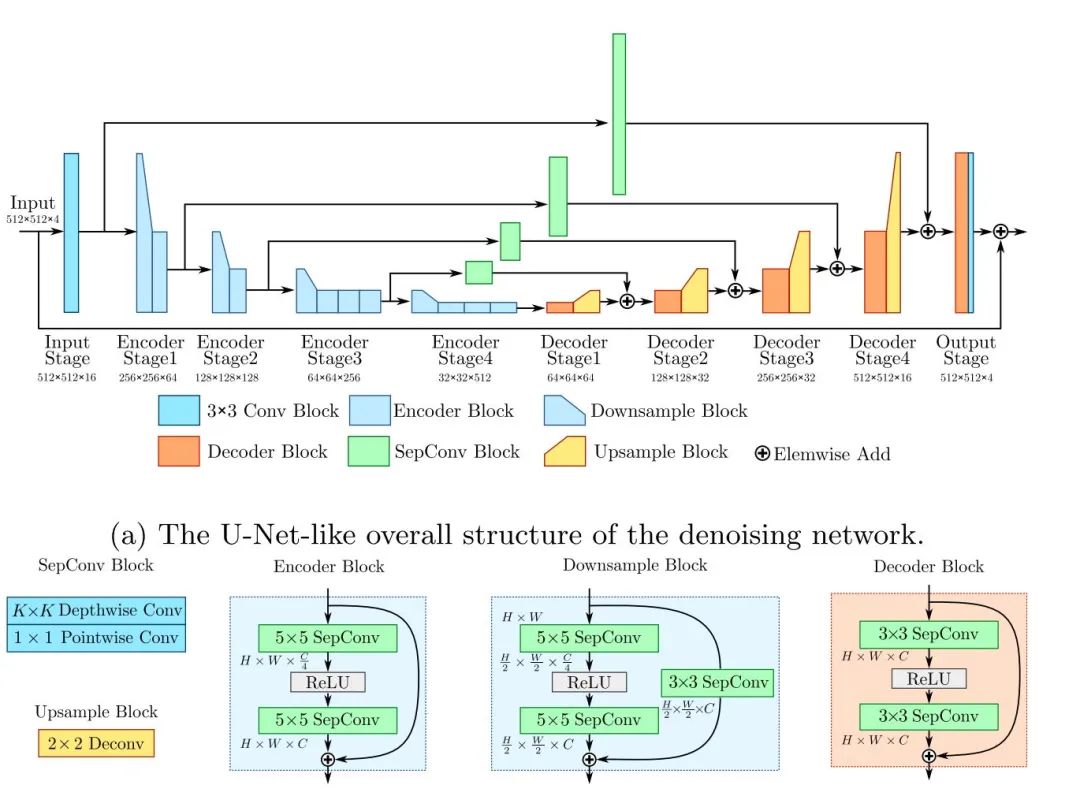
实际上也是一个unet 结构。文中提到这是一个为手机端设计的模型架构,主要有:
1. 使用separable conv;
2. 使用5x5来增大感受野,降低模型深度;
3. 使用stride 为2的卷积来进行下采样;使用2x2的deconv来进行上采样;
4. 使用3x3的separable conv来进行skip connection时的通道匹配;
3. 如何刻画数据关系
这里的损失函数只是使用了Raw域上的L1损失函数。
4. 实验结果对比分析
4.1 训练细节
使用SID中的长曝光的Raw数据来作为干净的数据,采用的Sony α7s II 的RGGB的bayer格式,并没有采用Fujifilm X-T2 camera的3x3的Raw数据。然后使用我上面自己写的公式(9)中的高斯泊松的噪声模型来生成训练数据对。
这里crop 1024x1024的数据来进行训练,采用的数据增强方法有bayer aug,亮度和对比度的随机调整来进行数据增强,并没有进行翻转和旋转。还不清楚这里的亮度和对比度是怎么做的。
4.2 噪声标定细节
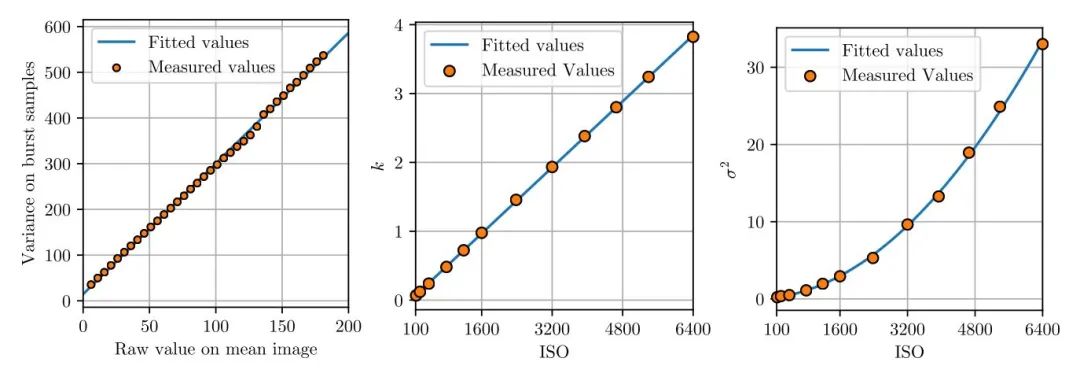
这里使用了android camera2 api来控制ISO和曝光时间,连拍64帧Raw数据来计算均值与方差,可以看到直线的拟合还是比较准的。
4.3 测试集的采集
