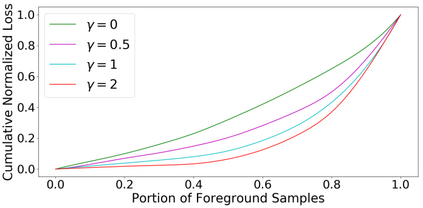
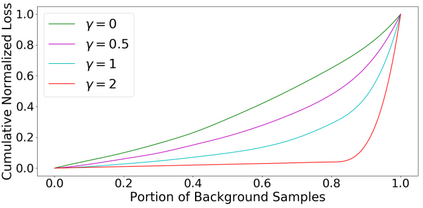
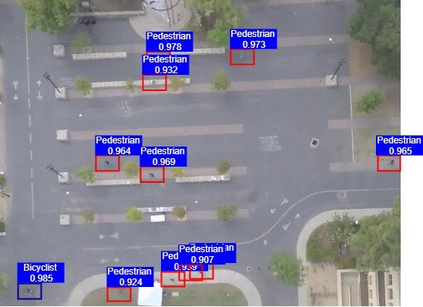
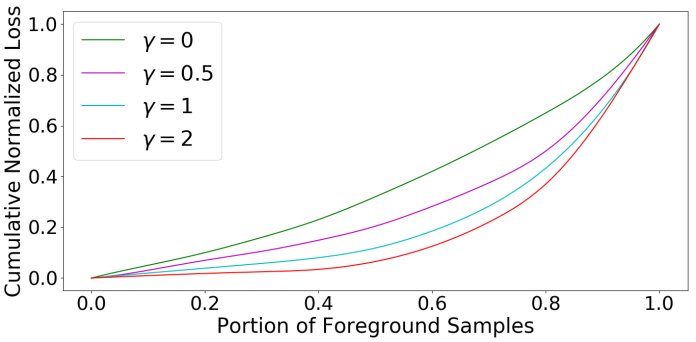
The ever-growing interest witnessed in the acquisition and development of unmanned aerial vehicles (UAVs), commonly known as drones in the past few years, has brought generation of a very promising and effective technology. Because of their characteristic of small size and fast deployment, UAVs have shown their effectiveness in collecting data over unreachable areas and restricted coverage zones. Moreover, their flexible-defined capacity enables them to collect information with a very high level of detail, leading to high resolution images. UAVs mainly served in military scenario. However, in the last decade, they have being broadly adopted in civilian applications as well. The task of aerial surveillance and situation awareness is usually completed by integrating intelligence, surveillance, observation, and navigation systems, all interacting in the same operational framework. To build this capability, UAV's are well suited tools that can be equipped with a wide variety of sensors, such as cameras or radars. Deep learning has been widely recognized as a prominent approach in different computer vision applications. Specifically, one-stage object detector and two-stage object detector are regarded as the most important two groups of Convolutional Neural Network based object detection methods. One-stage object detector could usually outperform two-stage object detector in speed; however, it normally trails in detection accuracy, compared with two-stage object detectors. In this study, focal loss based RetinaNet, which works as one-stage object detector, is utilized to be able to well match the speed of regular one-stage detectors and also defeat two-stage detectors in accuracy, for UAV based object detection. State-of-the-art performance result has been showed on the UAV captured image dataset-Stanford Drone Dataset (SDD).
翻译:过去几年来,无人驾驶航空器(无人驾驶航空器)通常被称为无人驾驶航空器,对获取和研制无人驾驶航空器(无人驾驶航空器)的兴趣日益浓厚,因此产生了非常有希望和有效的技术。无人驾驶航空器由于其规模小和部署迅速的特点,在收集无法到达的地区和限制覆盖范围的数据方面表现出了效力;此外,其灵活界定的能力使无人驾驶航空器能够非常详细地收集信息,导致高分辨率图像。无人驾驶航空器主要用于军事情景。但在过去十年中,民用应用也广泛采用无人驾驶飞行器。空中监视和情况意识的任务通常通过综合情报、监测、观察和导航系统来完成,所有这些系统都是在同一操作框架内相互作用的。为了建立这一能力,无人驾驶航空器非常适合各种传感器,如照相机或雷达等。深层次的学习被公认为是不同计算机视觉应用中的一种突出的方法。具体地说,一级物体探测器和两阶段物体探测器检测组最重要的两组。 定期的物体探测轨道探测器通常以两台级探测器为级探测器,在一级探测器的轨道定位中进行一次探测,通常以两台级探测器为一级探测器,在一级探测器为一级探测器的测得。