由于是针对于具体的camera sensor,并没有采用SIDD这种数据集来进行测试,而是室内采集EV的方式来构建测试集。ISO增加一倍,曝光时间减少一倍。
We set 5 exposure combinations at each scene and luminance, which are ISO-800@160ms, ISO-1600@80ms, ISO- 3200@40ms, ISO-4800@30ms and ISO-6400@20ms.

这里裁剪出了一些ROI的区域来进行计算,复杂度感觉还是够的。
然后使用一个简单的ISP来进行可视化的比较,包括白平衡、demosaic、颜色矫正、gamma矫正。并没有使用SIDD提供的现有的ISP来进行可视化。
4.4 参数量比较
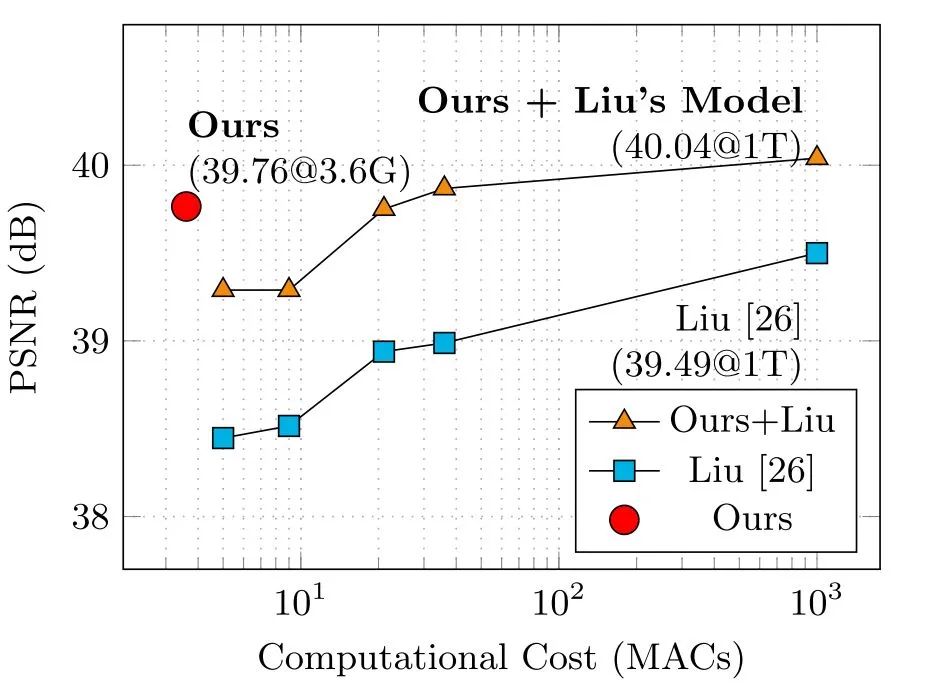

这里比较的架构是他们NTIRE 2019 workshop的架构,最终百万像素在高通855平台上的计算时间为70ms。
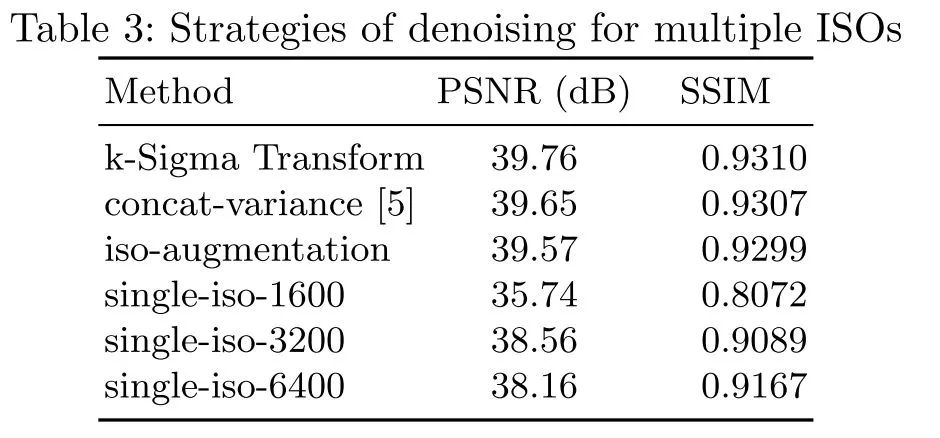
4.5 k-sigma有效性对比
如下图所示,可以看到使用单个的ISO的数据来进行训练时,泛化效果明显差于使用不同的ISO来进行训练的结果,也差于显示使用noise map的结果,使用k-sigma变换之后的盲降噪效果最好。
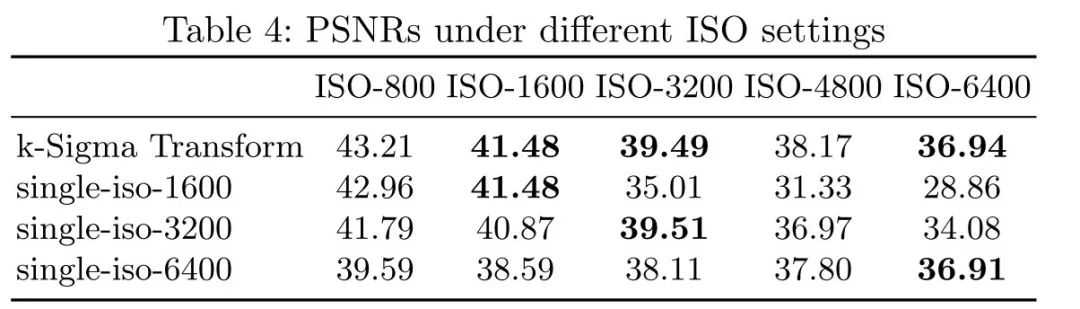
如下图所示,可以看到虽然训练与预测时的ISO一致时的效果最好,也依然与使用k-sigma变换的效果相当。
5. 总结
这篇主要是包括两个部分,一是提出了一种k-sigma变换的方法,来将高斯泊松的噪声模型数据去掉了对于ISO的约束,降低了训练数据的复杂度;二是提出了一种为移动端设计的性能较快的模型,也有着充分的对比实验来验证k-sigma变换的有效性,甚至比显示利用sigma map的效果还要好。
下载1:动手学深度学习
在CVer公众号后台回复:动手学深度学习,即可下载547页《动手学深度学习》电子书和源码。该书是面向中文读者的能运行、可讨论的深度学习教科书,它将文字、公式、图像、代码和运行结果结合在一起。本书将全面介绍深度学习从模型构造到模型训练,以及它们在计算机视觉和自然语言处理中的应用。

下载2:CVPR / ECCV 2020开源代码
在CVer公众号后台回复:CVPR2020,即可下载CVPR 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-去噪交流群成立
扫码添加CVer助手,可申请加入CVer-去噪 微信交流群,目前已满100+人,旨在交流去噪等写事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如去噪+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!


